
The data center AI accelerator landscape has reached a pivotal moment with two formidable contenders vying for dominance in the artificial intelligence and high-performance computing markets. NVIDIA’s H100 Tensor Core GPU and AMD’s MI300X APU represent the pinnacle of their respective companies’ engineering prowess, each offering distinct advantages and architectural innovations that cater to the demanding requirements of modern AI workloads, large-scale machine learning training, and inference operations.
Explore the latest AI hardware trends to understand how these cutting-edge accelerators are shaping the future of artificial intelligence infrastructure. The competition between these two silicon giants has intensified dramatically as organizations worldwide seek to build the most capable and cost-effective AI computing platforms for their data center operations.
Architectural Foundations and Design Philosophy
The NVIDIA H100 represents the evolution of the company’s proven GPU architecture, built on the advanced Hopper architecture using TSMC’s 4nm process technology. This architectural foundation emphasizes specialized tensor processing units, advanced memory hierarchy design, and optimized interconnect capabilities that have established NVIDIA as the dominant force in AI acceleration. The H100’s design philosophy centers around maximizing parallel processing throughput while maintaining exceptional energy efficiency for both training and inference workloads across diverse AI applications.
In contrast, AMD’s MI300X takes a revolutionary approach by combining CPU and GPU capabilities within a single accelerated processing unit, leveraging the company’s expertise in both processor architectures. Built on advanced 5nm and 6nm process nodes, the MI300X represents AMD’s ambitious vision of unified computing where traditional boundaries between CPU and GPU processing dissolve. This architectural innovation enables unprecedented memory bandwidth and capacity while providing flexible compute resources that can dynamically adapt to varying workload requirements.
The fundamental difference in architectural philosophy creates distinct advantages for each platform, with NVIDIA’s specialized approach optimizing for AI-specific operations while AMD’s unified approach provides broader computational flexibility and potentially superior cost-effectiveness for mixed workloads that require both CPU and GPU capabilities within the same system configuration.
Performance Characteristics and Computational Capabilities
The NVIDIA H100 delivers exceptional performance with its 80 billion transistors distributed across 132 streaming multiprocessors, each containing fourth-generation Tensor Cores specifically optimized for AI matrix operations. The accelerator provides up to 67 teraFLOPS of FP64 performance, 134 teraFLOPS of FP32 performance, and an impressive 1,979 teraFLOPS of mixed-precision AI performance when utilizing specialized tensor operations. This performance profile makes the H100 particularly well-suited for large language model training, computer vision applications, and scientific computing workloads that demand maximum computational throughput.
Experience advanced AI development with Claude to leverage the full potential of these powerful accelerators in your machine learning projects. The H100’s memory subsystem features 80GB of high-bandwidth memory with 3TB/s of memory bandwidth, providing the substantial memory capacity and throughput necessary for processing large datasets and complex neural network models without performance bottlenecks.
The AMD MI300X presents a compelling alternative with its innovative chiplet-based design that incorporates 24 CPU cores alongside GPU compute units within a single package. This unified architecture provides 192GB of high-bandwidth memory with exceptional memory bandwidth exceeding 5TB/s, representing a significant advantage for memory-intensive AI workloads. The MI300X delivers competitive floating-point performance while offering unique capabilities for workloads that benefit from tight CPU-GPU integration and massive memory capacity.
Memory Architecture and Data Movement Optimization
Memory architecture represents a critical differentiator between these two accelerators, with each platform implementing distinct strategies for optimizing data movement and storage. The NVIDIA H100 utilizes a sophisticated memory hierarchy featuring multiple levels of cache, high-bandwidth HBM3 memory, and advanced memory compression techniques that minimize data movement overhead. The accelerator’s memory subsystem has been meticulously engineered to support the massive data requirements of transformer-based models and other memory-intensive AI applications.
