
The realm of artificial intelligence and machine learning has witnessed an unprecedented surge in computational demands, driving the evolution of parallel computing architectures and programming frameworks that can harness the immense power of graphics processing units. At the epicenter of this technological revolution stand two dominant paradigms that have fundamentally shaped how developers approach GPU computing: OpenCL and CUDA. These frameworks represent fundamentally different philosophies toward parallel computing, each offering distinct advantages and trade-offs that significantly impact the development and deployment of AI applications across diverse hardware ecosystems.
Discover the latest trends in AI computing to understand how GPU programming frameworks are evolving to meet the demanding requirements of modern artificial intelligence workloads. The choice between OpenCL and CUDA extends far beyond mere technical preferences, encompassing considerations of hardware compatibility, performance optimization, development complexity, and long-term strategic positioning in an increasingly heterogeneous computing landscape.
The Foundation of Parallel GPU Computing
The emergence of general-purpose GPU computing transformed the landscape of high-performance computing by recognizing that the parallel architecture inherent in graphics processors could be leveraged for computational tasks far beyond their original graphics rendering purposes. This paradigm shift opened new possibilities for accelerating complex algorithms, particularly those involving massive datasets and repetitive operations that characterize modern artificial intelligence applications.
OpenCL, developed as an open standard by the Khronos Group, represents a vendor-neutral approach to heterogeneous computing that encompasses not only GPUs but also CPUs, digital signal processors, and field-programmable gate arrays. This comprehensive framework provides developers with the flexibility to write parallel applications that can execute across diverse hardware platforms without requiring fundamental code modifications, making it an attractive option for organizations seeking maximum portability and vendor independence.
CUDA, developed exclusively by NVIDIA, takes a different approach by providing deep integration with NVIDIA’s GPU architecture, offering developers access to specialized hardware features and optimization opportunities that are simply unavailable through vendor-neutral frameworks. This tight coupling between software and hardware enables CUDA to achieve exceptional performance levels on supported platforms while establishing a robust ecosystem of libraries, tools, and educational resources that have accelerated adoption in research and commercial applications.
Architectural Philosophies and Design Principles
The fundamental differences between OpenCL and CUDA extend to their core architectural philosophies, reflecting distinct approaches to balancing performance, portability, and developer accessibility. OpenCL’s design emphasizes abstraction and portability, providing a unified programming model that can adapt to various hardware architectures while maintaining functional consistency across different platforms. This approach requires developers to work within a more generalized framework that may not expose the full capabilities of specific hardware platforms but ensures that applications remain broadly compatible.
CUDA’s architectural philosophy prioritizes performance optimization and hardware-specific feature utilization, providing developers with direct access to NVIDIA GPU capabilities such as shared memory hierarchies, warp-level operations, and specialized tensor cores. This intimate hardware integration enables highly optimized implementations but creates vendor lock-in that limits portability to non-NVIDIA platforms. The trade-off between optimization potential and portability represents a central consideration in framework selection.
Explore advanced AI development tools like Claude to enhance your understanding of parallel computing concepts and optimization strategies across different GPU programming frameworks. The evolution of AI workloads continues to drive innovation in both OpenCL and CUDA, with each framework adapting to address the unique computational patterns and memory access requirements of modern machine learning algorithms.
Performance Characteristics and Optimization Strategies
Performance analysis between OpenCL and CUDA reveals nuanced differences that depend heavily on specific use cases, hardware configurations, and optimization techniques employed by developers. CUDA generally demonstrates superior performance on NVIDIA hardware due to its direct access to proprietary optimizations, specialized libraries like cuBLAS and cuDNN, and intimate knowledge of underlying GPU microarchitecture. This performance advantage is particularly pronounced in applications that can leverage NVIDIA’s tensor cores for mixed-precision arithmetic or utilize advanced memory management features.
OpenCL performance varies significantly across different hardware vendors and implementations, as each platform provider optimizes their OpenCL runtime for their specific hardware characteristics. While this can result in competitive performance on optimally supported platforms, it also introduces variability that can complicate performance prediction and optimization efforts. The vendor-neutral nature of OpenCL means that applications must often sacrifice some platform-specific optimizations to maintain broad compatibility.
