The evolution of artificial intelligence has reached a pivotal moment where the convergence of multiple sensory modalities is creating unprecedented opportunities for more sophisticated and human-like machine intelligence. Multimodal AI represents a revolutionary approach that transcends the limitations of single-modal systems by integrating vision, text, and audio processing capabilities into unified frameworks that can understand and interpret the world in ways that mirror human cognitive processes.
Discover the latest AI developments and trends that showcase how multimodal systems are pushing the boundaries of what artificial intelligence can accomplish across diverse applications and industries. The integration of multiple sensory inputs into cohesive AI systems marks a fundamental shift from narrow, specialized AI tools toward more general and adaptable artificial intelligence that can process and understand information as naturally as humans do.
This transformative approach to AI development has opened new frontiers in machine learning research and practical applications, enabling systems that can simultaneously analyze visual content, process natural language, and interpret audio signals to create rich, contextual understanding of complex real-world scenarios. The implications of this technological advancement extend far beyond individual improvements in computer vision, natural language processing, or speech recognition, representing instead a holistic evolution toward truly intelligent systems capable of multimodal reasoning and decision-making.
Understanding Multimodal AI Fundamentals
Multimodal artificial intelligence represents a paradigm shift from traditional AI systems that operate within single domains to sophisticated frameworks capable of processing and correlating information across multiple sensory modalities simultaneously. This integration allows AI systems to develop more comprehensive understanding by leveraging the complementary strengths of different input types, much like how humans naturally combine visual observations, auditory information, and textual context to form complete mental models of their environment.
The fundamental architecture of multimodal AI systems involves sophisticated neural networks designed to process heterogeneous data types while maintaining semantic consistency across modalities. These systems employ advanced attention mechanisms and cross-modal learning techniques that enable the AI to understand relationships between visual elements, textual descriptions, and audio components, creating unified representations that capture the full richness of multimodal information.
The technical complexity of multimodal AI lies in the challenge of aligning different types of data that exist in distinct representational spaces. Visual information is typically processed as pixel arrays or feature maps, textual data as token sequences or embeddings, and audio as spectrograms or waveform representations. Successfully integrating these disparate data types requires sophisticated preprocessing, feature extraction, and fusion techniques that preserve the essential characteristics of each modality while enabling meaningful cross-modal interactions.
Vision Processing in Multimodal Systems
Computer vision components within multimodal AI systems have evolved far beyond simple image classification to encompass sophisticated scene understanding, object detection, and spatial reasoning capabilities that provide rich contextual information for integration with other modalities. Modern vision processing modules can identify not only what objects are present in an image but also their spatial relationships, temporal dynamics in video sequences, and semantic significance within broader contexts.
The integration of vision processing with other modalities enables AI systems to ground textual descriptions in visual reality, correlate audio events with visible actions, and create comprehensive scene understanding that encompasses both explicit visual content and implicit contextual information. This capability has proven particularly valuable in applications such as autonomous vehicles, where visual processing must be combined with audio analysis of engine sounds, sirens, or verbal instructions, as well as textual understanding of traffic signs and navigation information.
Advanced vision processing in multimodal systems employs sophisticated attention mechanisms that can focus on relevant visual regions based on textual queries or audio cues, enabling dynamic visual analysis that adapts to the specific information needs of the broader multimodal task. These systems can perform complex visual reasoning tasks such as visual question answering, where textual questions guide the visual analysis process to extract specific information from images or video sequences.
Experience advanced AI capabilities with Claude that demonstrate sophisticated multimodal reasoning and analysis across vision, text, and complex problem-solving scenarios. The seamless integration of multiple AI capabilities creates powerful tools for understanding and processing complex information across diverse domains and applications.
Natural Language Processing Integration
The natural language processing components of multimodal AI systems extend far beyond traditional text analysis to encompass sophisticated language understanding that can be informed by and integrated with visual and audio information. This integration enables AI systems to understand language in context, where the meaning of textual information is enriched by accompanying visual scenes or audio environments, creating more nuanced and accurate interpretation of human communication.
Multimodal natural language processing involves advanced techniques for grounding language in perceptual experience, allowing AI systems to understand references to visual objects, spatial relationships, temporal sequences, and sensory experiences described in text. This grounding capability enables more natural human-AI interaction where users can refer to visual elements using pronouns or spatial descriptors that would be meaningless without visual context.