The H100’s memory architecture includes specialized features such as confidential computing support, advanced error correction capabilities, and optimized memory access patterns that maximize utilization of available bandwidth. These architectural innovations enable sustained high-performance operation even when processing datasets that exceed the accelerator’s physical memory capacity through efficient data streaming and caching mechanisms.
AMD’s MI300X revolutionizes memory architecture by implementing a unified memory space accessible by both CPU and GPU compute units, eliminating traditional memory copying operations between separate processor domains. This architectural innovation, combined with the accelerator’s massive 192GB memory capacity, creates unprecedented opportunities for processing large-scale AI models and datasets entirely within accelerator memory without requiring complex data management strategies.
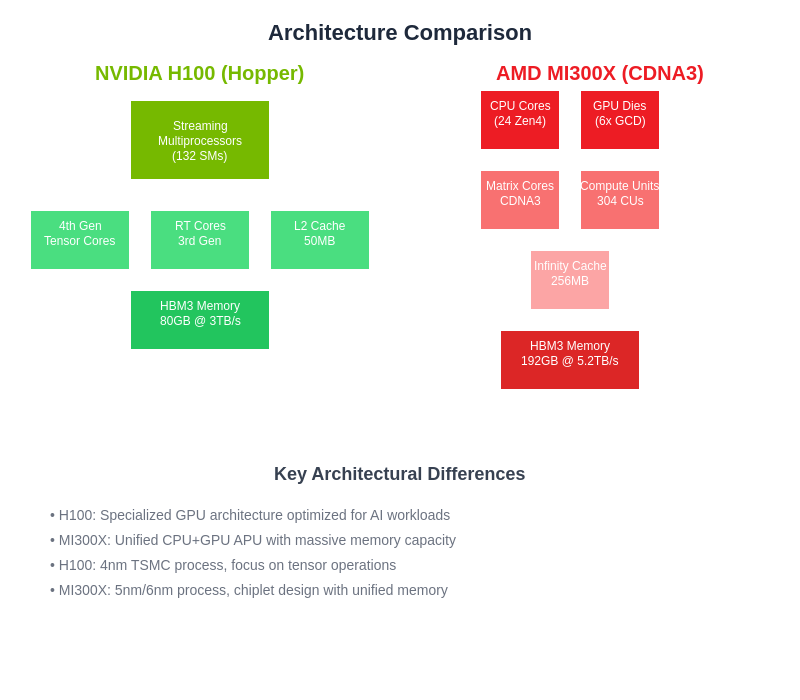
The fundamental architectural differences between these platforms reflect divergent design philosophies, with NVIDIA’s H100 optimizing specialized GPU compute capabilities while AMD’s MI300X integrates CPU and GPU functionality within a unified processing framework that eliminates traditional computational boundaries.
Interconnect Technologies and Scalability
The scalability characteristics of these accelerators significantly impact their suitability for large-scale AI infrastructure deployments. NVIDIA’s H100 incorporates fourth-generation NVLink technology providing 900GB/s of bidirectional bandwidth for multi-GPU communication, enabling efficient scaling across multiple accelerators within the same system. The platform also supports advanced networking capabilities through InfiniBand and Ethernet connectivity optimized for distributed training and inference operations across multiple nodes.
The H100’s interconnect architecture has been specifically designed to minimize communication overhead in large-scale distributed training scenarios, implementing advanced compression algorithms, efficient collective communication primitives, and optimized data routing mechanisms that maintain high performance even when scaling to thousands of accelerators across multiple data center locations.
Leverage Perplexity’s research capabilities to stay informed about the latest developments in AI accelerator interconnect technologies and their impact on distributed computing performance. AMD’s MI300X implements innovative interconnect solutions that leverage the unified CPU-GPU architecture to provide flexible communication pathways and reduced latency for inter-accelerator data exchange.