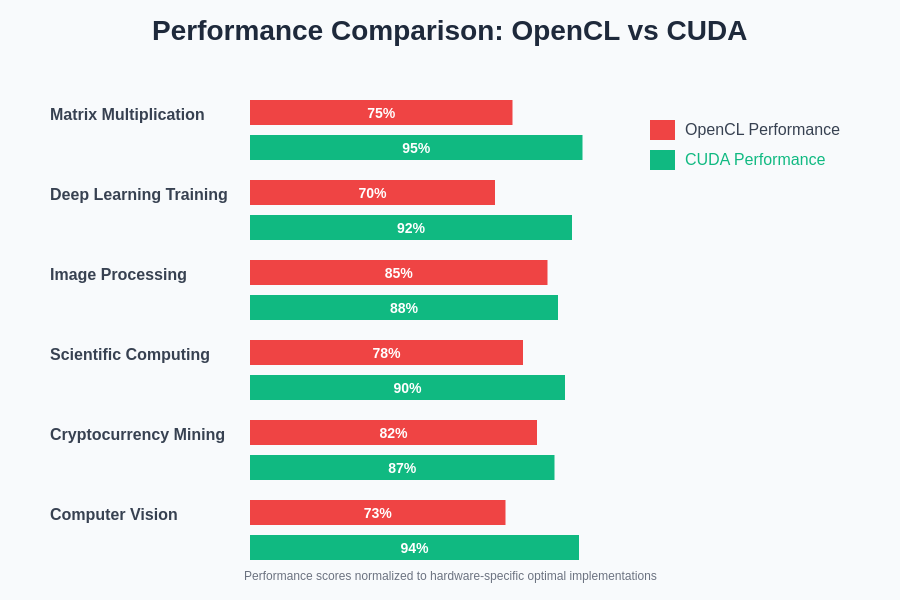
The performance characteristics vary significantly across different computational workloads, with CUDA showing particular strength in deep learning and matrix operations due to highly optimized libraries and tensor core utilization. OpenCL performance demonstrates more variability across platforms but can achieve competitive results on well-optimized implementations.
The optimization strategies available within each framework reflect their underlying design philosophies. CUDA provides extensive profiling tools, performance libraries, and hardware-specific optimization guides that enable developers to achieve near-optimal performance on supported platforms. OpenCL optimization requires more generic approaches that must account for potential execution across diverse hardware architectures, often resulting in more conservative optimization strategies that prioritize stability over maximum performance.
Development Ecosystem and Tool Support
The development ecosystem surrounding each framework significantly influences developer productivity, learning curve, and long-term maintainability of GPU-accelerated applications. CUDA benefits from NVIDIA’s substantial investment in developer tools, including comprehensive documentation, extensive sample code, educational resources, and a mature ecosystem of third-party libraries and frameworks. The CUDA toolkit provides integrated development environments, debugging tools, and performance profilers that streamline the development process.
OpenCL’s development ecosystem is more fragmented due to its vendor-neutral nature, with different hardware vendors providing their own implementations, tools, and optimization guidelines. While this diversity can provide flexibility, it also creates challenges in maintaining consistent development experiences across different platforms. The open standard nature of OpenCL has fostered community-driven development efforts, but the resources available often lag behind the comprehensive ecosystem that NVIDIA has built around CUDA.
The learning curve associated with each framework reflects these ecosystem differences. CUDA provides more structured educational pathways, extensive documentation, and mature debugging tools that can accelerate developer onboarding. OpenCL requires developers to navigate more diverse documentation sources and adapt to varying implementation characteristics across different platforms, potentially extending the learning curve for newcomers to GPU programming.
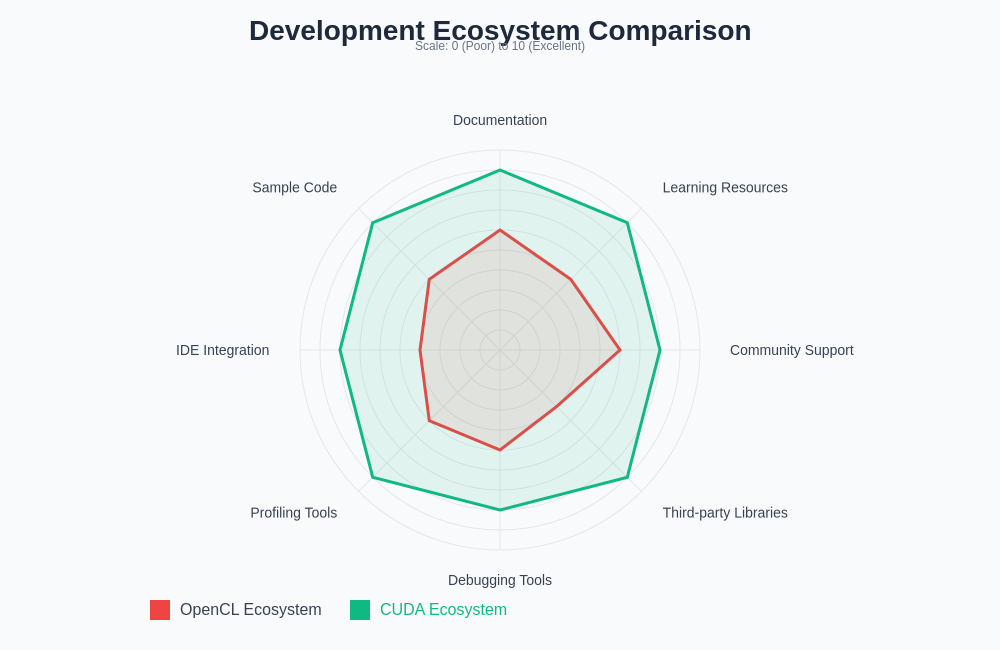
The radar chart visualization clearly demonstrates CUDA’s ecosystem advantages across multiple dimensions including documentation quality, learning resources, and third-party library availability. While OpenCL maintains competitive community support, the fragmented nature of its ecosystem creates challenges for developers seeking comprehensive development resources.