The sophistication of language processing in multimodal systems extends to understanding implicit references, cultural context, and emotional undertones that may be conveyed through combinations of textual content, visual elements, and audio cues. These systems can interpret sarcasm, humor, and subtle emotional expressions that require understanding of multimodal context to decode accurately, representing a significant advancement toward more human-like language comprehension.
Audio Processing and Speech Understanding
Audio processing within multimodal AI systems encompasses not only speech recognition and synthesis but also environmental sound analysis, music understanding, and acoustic event detection that provide crucial contextual information for comprehensive scene understanding. The integration of audio processing with vision and text enables AI systems to create rich, multisensory models of their environment that include both explicit audio content and implicit acoustic context.
Advanced audio processing in multimodal systems can distinguish between different types of sounds, identify speakers in multi-person conversations, analyze emotional tone and intent in speech, and correlate audio events with visual actions or textual descriptions. This capability enables applications such as multimedia content analysis, where AI systems can automatically generate comprehensive descriptions of video content by combining visual analysis with audio understanding and any available textual information.
The temporal nature of audio information adds a crucial dimension to multimodal AI systems, enabling understanding of sequences, causality, and temporal relationships that complement the spatial information provided by vision and the semantic information conveyed through text. This temporal processing capability is essential for applications such as video understanding, real-time interaction systems, and dynamic environment monitoring where changes over time are critical for accurate interpretation.
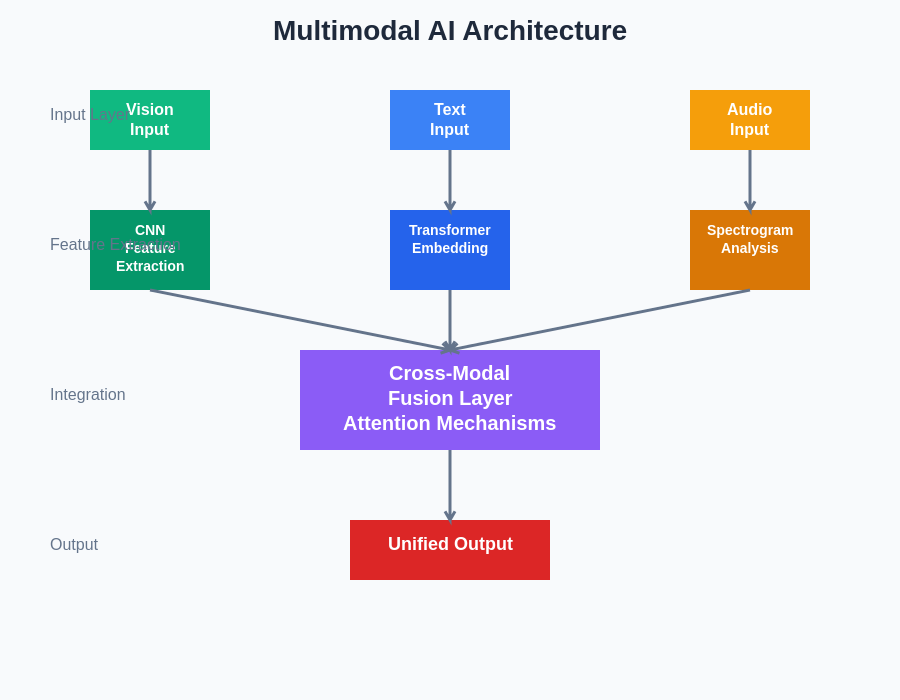
The sophisticated architecture of multimodal AI systems demonstrates how different processing modules work together to create unified understanding from diverse input types. The integration layer serves as the crucial component that enables cross-modal learning and ensures that information from different modalities can be effectively combined to enhance overall system performance and understanding.
Cross-Modal Learning and Fusion Techniques
The heart of multimodal AI lies in sophisticated cross-modal learning techniques that enable systems to discover and exploit relationships between different types of sensory information. These learning approaches go beyond simple concatenation of features from different modalities to encompass advanced fusion strategies that can identify complementary information, resolve conflicts between modalities, and create unified representations that capture the essential characteristics of multimodal experiences.
