
The relentless pursuit of artificial intelligence capabilities has created an unprecedented demand for computational power, driving innovation in specialized hardware designed to handle the massive parallel processing requirements of machine learning workloads. However, as AI applications proliferate across data centers, edge devices, and mobile platforms, power efficiency has emerged as a critical factor that determines not only operational costs but also the practical feasibility of deploying AI solutions at scale. The metric of watts per TOPS (Tera Operations Per Second) has become the gold standard for evaluating the energy efficiency of AI accelerators, providing a quantifiable measure that enables meaningful comparisons across different architectures and manufacturers.
The significance of power efficiency in AI extends far beyond simple cost considerations. In data center environments where thousands of AI accelerators operate simultaneously, even marginal improvements in watts per TOPS can translate to millions of dollars in annual energy savings and substantially reduced carbon footprints. For edge computing applications, power efficiency directly impacts battery life, thermal management requirements, and the ability to deploy AI capabilities in resource-constrained environments. Explore the latest developments in AI hardware trends to understand how manufacturers are pushing the boundaries of energy-efficient computing while maintaining performance leadership.
Understanding the TOPS Metric and Its Relevance
TOPS represents the number of trillion operations that a processor can execute per second, serving as a fundamental benchmark for measuring the raw computational throughput of AI-specific workloads. However, the interpretation of TOPS requires careful consideration of the underlying data precision, operation types, and architectural optimizations that influence real-world performance. Modern AI accelerators support various numerical precisions, including FP32, FP16, INT8, and even lower bit-width operations, with each precision level offering different trade-offs between accuracy and computational efficiency.
The relationship between TOPS and actual AI inference performance depends heavily on the specific neural network architecture, the degree of quantization applied, and the efficiency of the hardware’s memory subsystem. While higher TOPS values generally indicate superior computational capability, the practical benefits can only be realized when the hardware architecture effectively utilizes available computational resources without being bottlenecked by memory bandwidth, cache efficiency, or inter-chip communication latencies.
Contemporary AI workloads encompass a diverse range of computational patterns, from the highly parallel matrix multiplications that dominate transformer-based language models to the more complex control flows found in reinforcement learning algorithms. The most effective AI accelerators demonstrate strong performance across this spectrum of workloads while maintaining consistent power efficiency characteristics that enable predictable operational costs and thermal management strategies.
Leading AI Chip Architectures and Their Efficiency Profiles
The landscape of AI accelerators encompasses several distinct architectural approaches, each with unique characteristics that influence power efficiency metrics. NVIDIA’s latest generation of GPUs, including the H100 and A100 series, have established benchmarks for high-performance AI training and inference, achieving impressive TOPS ratings while maintaining relatively efficient power utilization through architectural innovations such as sparsity support, advanced tensor cores, and sophisticated power management systems.
AMD’s Instinct series and Intel’s emerging AI accelerator lineup represent significant challenges to NVIDIA’s dominance, offering alternative architectural philosophies that prioritize different aspects of the power-performance equation. AMD’s approach emphasizes memory bandwidth and multi-chip module designs that can distribute workloads across multiple processing units, while Intel’s solutions leverage the company’s manufacturing expertise and ecosystem integration advantages to deliver competitive efficiency metrics.
Discover advanced AI capabilities and tools that complement hardware efficiency improvements with software optimizations designed to maximize the utilization of available computational resources. The synergy between efficient hardware and intelligent software optimization strategies creates multiplicative benefits that extend well beyond the raw specifications of individual components.
Apple’s M-series chips with dedicated Neural Engine units exemplify the integration of AI acceleration into general-purpose processors, achieving remarkable power efficiency for inference workloads by co-locating AI processing units with high-bandwidth memory and optimized data paths. This integrated approach demonstrates how architectural decisions made at the system level can significantly impact overall power efficiency, even when individual components might not achieve the highest absolute TOPS ratings.
Emerging players in the AI accelerator market, including Graphcore, Cerebras, and various RISC-V based solutions, are challenging established paradigms with novel architectural approaches that prioritize specific aspects of AI workloads. These innovative designs often achieve superior watts per TOPS metrics for particular application domains by sacrificing generality in favor of highly optimized execution paths tailored to specific neural network topologies or computational patterns.
