
Python’s dominance in machine learning stems from its simplicity and extensive ecosystem, yet its interpreted nature often becomes a bottleneck when processing large datasets or executing computationally intensive algorithms. The quest for performance optimization has led to the development of sophisticated tools that bridge the gap between Python’s ease of use and the speed requirements of modern machine learning applications. Among these solutions, Numba and Cython stand out as the most prominent approaches for accelerating Python code, each offering distinct advantages and trade-offs that can dramatically impact the performance of machine learning workflows.
Explore the latest trends in AI performance optimization to discover cutting-edge techniques that are revolutionizing computational efficiency in machine learning applications. The choice between Numba and Cython represents more than a technical decision; it embodies a strategic approach to balancing development productivity with computational performance in an era where machine learning models are becoming increasingly complex and data-hungry.
Understanding the Performance Challenge in Python ML
The interpreted nature of Python creates inherent performance limitations that become particularly pronounced in machine learning contexts where operations on large arrays, iterative algorithms, and mathematical computations are commonplace. Traditional Python execution involves significant overhead from the interpreter, dynamic typing system, and object-oriented abstractions that, while providing flexibility and ease of development, can result in execution speeds that are orders of magnitude slower than compiled languages like C or Fortran.
Machine learning workloads present unique challenges that amplify these performance issues. Neural network training involves millions of matrix operations, gradient calculations, and parameter updates that must be executed efficiently to make training feasible within reasonable timeframes. Similarly, data preprocessing pipelines often require transformation of massive datasets where every microsecond of optimization can translate to hours of saved computation time across entire workflows.
The emergence of tools like Numba and Cython represents a response to these challenges, offering different philosophies for achieving near-native performance while maintaining Python’s developer-friendly characteristics. These solutions enable data scientists and machine learning engineers to write performance-critical code in Python syntax while achieving execution speeds comparable to lower-level programming languages.
Numba: Just-In-Time Compilation Revolution
Numba represents a paradigm shift in Python performance optimization through its just-in-time compilation approach that transforms Python functions into optimized machine code at runtime. Developed by Anaconda Inc., Numba leverages the LLVM compiler infrastructure to analyze Python bytecode and generate highly optimized native code that can achieve performance levels comparable to hand-written C code for numerical computations.
The fundamental appeal of Numba lies in its minimal intrusion into existing Python workflows. Developers can often achieve dramatic performance improvements by simply adding decorators to existing functions, making it an attractive option for rapid prototyping and iterative development. This decorator-based approach means that the same code can run in both interpreted and compiled modes, providing flexibility during development and deployment phases.
Numba’s strength in machine learning applications becomes particularly evident in scenarios involving numerical computations, array operations, and mathematical functions that are common in algorithm implementations. The tool excels at optimizing loops, mathematical operations, and NumPy array manipulations, making it ideal for custom loss functions, specialized optimizers, and novel algorithm implementations that require fine-grained control over computational efficiency.
Experience advanced AI development tools like Claude for comprehensive analysis and optimization guidance that can help you make informed decisions about performance optimization strategies in your machine learning projects. The integration of intelligent development assistance with performance optimization tools creates a powerful ecosystem for building efficient machine learning solutions.
Cython: Bridging Python and C Performance
Cython approaches performance optimization from a different angle, serving as a programming language that is essentially Python with C-like performance characteristics. Rather than just-in-time compilation, Cython employs ahead-of-time compilation, transforming Python-like code into optimized C code that is then compiled into native extensions. This approach provides developers with explicit control over optimization decisions while maintaining much of Python’s familiar syntax and semantics.
The power of Cython lies in its ability to seamlessly integrate with existing C libraries and provide fine-grained control over memory management, type declarations, and low-level optimizations. For machine learning applications that require integration with specialized mathematical libraries, custom data structures, or direct interfacing with hardware-accelerated computing platforms, Cython offers unparalleled flexibility and control.
Cython’s static typing capabilities enable aggressive compiler optimizations that can eliminate much of the overhead associated with Python’s dynamic typing system. By explicitly declaring variable types and function signatures, developers can guide the compiler to generate highly efficient machine code that rivals hand-optimized C implementations. This level of control makes Cython particularly suitable for production environments where predictable performance characteristics are essential.