Cross-modal learning involves training neural networks to understand correspondences between visual elements and textual descriptions, correlations between audio events and visual actions, and relationships between spoken words and written text. These learning processes enable AI systems to transfer knowledge gained in one modality to improve performance in another, creating more robust and generalizable artificial intelligence that can leverage all available information sources.
The fusion techniques employed in multimodal AI systems range from early fusion approaches that combine raw sensory data at the input level to late fusion methods that integrate high-level features extracted from each modality. Advanced attention-based fusion mechanisms can dynamically weight the contribution of different modalities based on the specific requirements of each task, enabling flexible and adaptive multimodal processing that can adjust to varying data quality and availability across different sensory channels.
Applications in Computer Vision and Image Understanding
Multimodal AI has revolutionized computer vision applications by enabling systems that can understand images not just in terms of visual content but also in relation to textual descriptions, audio context, and broader semantic understanding. These enhanced vision systems can perform complex tasks such as visual question answering, image captioning with contextual awareness, and scene understanding that incorporates knowledge from multiple information sources.
The integration of text processing with computer vision has enabled sophisticated applications such as visual search systems that can find images based on natural language descriptions, content moderation systems that understand both visual elements and textual context, and educational applications that can analyze diagrams and illustrations in conjunction with accompanying text to provide comprehensive explanations and tutorials.
Advanced multimodal vision systems can perform complex reasoning tasks that require understanding of both explicit visual content and implicit contextual information provided through text or audio channels. These capabilities have proven particularly valuable in applications such as medical imaging analysis, where visual analysis of medical images must be integrated with patient history, textual reports, and clinical context to provide accurate and comprehensive diagnostic support.
Enhance your AI research capabilities with Perplexity for comprehensive information gathering and analysis across multiple domains and modalities. The combination of advanced search capabilities with multimodal understanding creates powerful tools for research and development in complex AI applications.
Natural Language Processing Enhancements
The integration of multimodal capabilities has significantly enhanced natural language processing by providing systems with perceptual grounding that enables more accurate and contextual language understanding. Multimodal NLP systems can understand textual descriptions of visual scenes, correlate spoken words with visual actions, and interpret language that refers to sensory experiences or environmental context that would be impossible to understand through text alone.
These enhanced NLP capabilities have enabled applications such as multimodal chatbots that can discuss images, voice assistants that can understand visual context, and content analysis systems that can process multimedia documents containing combinations of text, images, and audio. The ability to ground language understanding in perceptual experience has created more natural and intuitive human-AI interfaces that can handle complex, contextual communication scenarios.
Advanced multimodal NLP systems can understand implicit references, spatial relationships, temporal sequences, and emotional context that may be conveyed through combinations of textual, visual, and audio information. This comprehensive understanding enables more sophisticated dialogue systems, improved machine translation that considers visual context, and enhanced content generation systems that can create multimedia content with consistent meaning across different modalities.
Audio and Speech Recognition Advancements
Multimodal integration has transformed audio and speech recognition from isolated processing tasks into components of comprehensive understanding systems that can leverage visual and textual context to improve accuracy and robustness. Modern multimodal speech recognition systems can use visual lip-reading information to improve accuracy in noisy environments, correlate spoken words with visual actions to enhance understanding, and integrate textual context to resolve ambiguities in speech recognition.
The enhancement of audio processing through multimodal integration has enabled applications such as automatic video captioning that combines speech recognition with visual scene understanding, multimodal voice assistants that can respond to both verbal commands and visual gestures, and conference transcription systems that can identify speakers using both audio and visual information while incorporating contextual understanding from presentation slides or documents.
Advanced multimodal audio systems can analyze not only the explicit content of speech but also emotional tone, speaker intent, and contextual appropriateness by integrating audio analysis with visual cues and textual context. These capabilities have proven valuable in applications such as customer service automation, educational technology, and accessibility tools that need to understand not just what is said but also the broader context and intent behind spoken communication.