Hardware Compatibility and Platform Support
Hardware compatibility represents one of the most significant differentiators between OpenCL and CUDA, with implications that extend far beyond initial development considerations to encompass deployment strategies, hardware procurement decisions, and long-term application maintainability. CUDA’s exclusive compatibility with NVIDIA GPUs provides exceptional optimization opportunities but creates dependency on a single hardware vendor that may not align with all organizational requirements or budget constraints.
OpenCL’s cross-platform compatibility extends to GPUs from AMD, Intel, ARM, and other manufacturers, as well as alternative computing devices including CPUs and specialized accelerators. This broad compatibility enables organizations to select hardware based on cost, power consumption, or availability considerations rather than being constrained by software framework limitations. However, this flexibility comes with the complexity of managing potentially different performance characteristics and optimization requirements across various platforms.

The comprehensive platform support matrix demonstrates OpenCL’s advantage in hardware flexibility, supporting virtually every modern GPU architecture while CUDA remains exclusively tied to NVIDIA hardware. This fundamental difference in approach significantly influences deployment strategies and long-term technology decisions.
Leverage powerful research capabilities with Perplexity to stay informed about emerging GPU architectures and their compatibility with different parallel computing frameworks. The rapid evolution of GPU hardware continues to influence the comparative advantages of OpenCL and CUDA, with new architectures introducing capabilities that may favor one framework over another.
AI-Specific Considerations and Use Cases
The application of OpenCL and CUDA to artificial intelligence workloads reveals specific considerations that may not be immediately apparent in general-purpose parallel computing scenarios. Modern AI applications often involve complex computational graphs with varying levels of parallelism, irregular memory access patterns, and dynamic workload characteristics that challenge traditional GPU programming approaches.
CUDA’s AI ecosystem includes specialized libraries such as cuDNN for deep neural networks, cuBLAS for linear algebra operations, and NCCL for multi-GPU communication, providing highly optimized implementations of common AI operations. These libraries have been extensively tuned for NVIDIA hardware and often serve as the foundation for popular AI frameworks like TensorFlow and PyTorch. The availability of these optimized libraries can significantly accelerate AI development and deployment on NVIDIA platforms.
OpenCL implementations for AI workloads vary across different vendors, with some providing optimized libraries for common operations while others require more manual optimization efforts. The AMD ROCm platform, Intel oneAPI, and other vendor-specific implementations offer varying levels of AI-focused optimization, but the landscape remains more fragmented than NVIDIA’s comprehensive CUDA ecosystem.
Memory Management and Data Transfer Optimization
Efficient memory management represents a critical factor in GPU computing performance, particularly for AI applications that often involve large datasets and complex memory access patterns. CUDA provides sophisticated memory management capabilities including unified memory, memory pools, and fine-grained control over data transfers between host and device memory. These features enable developers to optimize memory usage patterns and minimize data transfer overhead that can bottleneck overall application performance.
OpenCL’s memory management model provides similar conceptual capabilities but with implementation variations across different platforms. The abstracted nature of OpenCL memory management can simplify cross-platform development but may limit access to platform-specific optimizations that could improve performance in particular scenarios. Understanding the memory hierarchy and optimization opportunities on each target platform becomes crucial for achieving optimal OpenCL performance.
The complexity of modern AI models often involves intricate memory access patterns that benefit from careful optimization of data layout, memory coalescing, and cache utilization. CUDA’s intimate hardware integration provides detailed control over these aspects, while OpenCL implementations must balance optimization opportunities with cross-platform compatibility requirements.
Debugging and Profiling Capabilities
Effective debugging and profiling tools are essential for developing and optimizing complex GPU applications, particularly in AI contexts where performance bottlenecks may not be immediately obvious. CUDA provides comprehensive debugging and profiling infrastructure including NVIDIA Nsight tools, CUDA-GDB debugger, and detailed performance profiling capabilities that can identify memory access patterns, kernel execution characteristics, and optimization opportunities.
