
The rapid advancement of artificial intelligence and machine learning applications has created an unprecedented demand for sophisticated data storage solutions capable of handling high-dimensional vector representations. Vector databases have emerged as the cornerstone technology enabling semantic search, recommendation systems, and AI-powered applications that require efficient similarity searches across massive datasets. In this comprehensive analysis, we examine two leading vector database solutions: Pinecone and Weaviate, exploring their architectures, performance characteristics, and suitability for different use cases in the modern AI landscape.
Discover the latest AI database trends to understand how vector databases are revolutionizing data storage and retrieval in artificial intelligence applications. The choice between vector database solutions can significantly impact application performance, development complexity, and operational costs, making this comparison crucial for organizations building AI-powered systems.
Understanding Vector Database Fundamentals
Vector databases represent a fundamental shift from traditional relational databases, designed specifically to store, index, and query high-dimensional vector embeddings efficiently. These databases excel at performing approximate nearest neighbor searches, enabling applications to find semantically similar content based on vector representations rather than exact keyword matches. The underlying mathematics involves complex distance calculations in multidimensional spaces, where traditional indexing methods prove inadequate for handling the scale and complexity of modern AI applications.
The emergence of transformer models and large language models has accelerated the adoption of vector databases, as these AI systems generate dense vector representations that capture semantic meaning across text, images, audio, and other data modalities. Vector databases provide the infrastructure necessary to store millions or billions of these embeddings while maintaining sub-second query response times, enabling real-time applications that depend on semantic similarity searches.
Pinecone: The Managed Vector Database Pioneer
Pinecone has established itself as a leading managed vector database service, designed from the ground up to provide developers with a turnkey solution for vector storage and retrieval. The platform abstracts away the complexities of vector indexing, scaling, and maintenance, allowing development teams to focus on building applications rather than managing infrastructure. Pinecone’s architecture emphasizes ease of use, automatic scaling, and consistent performance across varying workloads.
The platform’s design philosophy centers on providing a simple API interface that masks the underlying complexity of distributed vector indexing. Pinecone handles index creation, data ingestion, query processing, and scaling operations transparently, presenting developers with a straightforward interface for performing vector operations. This approach has made Pinecone particularly attractive to organizations seeking rapid deployment of vector-powered applications without extensive database administration overhead.
Pinecone’s technical architecture employs proprietary indexing algorithms optimized for cloud deployment, with automatic partitioning and replication across multiple availability zones. The service provides built-in monitoring, backup, and disaster recovery capabilities, ensuring high availability and data durability for production applications. The platform’s query engine is optimized for both accuracy and speed, utilizing advanced approximation algorithms that maintain search quality while achieving millisecond response times.
Weaviate: The Open-Source Vector Database Powerhouse
Weaviate represents a different approach to vector database architecture, providing an open-source solution that combines vector search capabilities with traditional database features. The platform integrates vector similarity search with structured data queries, enabling complex applications that require both semantic search and traditional filtering operations. Weaviate’s modular architecture allows for extensive customization and integration with various machine learning frameworks and embedding models.
Experience advanced AI capabilities with Claude for comprehensive analysis and development of vector database implementations. Weaviate’s open-source nature provides transparency and flexibility that appeals to organizations requiring fine-grained control over their database infrastructure and those operating in regulated environments where data sovereignty is paramount.
The platform’s architecture emphasizes flexibility and extensibility, with a plugin-based system that supports multiple vectorization modules, distance metrics, and indexing strategies. Weaviate can be deployed on-premises, in private clouds, or as a managed service, providing deployment flexibility that accommodates diverse organizational requirements. The platform’s GraphQL API provides a powerful query interface that enables complex queries combining vector search with traditional database operations.
Weaviate’s technical implementation utilizes the Hierarchical Navigable Small World (HNSW) algorithm for vector indexing, which provides excellent performance characteristics for approximate nearest neighbor searches. The platform supports multiple vector spaces within a single instance, enabling applications that work with different types of embeddings simultaneously. The system’s schema-based approach provides structure and validation for stored data while maintaining the flexibility required for diverse AI applications.