Performance Characteristics and Benchmarking
The performance differences between Numba and Cython vary significantly depending on the specific use case, algorithm complexity, and implementation approach. Numba typically excels in scenarios involving intensive numerical computations, array operations, and mathematical functions where its JIT compiler can effectively optimize hot code paths. The tool’s ability to generate vectorized instructions and optimize memory access patterns makes it particularly effective for algorithms that involve repetitive numerical operations on large datasets.
Cython’s performance advantages become more pronounced in applications requiring complex data structures, extensive use of Python objects, or integration with external C libraries. The static compilation approach enables more comprehensive optimizations across the entire codebase, resulting in consistent performance characteristics that are crucial for production deployments where predictable execution times are essential.
Benchmark comparisons between Numba and Cython often reveal that both tools can achieve similar peak performance for numerical computations, with the choice between them frequently determined by factors such as development workflow preferences, integration requirements, and long-term maintenance considerations rather than raw performance differences.
Machine Learning Use Cases and Applications
In the context of machine learning, both Numba and Cython find applications across different aspects of the development pipeline. Numba’s strength in accelerating numerical computations makes it ideal for implementing custom loss functions, specialized optimization algorithms, and novel neural network architectures where standard library implementations may not be available or sufficiently optimized.
Feature engineering pipelines often benefit significantly from Numba optimization, particularly when dealing with time series data, signal processing operations, or complex transformations that involve iterative computations. The ability to accelerate these preprocessing steps can have cascading effects on overall training pipeline efficiency, enabling faster experimentation cycles and more thorough hyperparameter exploration.
Cython’s capabilities shine in scenarios requiring integration with specialized computing libraries, implementation of custom data loaders, or development of high-performance inference engines. The tool’s ability to create Python extensions that seamlessly integrate with existing ecosystems makes it valuable for building reusable components that can be distributed and deployed across different environments.
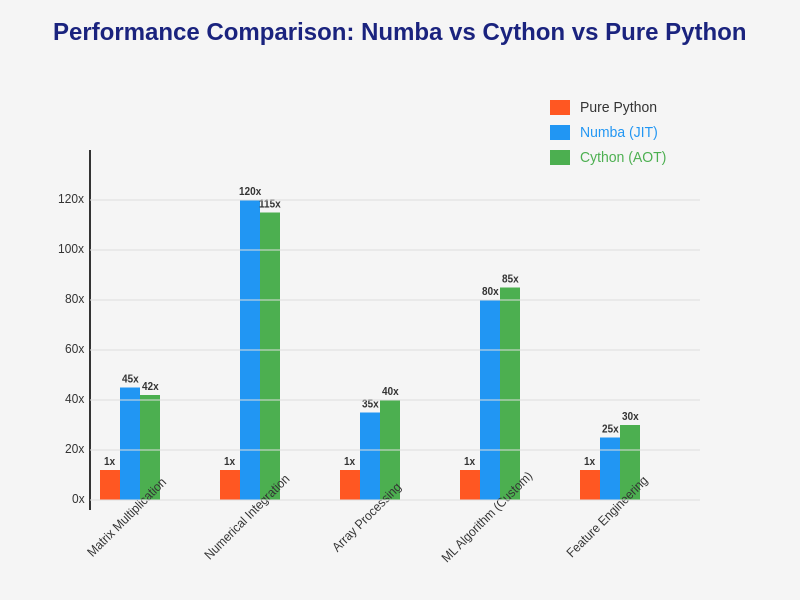
The comparative analysis of performance optimization approaches reveals distinct advantages for different types of machine learning workloads. Understanding these performance characteristics enables developers to make informed decisions about which tool best suits their specific requirements and constraints.
Enhance your research capabilities with Perplexity to stay current with the latest developments in Python performance optimization and machine learning acceleration techniques. The rapid evolution of optimization tools requires continuous learning and adaptation to maintain competitive advantages in machine learning development.
Development Workflow and Integration Considerations
The choice between Numba and Cython often comes down to workflow preferences and integration requirements rather than pure performance considerations. Numba’s decorator-based approach integrates seamlessly into existing development workflows, allowing developers to experiment with optimization incrementally without significant code restructuring. This approach is particularly valuable during the research and development phases where rapid iteration and experimentation are prioritized over ultimate performance optimization.