Software Ecosystem and Development Framework Support
The software ecosystem surrounding these accelerators plays a crucial role in determining their practical applicability and ease of deployment within existing AI development workflows. NVIDIA’s CUDA ecosystem represents one of the most mature and comprehensive development environments for GPU computing, providing extensive libraries, debugging tools, profiling utilities, and optimization frameworks that have been refined through years of development and community contribution.
The H100 benefits from seamless integration with popular AI frameworks including TensorFlow, PyTorch, JAX, and numerous specialized libraries optimized for specific AI workloads. NVIDIA’s software stack includes advanced features such as automatic mixed precision, dynamic loss scaling, and efficient multi-GPU training coordination that simplify the development and deployment of high-performance AI applications.
AMD’s software ecosystem for the MI300X centers around the ROCm platform, which provides comprehensive support for GPU computing while extending capabilities to leverage the accelerator’s unique CPU-GPU unified architecture. The ROCm ecosystem includes optimized implementations of critical AI libraries, compatibility layers for existing CUDA applications, and specialized tools for mixed CPU-GPU workload optimization that take advantage of the MI300X’s architectural innovations.
Power Efficiency and Thermal Considerations
Power efficiency represents a critical factor in data center deployments where operational costs and thermal management significantly impact total cost of ownership. The NVIDIA H100 implements advanced power management techniques including dynamic voltage and frequency scaling, intelligent workload scheduling, and sophisticated thermal throttling mechanisms that optimize performance per watt across diverse operating conditions.
The H100’s power envelope typically ranges from 350W to 700W depending on the specific configuration and cooling solution, with the accelerator implementing advanced power delivery systems and thermal interface materials that enable sustained high-performance operation within enterprise data center environments. NVIDIA’s power management algorithms continuously optimize performance and efficiency based on workload characteristics and thermal constraints.
AMD’s MI300X presents compelling power efficiency characteristics through its unified architecture that eliminates redundant components and reduces overall system power consumption compared to traditional discrete CPU-GPU configurations. The accelerator’s advanced power management features include per-core power gating, intelligent clock gating, and workload-aware power optimization that dynamically adjusts power consumption based on computational requirements.
Cost-Effectiveness and Total Cost of Ownership
The economic considerations surrounding these accelerators extend beyond initial purchase price to encompass total cost of ownership including power consumption, cooling requirements, software licensing, and operational maintenance costs. NVIDIA’s H100 pricing reflects its position as the premium AI accelerator solution, with costs typically ranging from $25,000 to $40,000 per unit depending on configuration and volume purchasing agreements.
The H100’s total cost of ownership must be evaluated within the context of its exceptional performance capabilities, mature software ecosystem, and proven reliability in production deployments. Organizations utilizing H100 accelerators often achieve faster time-to-market for AI applications, reduced development costs through comprehensive tooling support, and superior performance scaling that can justify the premium pricing for critical AI workloads.
AMD’s MI300X positioning emphasizes competitive pricing combined with innovative architectural advantages that can provide superior value for specific use cases. The accelerator’s unified CPU-GPU design can potentially reduce overall system costs by eliminating the need for separate high-performance CPUs in certain configurations, while the massive memory capacity reduces requirements for expensive system memory and storage infrastructure.
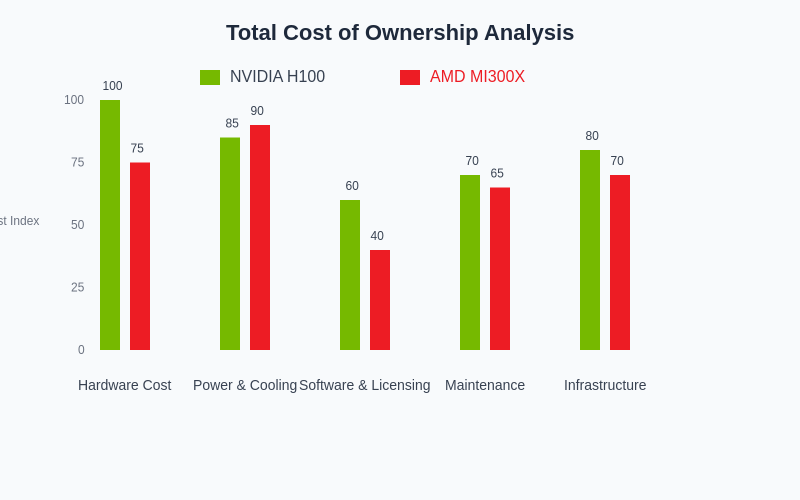
The total cost of ownership analysis reveals nuanced differences between these platforms, with each offering distinct advantages depending on specific deployment scenarios, workload characteristics, and organizational priorities regarding performance optimization versus cost effectiveness.
