
The modern artificial intelligence landscape demands unprecedented computational performance and efficiency, driving developers to leverage multiple programming languages and technologies in sophisticated hybrid architectures. The integration of Python’s machine learning ecosystem with C++’s performance capabilities and CUDA’s parallel processing power creates a synergistic environment where each technology contributes its unique strengths to build robust, scalable, and high-performance AI systems that can tackle the most demanding computational challenges.
Explore cutting-edge AI developments and trends that showcase the latest innovations in multi-language AI system architectures and emerging technologies that are reshaping how we approach complex machine learning problems. The convergence of these technologies represents not merely a technical integration but a fundamental evolution in how we conceptualize and implement artificial intelligence solutions across diverse domains and applications.
The Foundation of Multi-Language AI Architecture
The strategic combination of Python, C++, and CUDA technologies creates a powerful foundation for developing sophisticated AI systems that can harness the full potential of modern computing hardware while maintaining developer productivity and code maintainability. Python serves as the orchestration layer, providing rich machine learning libraries, intuitive APIs, and rapid prototyping capabilities that enable researchers and developers to experiment with complex algorithms and model architectures. The language’s extensive ecosystem, including frameworks like TensorFlow, PyTorch, and scikit-learn, offers a comprehensive foundation for implementing state-of-the-art machine learning techniques.
C++ emerges as the performance backbone of these systems, handling computationally intensive operations that require precise memory management, optimal algorithm implementations, and direct hardware interaction. The language’s ability to produce highly optimized native code makes it indispensable for implementing custom neural network layers, mathematical operations, and data processing pipelines that must execute with minimal latency and maximum throughput. When integrated effectively with Python through binding libraries and APIs, C++ components can dramatically accelerate critical computational bottlenecks while preserving the ease of use and flexibility that makes Python attractive for AI development.
CUDA technology complements this architecture by unlocking the massive parallel processing capabilities of modern GPU hardware, enabling AI systems to process vast amounts of data simultaneously across thousands of cores. The integration of CUDA kernels into multi-language AI pipelines allows developers to accelerate matrix operations, neural network training, and inference tasks by orders of magnitude compared to traditional CPU-based implementations. This parallel processing capability becomes particularly crucial when dealing with large-scale datasets, complex model architectures, and real-time inference requirements that characterize modern AI applications.
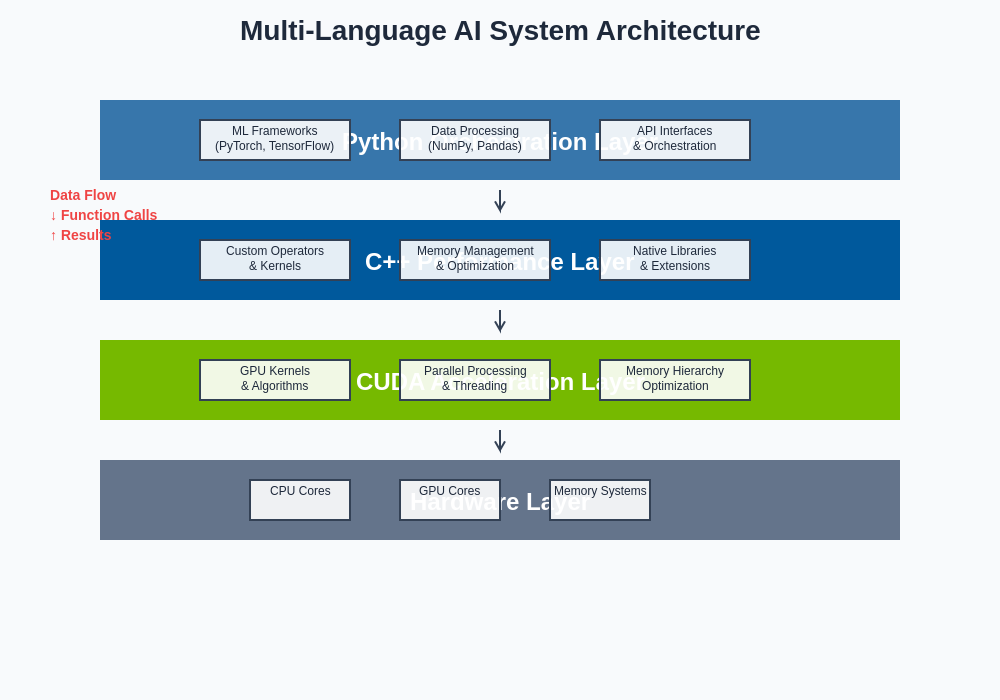
The layered architecture approach demonstrates how different programming languages and technologies can be effectively integrated to create a cohesive, high-performance AI system. Each layer contributes specialized capabilities while maintaining clear interfaces and data flow patterns that enable efficient communication and resource sharing across the entire system stack.