Performance Architecture and Scaling Characteristics
The performance characteristics of vector databases depend heavily on their underlying indexing strategies, memory management approaches, and distributed architecture designs. Pinecone’s managed infrastructure provides automatic scaling capabilities that adjust resources based on query load and data volume, ensuring consistent performance without manual intervention. The platform’s indexing strategy is optimized for cloud deployment, with sophisticated caching and query optimization techniques that minimize latency while maximizing throughput.
Pinecone’s performance architecture emphasizes predictable latency and throughput across varying workloads. The platform utilizes advanced load balancing and query routing algorithms that distribute queries across multiple nodes while maintaining index consistency. The service provides performance guarantees through service level agreements, ensuring that applications can rely on consistent response times even during peak usage periods.
Weaviate’s performance characteristics vary significantly based on deployment configuration and hardware resources. The platform provides extensive tuning options that allow administrators to optimize performance for specific use cases and workload patterns. Weaviate’s HNSW indexing implementation provides excellent query performance, particularly for high-dimensional vectors, but requires careful configuration to achieve optimal results.
The scalability approaches of these platforms differ fundamentally in their operational models. Pinecone handles scaling transparently through its managed service architecture, automatically provisioning additional resources and rebalancing data as needed. This approach minimizes operational overhead but limits control over scaling decisions and cost optimization strategies.
Query Capabilities and Search Features
Vector database query capabilities extend far beyond simple similarity searches, encompassing complex filtering, metadata queries, and hybrid search operations that combine vector similarity with traditional database queries. Pinecone provides a streamlined query interface focused on vector similarity operations with basic filtering capabilities. The platform’s query engine optimizes for speed and simplicity, providing efficient approximate nearest neighbor searches with configurable accuracy parameters.
Pinecone’s query capabilities include namespace-based organization, metadata filtering, and batch operations that enable efficient processing of multiple queries simultaneously. The platform’s API design emphasizes ease of use, with straightforward methods for ingesting vectors, performing queries, and managing indexes. The service provides real-time query statistics and performance metrics that help developers optimize their applications.
Weaviate offers more sophisticated query capabilities through its GraphQL interface, enabling complex queries that combine vector search with structured data operations. The platform supports advanced filtering, aggregation, and join operations that allow developers to build complex applications requiring both semantic search and traditional database functionality. Weaviate’s query language provides fine-grained control over search parameters, distance metrics, and result formatting.
The platform’s modular architecture enables custom query extensions and integration with external processing pipelines. Weaviate supports multiple vectorization strategies, allowing applications to work with different embedding models and vector spaces within the same database instance. The platform’s schema validation ensures data consistency while providing flexibility for evolving application requirements.
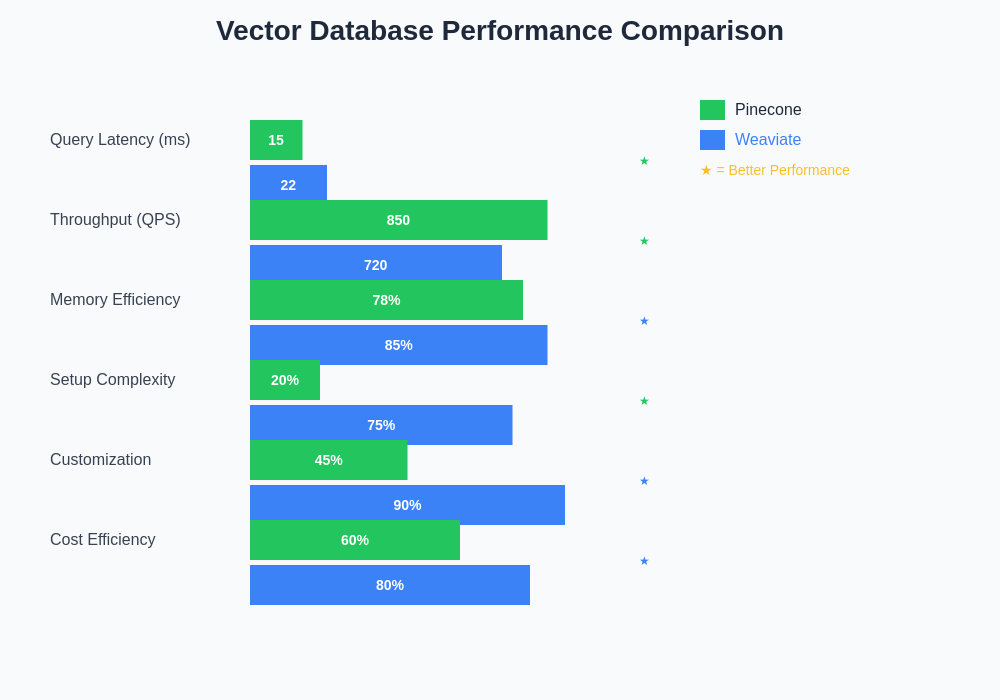
The performance characteristics of vector databases vary significantly across different metrics, with each platform optimizing for specific use cases and deployment scenarios. Query latency, throughput capacity, and scaling efficiency represent critical factors that influence application performance and user experience. Pinecone demonstrates consistent advantages in simplicity and managed scaling, while Weaviate excels in customization capabilities and memory efficiency.