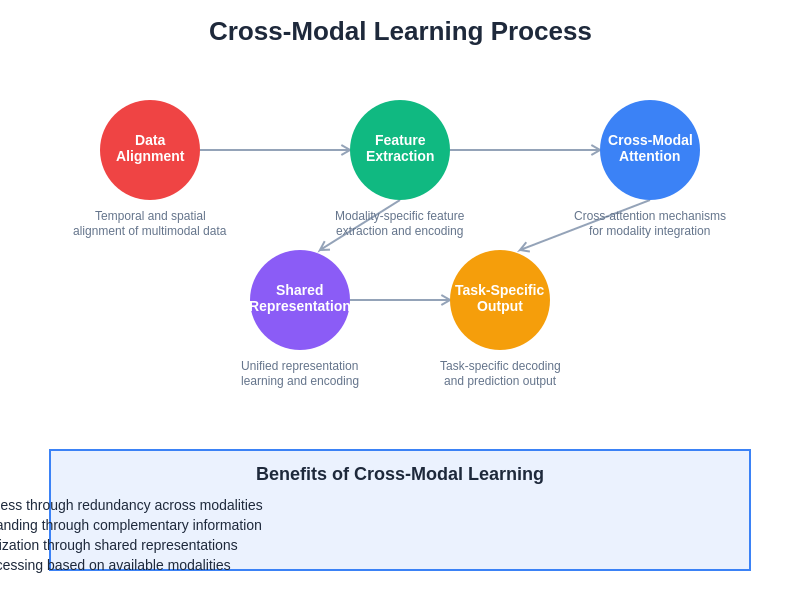
The cross-modal learning process demonstrates how different types of information are processed, aligned, and fused to create unified understanding. This sophisticated approach enables AI systems to leverage the strengths of each modality while compensating for the limitations of individual channels through intelligent integration and correlation of multimodal information.
Industry Applications and Use Cases
The practical applications of multimodal AI span across numerous industries, each leveraging the technology’s ability to process and integrate multiple types of information to solve complex real-world problems. In healthcare, multimodal AI systems analyze medical images, patient records, and clinical notes to provide comprehensive diagnostic support that considers both visual indicators and textual medical history. These systems can identify patterns and correlations that might be missed when analyzing each information source in isolation.
The automotive industry has embraced multimodal AI for autonomous vehicle development, where systems must simultaneously process camera feeds, lidar data, audio sensors, and map information while understanding traffic signs, road conditions, and verbal instructions from passengers. The integration of multiple sensory inputs enables more robust and reliable autonomous driving systems that can handle complex real-world scenarios with greater safety and accuracy.
In the entertainment and media industry, multimodal AI enables sophisticated content analysis, automatic subtitle generation, content recommendation systems that consider visual, audio, and textual preferences, and creative tools that can generate multimedia content with consistent themes across different modalities. These applications have transformed how content is created, analyzed, and personalized for individual users while enabling new forms of interactive and immersive entertainment experiences.
Technical Challenges and Solutions
The development of effective multimodal AI systems presents numerous technical challenges that require sophisticated solutions and innovative approaches. One of the primary challenges involves the alignment of different types of data that exist in distinct representational spaces with different temporal and spatial characteristics. Solving this alignment problem requires advanced preprocessing techniques, sophisticated attention mechanisms, and carefully designed neural network architectures that can handle heterogeneous data types while maintaining semantic consistency.
Another significant challenge lies in handling missing or corrupted data across different modalities, as real-world applications often involve scenarios where not all types of sensory information are available or reliable. Robust multimodal systems must be able to gracefully degrade performance when certain modalities are unavailable while leveraging available information sources to maintain functionality and accuracy.
The computational complexity of multimodal AI systems presents additional challenges, as processing multiple types of high-dimensional data simultaneously requires significant computational resources and sophisticated optimization techniques. Solutions to these challenges include advanced model compression techniques, efficient attention mechanisms, and distributed processing approaches that can handle the computational demands of multimodal AI while maintaining real-time performance requirements.
Performance Optimization and Efficiency
Optimizing the performance of multimodal AI systems requires careful consideration of computational efficiency, memory usage, and real-time processing requirements across multiple data streams. Advanced optimization techniques include selective attention mechanisms that focus computational resources on the most relevant information, progressive processing approaches that can provide partial results while continuing to refine understanding, and adaptive algorithms that can adjust processing complexity based on available computational resources.
The development of efficient multimodal architectures involves sophisticated design decisions regarding the balance between early fusion and late fusion approaches, the optimal placement of attention mechanisms, and the use of shared versus modality-specific processing components. These architectural choices significantly impact both the performance and efficiency of multimodal systems, requiring careful optimization based on specific application requirements and constraints.