Cython requires a more structured approach to optimization, involving explicit type declarations, careful memory management, and compilation steps that can complicate the development workflow. However, this additional complexity often results in more predictable performance characteristics and better integration with existing C-based scientific computing ecosystems, making it preferable for production deployments where stability and predictability are paramount.
The debugging experience differs significantly between the two approaches. Numba-optimized code can be debugged using standard Python debugging tools by simply removing optimization decorators, while Cython debugging often requires specialized tools and techniques due to the compilation process. This difference in debugging accessibility can significantly impact development velocity, particularly for complex algorithms where debugging is an integral part of the development process.
Memory Management and Resource Optimization
Memory management represents a critical consideration in machine learning applications where large datasets and complex models can quickly exhaust available system resources. Numba’s approach to memory management is largely transparent to the developer, with the JIT compiler automatically optimizing memory access patterns and eliminating unnecessary allocations where possible. This automatic optimization can be highly effective for many use cases but provides limited control for applications with specific memory management requirements.
Cython offers explicit control over memory management through direct integration with Python’s memory allocation mechanisms and the ability to interface with custom memory management systems. This level of control enables optimization of memory-intensive applications such as large-scale data processing pipelines or applications running in memory-constrained environments where every byte of optimization matters.
The garbage collection behavior also differs between the two approaches. Numba-compiled code generally maintains Python’s garbage collection semantics, while Cython can provide more control over object lifecycle management, potentially reducing garbage collection overhead in long-running applications or real-time systems where consistent performance is critical.
Parallel Computing and Scalability
Modern machine learning workloads increasingly require parallel processing capabilities to effectively utilize multi-core processors and distributed computing environments. Numba provides built-in support for parallel execution through its parallel compilation targets, enabling automatic parallelization of suitable loops and operations without requiring explicit parallel programming constructs.
The parallel capabilities of Numba are particularly effective for embarrassingly parallel computations common in machine learning, such as batch processing operations, Monte Carlo simulations, and certain types of optimization algorithms. The ability to achieve parallel speedups with minimal code changes makes Numba attractive for scaling existing algorithms to multi-core environments.
Cython’s approach to parallelism typically requires more explicit programming using OpenMP directives or integration with external parallel computing libraries. While this approach requires more developer effort, it provides greater control over parallelization strategies and can achieve superior performance in complex parallel algorithms where automatic parallelization may not be optimal.
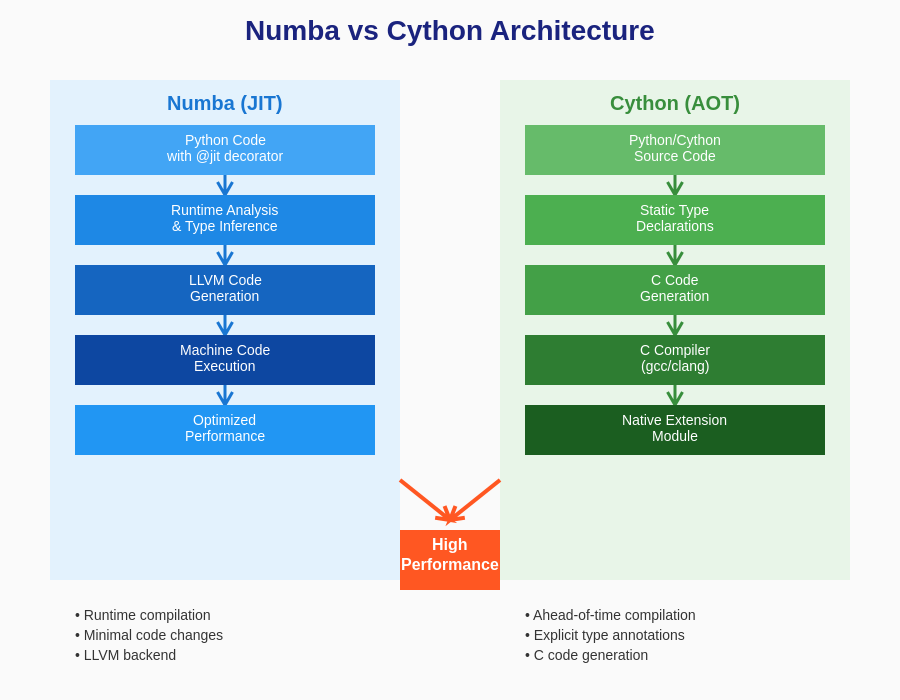
The architectural differences between Numba and Cython reflect their distinct approaches to performance optimization, with implications for development workflow, deployment strategies, and long-term maintenance considerations.