Integration Ecosystem and Developer Experience
The integration ecosystem surrounding vector databases significantly impacts development velocity and application capabilities. Pinecone provides extensive integration libraries for popular programming languages, with official SDKs for Python, JavaScript, Java, and other major development platforms. The platform’s documentation emphasizes quick start guides and practical examples that enable rapid prototype development and production deployment.
Pinecone’s developer experience focuses on simplicity and reliability, with comprehensive error handling, automatic retry mechanisms, and detailed logging capabilities. The platform provides monitoring dashboards and analytics tools that help developers understand query patterns, optimize performance, and troubleshoot issues. The service’s managed nature eliminates the need for database administration skills, making it accessible to application developers without specialized vector database expertise.
Weaviate’s integration ecosystem reflects its open-source heritage, with community-contributed libraries and extensions that provide integration with various machine learning frameworks and data processing pipelines. The platform’s modular architecture enables custom integrations and extensions that can be tailored to specific organizational requirements. Weaviate’s documentation provides comprehensive coverage of configuration options and deployment scenarios, though it requires more technical expertise to implement effectively.
The platform’s open-source nature enables deep customization and integration with existing infrastructure, but requires more operational overhead compared to managed solutions. Weaviate’s community provides active support and continuous development of new features, but organizations must invest in learning and maintaining the platform independently.
Enhance your research capabilities with Perplexity for comprehensive analysis of vector database implementations and optimization strategies. The choice between managed and self-hosted solutions involves tradeoffs between control, cost, and operational complexity that vary based on organizational priorities and technical capabilities.
Cost Structure and Economic Considerations
The economic implications of vector database selection extend beyond initial licensing costs to encompass operational overhead, scaling expenses, and total cost of ownership over time. Pinecone’s pricing model follows a consumption-based approach, charging based on index size, query volume, and performance requirements. This model provides predictable costs for stable workloads but can become expensive for applications with high query volumes or large vector datasets.
Pinecone’s managed service model eliminates infrastructure costs and operational overhead, but the premium pricing reflects the value of automated management and guaranteed performance. The platform’s automatic scaling capabilities help optimize costs by adjusting resources based on actual usage, though organizations have limited control over scaling decisions and cost optimization strategies.
Weaviate’s open-source licensing eliminates software costs but transfers operational responsibility to the organization. The total cost of ownership includes infrastructure expenses, operational overhead, and the internal expertise required to deploy and maintain the platform effectively. Organizations with existing database administration capabilities may achieve lower costs with Weaviate, while those lacking specialized expertise may find managed solutions more cost-effective overall.
The economic decision between these platforms depends heavily on organizational priorities, technical capabilities, and usage patterns. High-volume applications may benefit from Weaviate’s self-hosted deployment options, while organizations prioritizing rapid deployment and minimal operational overhead may prefer Pinecone’s managed approach.
Security and Compliance Frameworks
Security considerations play a crucial role in vector database selection, particularly for organizations handling sensitive data or operating in regulated industries. Pinecone provides enterprise-grade security features including encryption at rest and in transit, network isolation, and comprehensive access controls. The platform’s managed infrastructure includes regular security updates, vulnerability patches, and compliance certifications that reduce security overhead for customer organizations.