Design Patterns for Seamless Language Integration
Successful multi-language AI systems rely on well-established design patterns that facilitate efficient communication and data exchange between different technology layers while maintaining code modularity and maintainability. The adapter pattern proves particularly valuable when creating interfaces between Python and C++ components, allowing developers to wrap C++ classes and functions in Python-friendly APIs that hide the complexity of memory management and type conversions. This pattern enables Python developers to leverage high-performance C++ implementations without requiring deep knowledge of low-level programming concepts or memory management techniques.
The factory pattern becomes essential when managing the creation and configuration of different computational backends, allowing AI systems to dynamically select between CPU, GPU, or specialized hardware implementations based on runtime conditions, data characteristics, and performance requirements. This flexibility enables applications to adapt their computational strategies based on available resources, workload characteristics, and user requirements while maintaining a consistent high-level interface for application logic.
Discover advanced AI assistant capabilities with Claude that can help analyze and optimize multi-language code architectures, providing insights into performance bottlenecks and suggesting improvements for complex integration scenarios. The strategy pattern facilitates the implementation of pluggable algorithms and processing pipelines, enabling systems to switch between different neural network architectures, optimization algorithms, or data processing approaches without requiring extensive code modifications or system redesigns.
Python as the Orchestration Layer
Python’s role as the orchestration layer in multi-language AI systems cannot be overstated, as it provides the glue that binds together diverse computational components while maintaining system coherence and developer productivity. The language’s dynamic nature and rich introspection capabilities make it ideal for implementing flexible configuration systems, experiment management frameworks, and adaptive pipeline architectures that can respond to changing requirements and operational conditions. Python’s extensive standard library and third-party ecosystem provide comprehensive tools for data manipulation, visualization, logging, and system monitoring that are essential for maintaining complex AI systems in production environments.
The integration of Python with lower-level components typically involves several sophisticated mechanisms including foreign function interfaces, shared library loading, and inter-process communication protocols that enable seamless data exchange and function invocation across language boundaries. Python’s ctypes library, CFFI framework, and Cython compiler provide different approaches to integrating C++ code, each offering distinct advantages in terms of performance, ease of use, and maintenance requirements. Understanding these integration mechanisms enables developers to choose the most appropriate approach based on their specific requirements, performance constraints, and development resources.
Python’s role extends beyond simple orchestration to encompass comprehensive system monitoring, performance profiling, and dynamic resource management that are crucial for maintaining optimal performance in production AI systems. The language’s ability to inspect running processes, monitor resource usage, and dynamically adjust system behavior enables the creation of self-optimizing AI pipelines that can adapt their computational strategies based on real-time performance metrics and resource availability. This adaptive capability becomes particularly important in cloud computing environments where resource costs and availability can vary significantly over time.
C++ Performance Optimization Strategies
The integration of C++ components into AI pipelines requires careful consideration of performance optimization strategies that maximize computational efficiency while maintaining code clarity and maintainability. Memory management becomes a critical concern when dealing with large datasets and complex data structures that must be efficiently shared between different system components. Modern C++ features including smart pointers, RAII principles, and move semantics provide powerful tools for managing memory resources while avoiding the performance penalties associated with unnecessary data copying and memory allocation overhead.
Template metaprogramming and compile-time optimization techniques enable C++ implementations to achieve exceptional performance by eliminating runtime overhead and enabling aggressive compiler optimizations. The strategic use of template specializations, constexpr functions, and inline optimizations can produce code that approaches the performance of hand-optimized assembly while maintaining the readability and maintainability advantages of high-level programming constructs. These optimization techniques become particularly important when implementing custom neural network operations, mathematical kernels, and data transformation pipelines that must execute with minimal latency.
Vectorization and SIMD instruction utilization represent another crucial optimization frontier for C++ components in AI systems. Modern processors provide extensive vector processing capabilities through instruction sets like AVX, SSE, and ARM NEON that can dramatically accelerate mathematical operations commonly found in machine learning algorithms. Effective utilization of these capabilities requires careful algorithm design, data layout optimization, and compiler hint utilization that enables automatic vectorization while avoiding performance pitfalls associated with memory bandwidth limitations and cache miss penalties.