GPU Computing and Hardware Acceleration
The landscape of machine learning increasingly involves GPU computing and specialized hardware acceleration, making the ability to target these platforms a crucial consideration for performance optimization tools. Numba provides direct support for CUDA GPU programming through its CUDA target, enabling developers to write GPU kernels in Python syntax and achieve performance levels comparable to hand-written CUDA C code.
This GPU support in Numba is particularly valuable for machine learning applications where certain operations can benefit dramatically from parallel execution on GPU architectures. Custom loss functions, specialized neural network layers, and data preprocessing operations can often be accelerated by orders of magnitude when properly implemented for GPU execution.
Cython’s approach to GPU computing typically involves interfacing with existing GPU libraries such as CUDA runtime or specialized machine learning frameworks. While this approach requires more integration work, it provides access to the full ecosystem of GPU-accelerated libraries and enables fine-grained control over GPU resource utilization.
Production Deployment and Distribution
The deployment characteristics of Numba and Cython-optimized code differ significantly in ways that can impact production system design and distribution strategies. Numba’s just-in-time compilation means that optimization occurs at runtime, requiring the LLVM infrastructure to be available in the deployment environment. This requirement can complicate deployment in constrained environments or systems where dependencies must be minimized.
Cython’s ahead-of-time compilation produces native extensions that can be distributed independently of the compilation infrastructure, making deployment more straightforward in many production environments. The compiled extensions can be packaged as standard Python wheels and distributed through conventional package management systems without requiring specialized runtime dependencies.
Performance predictability in production environments often favors Cython due to the ahead-of-time compilation approach that eliminates just-in-time compilation overhead and provides consistent startup performance. Numba applications may experience cold-start penalties during initial execution while the JIT compiler analyzes and optimizes the code, which can be problematic in latency-sensitive applications.
Error Handling and Debugging Strategies
The debugging and error handling characteristics of optimized Python code present unique challenges that can significantly impact development velocity and application reliability. Numba’s approach to error handling attempts to maintain Python’s exception semantics where possible, but certain optimizations may alter error behavior or make debugging more challenging due to the compilation process.
The debugging experience with Numba-optimized code benefits from the ability to selectively disable optimization for debugging purposes, allowing developers to use standard Python debugging tools and techniques. However, performance-related issues may only manifest when optimization is enabled, creating challenges in isolating and resolving optimization-specific problems.
Cython debugging requires specialized tools and techniques due to the compilation process, but provides more predictable error behavior and performance characteristics. The static compilation approach enables more comprehensive error detection at compile time, potentially catching issues that might only manifest at runtime in interpreted Python code.
Future Trends and Evolution
The evolution of Python performance optimization tools continues to accelerate, driven by the growing computational demands of machine learning applications and the emergence of new hardware architectures. Both Numba and Cython are actively evolving to support emerging paradigms such as machine learning on edge devices, quantum computing integration, and advanced GPU architectures.
The integration of artificial intelligence into the optimization process itself represents an emerging trend where machine learning techniques are applied to automatically optimize code generation and compilation strategies. This meta-application of AI to improve AI development tools promises to further democratize high-performance computing for machine learning applications.
The convergence of different optimization approaches is also becoming apparent, with hybrid solutions that combine just-in-time and ahead-of-time compilation strategies to capture the benefits of both approaches. These emerging techniques may eventually blur the distinctions between current optimization tools while providing even greater performance improvements.