Pinecone’s security model includes fine-grained access controls, API key management, and audit logging capabilities that support compliance requirements. The platform provides data residency options and privacy controls that help organizations meet regulatory requirements while maintaining performance and functionality. The service’s security monitoring and incident response capabilities provide additional protection for production deployments.
Weaviate’s security framework provides comprehensive controls for self-hosted deployments, including authentication modules, authorization policies, and encryption capabilities. The platform’s open-source nature enables security auditing and customization, allowing organizations to implement specific security requirements and compliance controls. However, the responsibility for security implementation and maintenance rests entirely with the deploying organization.
The platform supports various authentication mechanisms, including integration with existing identity management systems and custom authentication modules. Weaviate’s modular architecture enables the implementation of custom security policies and compliance controls that align with organizational requirements and regulatory obligations.
Real-World Performance Benchmarks
Performance evaluation of vector databases requires comprehensive testing across diverse scenarios, including varying vector dimensions, dataset sizes, and query patterns. Independent benchmarks have demonstrated that both Pinecone and Weaviate provide excellent performance for their respective deployment models, though optimal performance requires appropriate configuration and tuning for specific use cases.
Pinecone consistently delivers low-latency query responses across varying load conditions, with the managed infrastructure automatically optimizing performance based on usage patterns. The platform’s performance remains stable even during traffic spikes, though query costs increase proportionally with volume. Pinecone’s indexing strategy provides good recall accuracy while maintaining fast query times, making it suitable for applications requiring consistent performance guarantees.
Weaviate’s performance characteristics depend heavily on deployment configuration, hardware resources, and tuning parameters. Properly configured Weaviate deployments can achieve excellent performance, particularly for applications requiring complex queries combining vector search with structured data operations. The platform’s HNSW indexing provides superior performance for high-dimensional vectors, though optimal results require expertise in configuration and tuning.
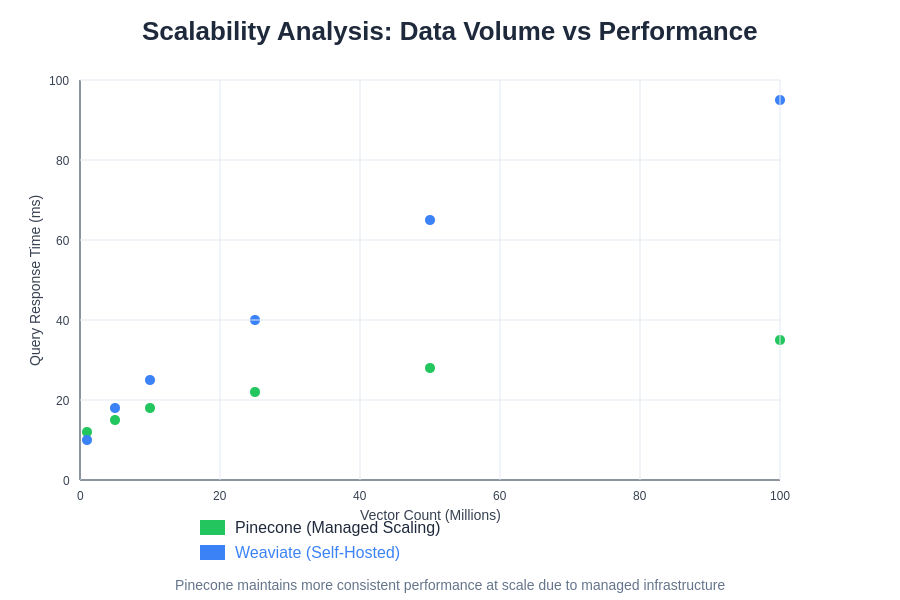
The scalability patterns of vector databases reveal significant differences in how each platform handles increasing data volumes and query loads. Pinecone’s managed infrastructure maintains more predictable performance curves as data volume increases, while Weaviate’s performance characteristics depend heavily on configuration and hardware optimization. Understanding these patterns is essential for selecting the appropriate solution for specific application requirements and growth projections.