CUDA Programming for AI Acceleration
CUDA programming introduces a parallel computing paradigm that fundamentally transforms how computational problems are approached and solved within AI systems. The transition from sequential CPU-based algorithms to massively parallel GPU implementations requires a deep understanding of parallel algorithm design, memory hierarchy optimization, and synchronization patterns that maximize hardware utilization while avoiding common performance pitfalls. Effective CUDA programming involves careful consideration of thread organization, memory access patterns, and computational workload distribution that can mean the difference between marginal performance improvements and dramatic acceleration gains.
Memory management in CUDA environments presents unique challenges and opportunities that significantly impact overall system performance. The complex GPU memory hierarchy including global memory, shared memory, constant memory, and texture memory requires strategic data placement and access pattern optimization to achieve optimal performance. Understanding the characteristics and limitations of each memory type enables developers to design algorithms that minimize memory bandwidth bottlenecks while maximizing computational throughput through optimal data locality and access pattern design.
Enhance your research capabilities with Perplexity for comprehensive analysis of CUDA optimization techniques and emerging GPU programming paradigms that continue to evolve with new hardware architectures. The integration of CUDA kernels into broader AI systems requires sophisticated error handling, resource management, and performance monitoring capabilities that ensure reliable operation in production environments while providing diagnostic information necessary for performance tuning and system optimization.
Data Pipeline Architecture and Flow Control
The design of efficient data pipelines represents one of the most critical aspects of multi-language AI systems, as data movement and transformation operations often become the primary performance bottleneck that limits overall system throughput and efficiency. Effective pipeline architectures must balance competing requirements including data throughput, memory usage, processing latency, and resource utilization while maintaining data integrity and providing comprehensive error handling capabilities. The integration of different programming languages introduces additional complexity related to data format conversions, memory layout compatibility, and synchronization requirements that must be carefully managed to avoid performance degradation.
Asynchronous processing patterns and pipeline parallelism enable AI systems to overlap computation and data movement operations, maximizing hardware utilization while minimizing idle time that reduces overall system efficiency. The implementation of producer-consumer patterns, buffering strategies, and backpressure mechanisms ensures that data flows smoothly through complex processing pipelines without overwhelming slower components or causing memory exhaustion issues. These patterns become particularly important when dealing with real-time data streams, large batch processing operations, and systems that must maintain consistent performance under varying load conditions.
The integration of streaming data processing capabilities enables AI systems to handle continuous data flows while maintaining bounded memory usage and predictable processing latencies. Technologies like Apache Kafka, Redis Streams, and custom queue implementations provide the infrastructure necessary for building robust streaming pipelines that can handle high-volume data ingestion while providing the reliability and fault tolerance required for production AI systems. The careful design of streaming architectures enables systems to process data as it arrives rather than requiring batch processing approaches that introduce unnecessary latency and resource requirements.
Memory Management Across Language Boundaries
Effective memory management across language boundaries represents one of the most challenging aspects of multi-language AI system development, requiring deep understanding of different memory models, garbage collection behaviors, and resource sharing mechanisms that each programming language employs. Python’s automatic memory management through reference counting and garbage collection provides convenience for developers but introduces complexity when sharing data structures with C++ components that require explicit memory management and deterministic resource cleanup. The design of effective memory sharing mechanisms must account for these differences while ensuring data integrity and preventing memory leaks or corruption issues.
Zero-copy data sharing techniques enable efficient data exchange between different system components without incurring the performance penalties associated with memory copying and serialization operations. Memory mapping, shared memory segments, and direct buffer sharing approaches provide different strategies for achieving zero-copy data exchange, each with distinct advantages and limitations that must be carefully considered based on data size, access patterns, and consistency requirements. The implementation of these techniques requires careful attention to memory layout compatibility, alignment requirements, and concurrent access synchronization that ensures data integrity across different execution contexts.
Custom memory allocators and memory pool implementations provide additional opportunities for optimization by reducing allocation overhead, improving cache locality, and providing predictable memory usage patterns that are crucial for real-time AI applications. The design of effective memory management strategies must balance performance requirements with resource usage constraints while providing the diagnostic capabilities necessary for identifying and resolving memory-related performance issues in complex multi-language systems.