OpenCL debugging and profiling capabilities vary significantly across different implementations, with each vendor providing their own tools and methodologies. While some platforms offer sophisticated debugging environments, others may require more manual approaches to performance analysis and optimization. This variability can complicate development workflows when targeting multiple platforms.
The complexity of modern AI applications often requires sophisticated profiling capabilities to identify performance bottlenecks across complex computational graphs involving multiple kernels, memory transfers, and synchronization points. The availability of mature profiling tools can significantly impact development efficiency and final application performance.
Integration with AI Frameworks and Libraries
The integration of GPU computing frameworks with popular AI development environments significantly influences their practical utility for machine learning applications. CUDA’s deep integration with major AI frameworks including TensorFlow, PyTorch, and others provides seamless acceleration for common operations without requiring direct GPU programming expertise from AI developers. This integration has been a major factor in CUDA’s widespread adoption in the AI community.
OpenCL integration with AI frameworks is less comprehensive, though several projects have worked to provide OpenCL backends for popular frameworks. The fragmented nature of OpenCL implementations can complicate these integration efforts, as framework developers must account for varying performance characteristics and feature availability across different platforms.
The trend toward higher-level AI development abstractions means that many developers may never directly interact with GPU programming frameworks, instead relying on framework-provided acceleration capabilities. However, understanding the underlying GPU computing characteristics remains valuable for performance optimization and troubleshooting complex applications.
Cost Considerations and Economic Factors
Economic factors play an increasingly important role in GPU computing decisions, particularly for organizations deploying AI applications at scale. NVIDIA GPUs optimized for CUDA often command premium pricing, especially for data center and high-performance computing applications. This cost structure may influence hardware selection decisions and total cost of ownership calculations for large-scale deployments.
OpenCL’s compatibility with diverse hardware options can provide greater flexibility in balancing performance requirements with budget constraints. Organizations may choose to utilize lower-cost GPU options from AMD or Intel while maintaining the ability to scale to higher-performance platforms as requirements evolve. However, the potential need for additional optimization work across different platforms must be considered in total development cost calculations.
The rapid evolution of GPU hardware and the emergence of specialized AI accelerators continues to influence the economic landscape of GPU computing. Organizations must balance immediate performance requirements with long-term flexibility and vendor relationship considerations when making framework and hardware selection decisions.
Future Trajectory and Emerging Trends
The future development of OpenCL and CUDA continues to be shaped by evolving AI workload characteristics, emerging hardware architectures, and changing industry dynamics. NVIDIA’s continued investment in CUDA development, including support for new hardware features and AI-specific optimizations, maintains the framework’s position as a leading choice for high-performance AI applications on NVIDIA hardware.
OpenCL’s future depends largely on continued vendor support and community development efforts to address the evolving requirements of modern parallel computing applications. Recent developments in OpenCL specifications and vendor implementations suggest ongoing evolution to meet contemporary performance and feature requirements, though the pace of development may not match NVIDIA’s focused CUDA investment.
The emergence of specialized AI hardware including tensor processing units, neuromorphic processors, and other domain-specific architectures introduces new considerations for framework selection. The ability of both OpenCL and CUDA to adapt to these evolving hardware landscapes will significantly influence their long-term relevance in the AI computing ecosystem.
Strategic Decision Framework
Selecting between OpenCL and CUDA for AI applications requires careful consideration of multiple factors including performance requirements, hardware constraints, development resources, long-term strategic goals, and total cost of ownership. Organizations with existing NVIDIA hardware investments and performance-critical applications may find CUDA’s optimized ecosystem provides the most direct path to achieving their objectives.
Conversely, organizations prioritizing vendor independence, hardware flexibility, or cost optimization may prefer OpenCL’s cross-platform capabilities despite potential complexity in optimization and development. The decision framework should also consider the availability of development expertise, integration requirements with existing systems, and anticipated evolution of hardware and software requirements over time.
The rapid pace of AI technology evolution suggests that framework selection decisions should maintain sufficient flexibility to adapt to changing requirements and emerging opportunities. Both OpenCL and CUDA continue to evolve in response to these changing needs, making ongoing evaluation of their relative advantages an important aspect of long-term technology strategy.
Disclaimer
This article provides general information about OpenCL and CUDA for educational purposes and does not constitute professional technical advice. The performance characteristics, capabilities, and suitability of different GPU computing frameworks depend on specific use cases, hardware configurations, and implementation requirements. Readers should conduct thorough evaluation and testing based on their specific needs and constraints. The rapidly evolving nature of GPU computing technology means that current information may become outdated, and readers should verify current specifications and capabilities when making technology decisions.