The architectural philosophies of Pinecone and Weaviate reflect fundamentally different approaches to vector database deployment and management. Pinecone’s managed service architecture prioritizes simplicity and operational efficiency, while Weaviate’s modular open-source design emphasizes flexibility and customization capabilities.
Use Case Optimization and Application Scenarios
Different vector database platforms excel in specific application scenarios, making use case analysis crucial for optimal platform selection. Pinecone’s managed service model provides excellent value for applications requiring rapid deployment, predictable performance, and minimal operational overhead. The platform is particularly well-suited for startups, development teams without database expertise, and applications with moderate scale requirements.
Pinecone excels in scenarios requiring semantic search, recommendation systems, and content discovery applications where query performance and development velocity are prioritized over cost optimization. The platform’s automatic scaling capabilities make it ideal for applications with unpredictable traffic patterns or rapid growth requirements.
Weaviate’s flexibility and extensibility make it optimal for complex applications requiring sophisticated query capabilities, custom integrations, and fine-grained control over database behavior. The platform is particularly valuable for organizations with existing database expertise, those requiring specific compliance controls, or applications needing custom vectorization strategies.
Enterprise applications requiring hybrid search capabilities, complex data relationships, and integration with existing infrastructure often benefit from Weaviate’s comprehensive feature set and deployment flexibility. The platform’s open-source nature enables customization and optimization for specific organizational requirements that may not be achievable with managed solutions.
Future Development Trajectories and Innovation
The vector database landscape continues evolving rapidly, with both Pinecone and Weaviate pursuing different innovation strategies that reflect their architectural philosophies and market positioning. Pinecone’s development focus emphasizes ease of use, performance optimization, and feature completeness within their managed service model. The company continues investing in advanced indexing algorithms, query optimization, and integration capabilities that enhance developer productivity.
Pinecone’s roadmap includes expanded support for multimodal vectors, improved cost optimization features, and enhanced analytics capabilities that provide deeper insights into application usage patterns. The platform’s managed service approach enables rapid deployment of new features without requiring customer intervention or maintenance windows.
Weaviate’s open-source development model enables rapid innovation through community contributions and collaborative development. The platform’s roadmap emphasizes expanding vectorization modules, improving query capabilities, and enhancing scalability features. The community-driven approach enables experimentation with cutting-edge research and rapid adoption of new techniques in vector indexing and retrieval.
The platform’s modular architecture provides a foundation for continuous innovation in areas such as hybrid AI models, advanced query languages, and integration with emerging machine learning frameworks. Weaviate’s development approach enables organizations to influence platform evolution and contribute specialized features that benefit the broader community.
Strategic Decision Framework
Selecting between Pinecone and Weaviate requires careful consideration of organizational priorities, technical capabilities, and application requirements. The decision framework should encompass immediate needs, long-term scalability requirements, and total cost of ownership considerations. Organizations prioritizing rapid deployment, predictable performance, and minimal operational overhead may find Pinecone’s managed service approach optimal for their requirements.
Teams with specialized database expertise, specific customization needs, or cost optimization priorities may benefit from Weaviate’s flexibility and open-source licensing model. The decision should also consider the organization’s comfort level with operational responsibility, security requirements, and integration complexity.
The strategic implications of vector database selection extend beyond immediate technical requirements to encompass vendor relationships, technology roadmaps, and organizational capabilities. The rapid evolution of AI technologies requires vector database platforms that can adapt to changing requirements and emerging use cases while maintaining performance and reliability.
Both platforms provide viable solutions for different organizational contexts, and the optimal choice depends on carefully balancing technical requirements, operational capabilities, and strategic objectives. The vector database landscape will continue evolving, and organizations should consider how their chosen platform aligns with long-term technology strategies and business objectives.
Disclaimer
This article provides informational analysis based on publicly available information and general industry knowledge. Performance characteristics, pricing models, and feature sets may vary based on specific configurations, usage patterns, and service agreements. Organizations should conduct thorough evaluations and testing with their specific requirements before making platform decisions. The effectiveness of vector database solutions depends on proper implementation, configuration, and optimization for specific use cases and organizational contexts.