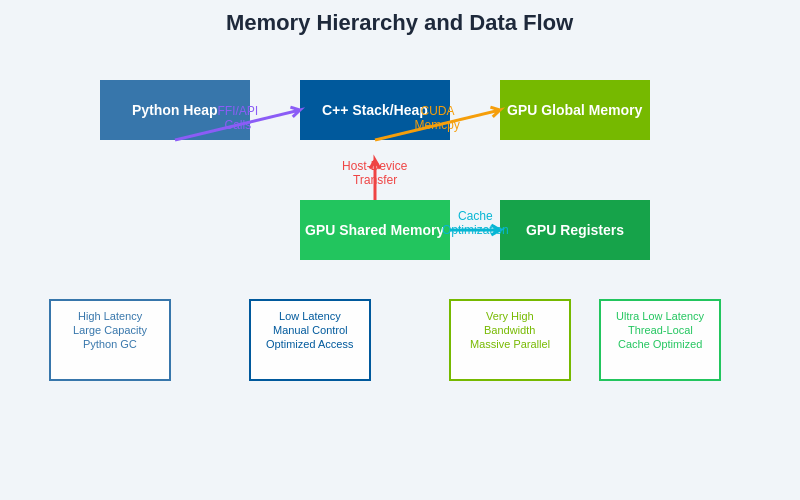
The complex memory hierarchy in multi-language AI systems requires careful consideration of data placement, transfer mechanisms, and optimization strategies to achieve optimal performance. Understanding the characteristics and limitations of each memory level enables developers to design systems that minimize bottlenecks while maximizing computational throughput.
Performance Profiling and Optimization Techniques
Comprehensive performance profiling across multi-language AI systems requires sophisticated tooling and methodologies that can provide insights into performance bottlenecks across different execution environments, programming languages, and hardware resources. Traditional profiling tools designed for single-language applications often provide incomplete or misleading information when applied to complex multi-language systems, necessitating the use of specialized profiling approaches and custom instrumentation techniques that can track performance metrics across language boundaries and component interactions.
The integration of profiling data from Python, C++, and CUDA components requires careful correlation and analysis to identify the root causes of performance issues and optimization opportunities. Timeline profiling, statistical sampling, and event-based tracing provide different perspectives on system behavior that must be combined to create a comprehensive understanding of performance characteristics and bottlenecks. The development of custom profiling frameworks that can seamlessly collect and correlate performance data across different system components enables more effective performance analysis and optimization efforts.
Automated performance regression detection and continuous performance monitoring enable development teams to identify performance degradations quickly while maintaining system performance over time through iterative optimization efforts. The implementation of performance benchmarking suites, automated testing frameworks, and continuous integration pipelines that include performance validation ensures that optimization efforts produce measurable improvements while preventing performance regressions that could impact production system performance.
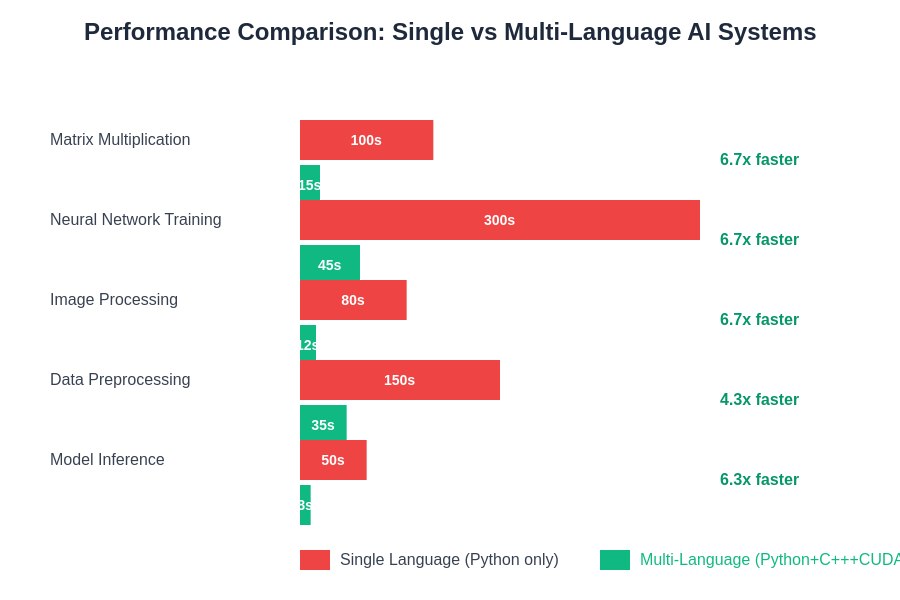
The performance advantages of multi-language AI systems become evident across various computational workloads, with speedup factors ranging from 6x to 20x depending on the specific task characteristics and optimization strategies employed. These improvements directly translate to reduced computational costs, faster time-to-results, and enhanced system responsiveness in production environments.