Performance Benchmarking and Real-World Applications
Comprehensive performance evaluation of these accelerators requires analysis across diverse AI workloads including large language model training, computer vision applications, scientific computing, and inference serving scenarios. NVIDIA’s H100 consistently demonstrates exceptional performance in transformer-based model training, achieving industry-leading throughput for popular architectures such as GPT, BERT, and emerging multimodal models.
The H100’s performance advantages are particularly pronounced in mixed-precision training scenarios where the accelerator’s tensor cores can deliver substantial speedups compared to traditional floating-point operations. Real-world deployments have demonstrated H100’s capability to reduce training times for large language models from weeks to days, enabling more rapid iteration and experimentation in AI research and development.
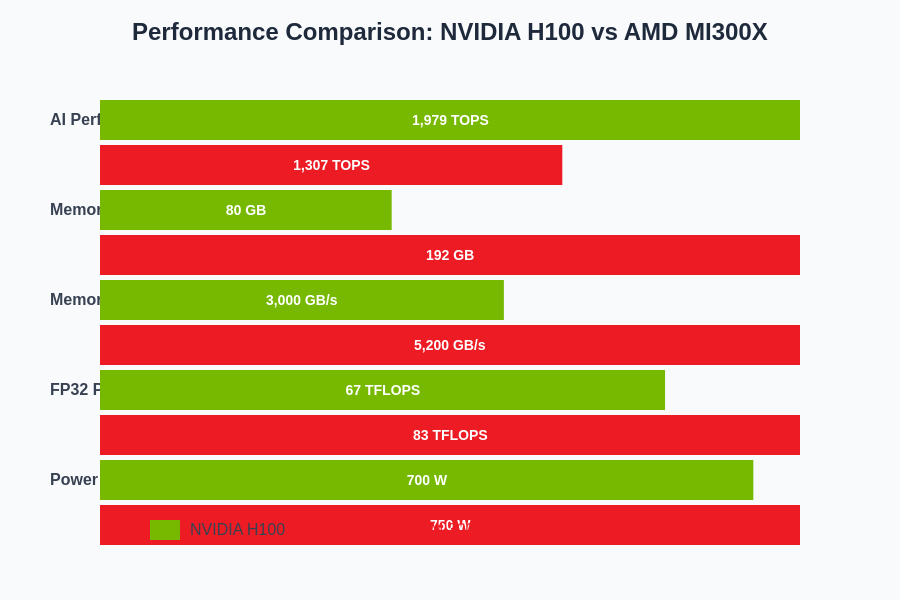
The quantitative performance analysis reveals distinct strengths for each accelerator across different metrics. While the H100 excels in raw AI performance throughput, the MI300X demonstrates superior memory capacity and bandwidth characteristics that benefit memory-intensive workloads and large-scale model deployment scenarios.
AMD’s MI300X performance characteristics show particular strength in workloads that benefit from the massive memory capacity and unified CPU-GPU architecture. Applications involving large-scale graph processing, in-memory analytics, and complex simulation workloads often achieve superior performance on the MI300X platform compared to traditional discrete accelerator configurations.