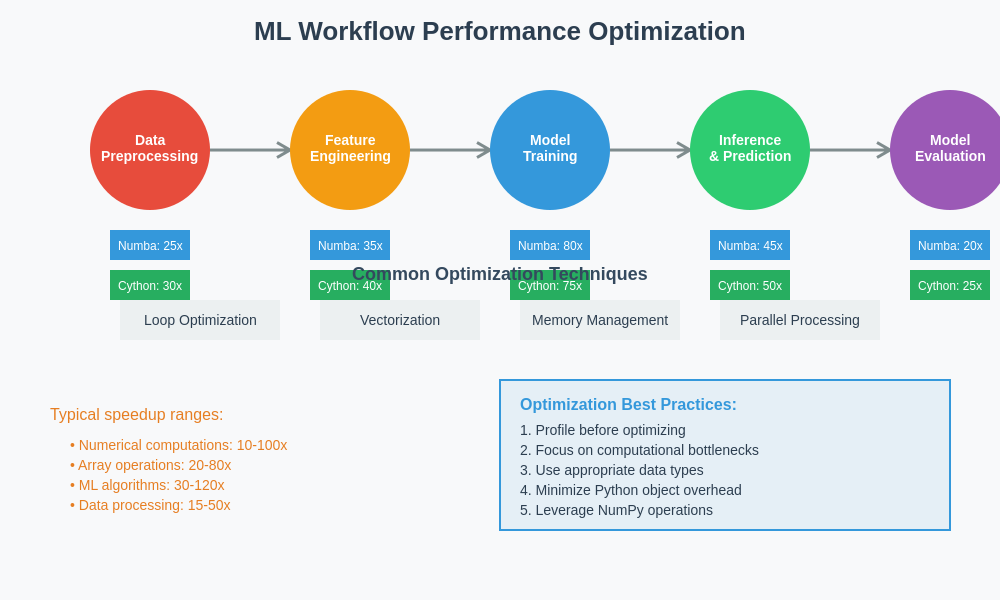
The integration of performance optimization tools into machine learning workflows requires careful consideration of trade-offs between development velocity, performance characteristics, and deployment requirements. Understanding these relationships enables more effective optimization strategies.
Strategic Decision Framework
Choosing between Numba and Cython requires a systematic evaluation of project requirements, team capabilities, and long-term strategic goals. Projects emphasizing rapid prototyping and experimentation often benefit from Numba’s minimal integration overhead and immediate performance improvements. The ability to achieve significant speedups with minimal code changes makes Numba particularly attractive for research environments where development velocity is prioritized.
Production-focused projects with stringent performance requirements, complex integration needs, or long-term maintenance considerations may favor Cython’s more structured approach to optimization. The predictable performance characteristics and extensive control over optimization decisions make Cython suitable for mission-critical applications where reliability and consistency are paramount.
Team expertise and available resources also play crucial roles in tool selection. Organizations with extensive C/C++ expertise may find Cython’s compilation model more familiar and manageable, while teams focused primarily on Python development might prefer Numba’s transparent optimization approach.
Performance Optimization Best Practices
Effective utilization of either Numba or Cython requires understanding of fundamental performance optimization principles that apply regardless of the specific tool chosen. Profiling and benchmarking should precede optimization efforts to identify genuine performance bottlenecks rather than optimizing code sections that have minimal impact on overall performance.
Algorithm selection often has more significant performance implications than optimization tool choice. Selecting appropriate data structures, minimizing unnecessary computations, and leveraging vectorized operations can provide performance improvements that exceed what optimization tools alone can achieve. The combination of algorithmic improvements with tool-based optimization typically yields the best overall results.
Memory access patterns play crucial roles in optimization effectiveness, particularly for machine learning applications that process large datasets. Understanding cache behavior, minimizing memory allocations, and optimizing data layout can significantly enhance the effectiveness of both Numba and Cython optimizations.
The landscape of Python performance optimization for machine learning continues to evolve rapidly, driven by the increasing computational demands of modern AI applications and the emergence of new hardware architectures. The choice between Numba and Cython represents a strategic decision that extends beyond immediate performance considerations to encompass development workflow preferences, team capabilities, and long-term project goals.
Success with either tool requires understanding of fundamental performance optimization principles, careful profiling and benchmarking practices, and recognition that tool selection should align with broader project objectives rather than purely technical considerations. The continued evolution of both tools promises even greater capabilities for accelerating Python-based machine learning applications while maintaining the language’s characteristic ease of use and development productivity.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. Performance characteristics of optimization tools may vary significantly depending on specific use cases, hardware configurations, and implementation approaches. Readers should conduct thorough benchmarking and evaluation based on their specific requirements before making optimization tool decisions. The effectiveness of performance optimization techniques depends on numerous factors including algorithm design, data characteristics, and system architecture.