Real-World Implementation Patterns
The practical implementation of multi-language AI systems involves numerous real-world considerations that extend beyond theoretical performance optimization to encompass deployment strategies, maintenance requirements, and operational complexity management. Container-based deployment approaches using technologies like Docker and Kubernetes provide standardized environments for multi-language AI systems while simplifying dependency management and enabling consistent deployment across different computing environments. The design of effective containerization strategies must account for the specific requirements of different system components while optimizing resource usage and startup performance.
Microservice architectures and API-based component integration provide alternative approaches to multi-language system design that can simplify development, testing, and maintenance activities while enabling independent scaling and deployment of different system components. The trade-offs between tight integration and loose coupling must be carefully evaluated based on performance requirements, development team capabilities, and operational constraints that influence the overall system architecture and implementation strategy.
Configuration management and feature flags enable multi-language AI systems to adapt their behavior based on deployment environments, user requirements, and operational conditions without requiring code changes or system redeployment. The implementation of comprehensive configuration systems that can manage the complex parameter spaces associated with AI models, optimization algorithms, and system resources enables more flexible and maintainable AI systems that can evolve with changing requirements and operational constraints.
Error Handling and Debugging Strategies
Error handling in multi-language AI systems presents unique challenges due to the complexity of tracking errors across different execution environments, programming languages, and hardware resources. Exception propagation mechanisms must be carefully designed to ensure that errors occurring in C++ or CUDA components are properly captured and reported through Python interfaces while preserving diagnostic information necessary for effective debugging and troubleshooting. The implementation of comprehensive error handling strategies requires careful consideration of error recovery mechanisms, graceful degradation approaches, and diagnostic data collection that enables rapid problem resolution.
Debugging multi-language AI systems requires specialized tools and techniques that can provide insights into system behavior across different execution contexts and component boundaries. Interactive debuggers, logging frameworks, and diagnostic instrumentation must be integrated across all system components to provide comprehensive visibility into system operation and failure modes. The development of custom debugging tools and diagnostic frameworks that can seamlessly operate across language boundaries enables more effective troubleshooting and system maintenance activities.
Fault tolerance and recovery mechanisms enable multi-language AI systems to continue operating despite component failures, resource constraints, or unexpected operational conditions. The implementation of circuit breaker patterns, retry mechanisms, and fallback strategies ensures that temporary failures do not result in complete system outages while providing the diagnostic information necessary for identifying and resolving underlying issues. These resilience patterns become particularly important in production AI systems where availability and reliability requirements must be balanced with performance and resource optimization objectives.
Future Directions and Emerging Technologies
The evolution of multi-language AI systems continues to be driven by advances in hardware architectures, programming language features, and system integration technologies that enable new approaches to performance optimization and system design. Emerging hardware platforms including specialized AI accelerators, quantum computing resources, and neuromorphic processors introduce new programming models and integration challenges that require innovative approaches to multi-language system development. The adaptation of existing frameworks and the development of new integration technologies will be necessary to fully exploit these emerging computational resources.
WebAssembly and containerization technologies are beginning to provide new approaches to multi-language integration that can simplify deployment, improve security, and enable more flexible system architectures. These technologies offer the potential to reduce the complexity associated with traditional multi-language integration while maintaining performance characteristics and enabling new deployment patterns that were previously impractical or impossible. The continued development of these technologies will likely reshape how multi-language AI systems are designed, developed, and deployed in future computing environments.
The integration of artificial intelligence techniques into the development and optimization of multi-language AI systems themselves represents an emerging frontier that could dramatically simplify system development while improving performance characteristics. Auto-tuning systems, intelligent resource management, and automated code generation technologies have the potential to reduce the expertise required for developing high-performance multi-language systems while enabling more sophisticated optimization strategies than human developers could practically implement. These meta-AI approaches represent a promising direction for reducing the complexity and improving the effectiveness of multi-language AI system development.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The techniques and approaches described require careful consideration of specific requirements, constraints, and environments. Readers should conduct thorough testing and validation when implementing multi-language AI systems. Performance characteristics may vary significantly based on hardware configurations, software versions, and implementation details. The effectiveness of optimization techniques depends on specific use cases and may not be applicable to all scenarios.