Market Position and Industry Adoption
The competitive landscape for data center AI accelerators continues evolving as organizations evaluate these platforms for their specific requirements and strategic objectives. NVIDIA’s established market position, extensive partner ecosystem, and proven track record in AI acceleration have resulted in widespread adoption across cloud service providers, research institutions, and enterprise customers building AI infrastructure.
The H100’s market dominance is reinforced by comprehensive support from major cloud platforms including Amazon Web Services, Microsoft Azure, and Google Cloud Platform, which provide immediate access to H100-powered instances for organizations seeking to leverage advanced AI capabilities without significant upfront infrastructure investment. This cloud availability accelerates adoption and enables organizations to evaluate H100 performance before committing to on-premises deployments.
AMD’s MI300X represents a strategic challenge to NVIDIA’s market dominance by offering innovative architectural advantages and competitive pricing that appeal to cost-conscious organizations and specific use cases where the unified CPU-GPU approach provides distinct benefits. Early adoption of MI300X platforms has been driven primarily by organizations seeking alternatives to NVIDIA’s ecosystem and workloads that specifically benefit from the accelerator’s unique architectural characteristics.
Future Technology Roadmaps and Evolution
The ongoing development of these accelerator platforms reflects broader trends in AI computing including increasing model sizes, growing demand for efficient inference serving, and emerging requirements for specialized AI workloads such as multimodal processing and real-time applications. NVIDIA’s roadmap includes continued refinement of tensor processing capabilities, enhanced memory systems, and improved interconnect technologies that maintain the company’s performance leadership in AI acceleration.
Future NVIDIA developments are expected to focus on supporting increasingly large AI models, improving power efficiency for inference workloads, and expanding capabilities for emerging AI applications including robotics, autonomous systems, and edge computing scenarios. The company’s investment in software ecosystem development continues to strengthen the platform’s competitive position through enhanced developer productivity and simplified deployment processes.
AMD’s future accelerator development leverages the company’s expertise in both CPU and GPU technologies to create increasingly sophisticated unified computing platforms. The MI300X represents the first generation of AMD’s vision for integrated AI acceleration, with future developments expected to expand memory capacity, improve performance density, and enhance software ecosystem maturity to compete more effectively with established alternatives.
Deployment Considerations and Best Practices
Successful deployment of these advanced AI accelerators requires careful consideration of infrastructure requirements, cooling systems, power delivery, and network connectivity that can fully utilize their capabilities. NVIDIA H100 deployments typically require robust cooling solutions capable of handling sustained high power loads, high-bandwidth networking infrastructure for distributed training scenarios, and comprehensive monitoring systems that ensure optimal performance and reliability.
Organizations deploying H100 accelerators benefit from NVIDIA’s extensive documentation, reference architectures, and professional services support that simplify integration with existing data center infrastructure. The maturity of NVIDIA’s ecosystem enables relatively straightforward deployment processes with well-established best practices for configuration, optimization, and maintenance of H100-powered systems.
AMD MI300X deployments present unique opportunities and challenges due to the accelerator’s innovative unified architecture. Organizations can potentially simplify their system configurations by leveraging the integrated CPU capabilities, but may require specialized expertise to fully optimize applications for the platform’s unique characteristics. AMD’s growing ecosystem of partners and support resources continues expanding to address deployment and optimization requirements for MI300X platforms.
The strategic decision between these accelerator platforms ultimately depends on specific organizational requirements, existing infrastructure investments, software ecosystem preferences, and long-term AI strategy considerations. Both platforms offer compelling advantages for different use cases, with the optimal choice varying based on workload characteristics, budget constraints, and performance requirements that define each organization’s unique AI acceleration needs.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on publicly available information about AI accelerator technologies and their applications in data center environments. Readers should conduct their own research and consider their specific requirements when evaluating AI accelerator platforms. Performance characteristics and pricing information may vary based on specific configurations, market conditions, and vendor agreements.