Advanced multimodal systems employ dynamic resource allocation strategies that can adjust computational focus based on the complexity and importance of different information sources, enabling efficient processing that maintains high accuracy while minimizing resource consumption. These optimization strategies are crucial for enabling multimodal AI deployment in resource-constrained environments such as mobile devices, embedded systems, and real-time applications.

The performance improvements achieved through multimodal integration demonstrate significant advantages across key metrics including accuracy, robustness, and contextual understanding. These quantitative improvements validate the technical advancement and practical value of multimodal approaches compared to single-modal AI systems.
Future Developments and Research Directions
The future of multimodal AI research points toward even more sophisticated integration techniques that can handle increasingly complex combinations of sensory information while approaching human-level understanding and reasoning capabilities. Emerging research directions include the development of more efficient cross-modal learning algorithms, the integration of additional sensory modalities such as tactile and olfactory information, and the creation of more generalizable multimodal architectures that can adapt to new combinations of input types without extensive retraining.
Advanced research in multimodal AI is exploring the development of systems that can understand and generate content across multiple modalities simultaneously, enabling applications such as multimodal content creation, cross-modal translation, and sophisticated human-AI collaboration tools. These future systems will likely incorporate more sophisticated reasoning capabilities that can perform complex logical operations across different types of information while maintaining consistency and coherence across all modalities.
The integration of multimodal AI with other emerging technologies such as quantum computing, neuromorphic processors, and advanced robotics promises to create even more powerful and efficient systems that can handle increasingly complex real-world scenarios. These technological convergences will likely enable new applications and capabilities that are currently beyond the scope of existing AI systems, potentially leading to breakthroughs in artificial general intelligence and human-AI collaboration.
Ethical Considerations and Responsible Development
The development and deployment of multimodal AI systems raise important ethical considerations regarding privacy, bias, and the responsible use of sophisticated AI capabilities that can process and analyze multiple types of personal information simultaneously. The integration of vision, text, and audio processing capabilities creates systems with unprecedented ability to understand and interpret human behavior, communication, and environment, necessitating careful consideration of privacy protection and consent mechanisms.
Addressing bias in multimodal AI systems requires comprehensive approaches that consider how biases in different modalities can interact and compound each other, potentially creating more severe discrimination than would occur in single-modal systems. Responsible development practices must include diverse training data, comprehensive bias testing across all modalities, and ongoing monitoring of system behavior in real-world deployment scenarios.
The transparency and explainability of multimodal AI decisions present additional challenges, as the complexity of cross-modal reasoning can make it difficult to understand why systems make particular decisions or how different types of information contribute to final outcomes. Developing interpretable multimodal AI requires sophisticated explanation mechanisms that can communicate the reasoning process across different modalities in ways that humans can understand and validate.
Implementation Strategies and Best Practices
Successful implementation of multimodal AI systems requires careful planning and consideration of technical, practical, and organizational factors that can impact system performance and adoption. Best practices for multimodal AI implementation include starting with clear problem definitions that identify the specific value that multimodal integration can provide, careful data collection and preprocessing strategies that ensure high-quality input across all modalities, and iterative development approaches that allow for continuous refinement and optimization.
The selection of appropriate fusion techniques and architectural approaches should be based on careful analysis of the specific requirements, constraints, and objectives of each application, as different approaches may be optimal for different use cases and deployment scenarios. Implementation teams should consider factors such as real-time processing requirements, computational resource constraints, data availability and quality, and integration requirements with existing systems and workflows.
Successful multimodal AI projects typically involve close collaboration between domain experts, AI researchers, and engineering teams to ensure that technical capabilities are properly aligned with practical requirements and user needs. This collaborative approach helps ensure that multimodal AI systems provide genuine value while addressing real-world challenges and constraints that might not be apparent from purely technical perspectives.
The continued evolution of multimodal artificial intelligence represents one of the most promising directions for achieving more sophisticated and human-like AI systems that can understand and interact with the world through multiple sensory channels. As these technologies continue to advance, they promise to unlock new possibilities for human-AI collaboration, creative expression, and problem-solving across diverse domains and applications, fundamentally transforming how we interact with and benefit from artificial intelligence in our daily lives and professional endeavors.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on current understanding of multimodal AI technologies and their applications. Readers should conduct their own research and consider their specific requirements when implementing multimodal AI systems. The effectiveness and suitability of different approaches may vary depending on specific use cases, technical constraints, and application requirements.