Data Center AI: Balancing Performance and Power Consumption
Data center deployment of AI accelerators presents unique challenges that extend beyond simple watts per TOPS comparisons to encompass broader considerations of cooling infrastructure, power distribution, and operational reliability. The most efficient data center AI solutions optimize not only the energy consumption of individual processors but also the supporting infrastructure required to maintain optimal operating conditions and ensure consistent performance under varying workload patterns.
Modern data centers hosting AI workloads must carefully balance computational density with thermal management requirements, as the most power-efficient chips often enable higher rack densities that can strain existing cooling systems. The relationship between chip-level efficiency and system-level power consumption becomes particularly complex when considering factors such as memory subsystem power, interconnect energy requirements, and the overhead associated with distributed training across multiple accelerators.
Advanced power management features, including dynamic voltage and frequency scaling, clock gating, and workload-aware power states, enable contemporary AI accelerators to adapt their energy consumption patterns to match computational demands. These capabilities are essential for maintaining optimal efficiency across the diverse range of workloads encountered in production AI systems, from batch inference processing that can tolerate higher latency for improved efficiency to real-time applications that require consistent low-latency responses regardless of power implications.
The economics of data center AI deployment increasingly favor solutions that demonstrate superior long-term efficiency characteristics rather than peak performance metrics. Organizations deploying large-scale AI infrastructure must consider the total cost of ownership, including initial hardware acquisition, ongoing energy costs, cooling infrastructure requirements, and the operational complexity associated with managing diverse hardware platforms.
Edge Computing: Power Efficiency as a Primary Design Constraint
Edge computing environments impose stringent power constraints that fundamentally alter the optimization priorities for AI accelerators, making watts per TOPS the primary consideration rather than a secondary metric. Mobile devices, IoT sensors, and embedded systems require AI capabilities that operate within severe power budgets while maintaining acceptable performance levels for real-time applications such as computer vision, natural language processing, and sensor fusion.
The challenge of edge AI power efficiency extends beyond the computational cores to encompass the entire system architecture, including memory hierarchies, input/output interfaces, and communication subsystems. Successful edge AI solutions achieve remarkable efficiency through careful co-design of hardware and software components, optimizing data movement patterns, minimizing external memory accesses, and leveraging specialized execution units that excel at specific types of AI operations.
Neuromorphic computing approaches represent an emerging paradigm for ultra-low-power AI applications, mimicking the energy-efficient processing patterns found in biological neural networks. These architectures achieve exceptional watts per TOPS metrics for certain classes of AI workloads by fundamentally rethinking the computational model, using event-driven processing, sparse activation patterns, and local learning algorithms that minimize global data movement and synchronization overhead.
Access comprehensive AI research and development resources to stay informed about emerging edge AI technologies and optimization techniques that enable sophisticated AI capabilities in power-constrained environments. The rapid evolution of edge AI hardware requires continuous learning and adaptation to leverage the latest efficiency improvements and architectural innovations.
Architectural Innovations Driving Efficiency Improvements
The pursuit of improved watts per TOPS performance has catalyzed numerous architectural innovations that extend far beyond traditional approaches to processor design. Sparsity support, which exploits the natural sparsity patterns found in many neural networks, enables significant efficiency gains by skipping computations involving zero-valued weights or activations. This approach can reduce both computational requirements and memory bandwidth demands, resulting in multiplicative efficiency improvements for suitable workloads.
Mixed-precision computing capabilities allow modern AI accelerators to dynamically select the most appropriate numerical precision for different layers or operations within a neural network, balancing accuracy requirements with computational efficiency. By performing less critical computations at lower precision while maintaining higher precision for sensitive operations, these systems achieve optimal trade-offs between quality and energy consumption.
Advanced memory hierarchies, including high-bandwidth memory integration, sophisticated caching strategies, and near-data processing capabilities, address the memory wall challenge that limits the efficiency of many AI workloads. By minimizing data movement between computational units and memory subsystems, these architectural features enable higher utilization of available computational resources while reducing overall power consumption.
Specialized functional units designed for specific AI operations, such as matrix multiplication accelerators, activation function processors, and normalization engines, achieve superior efficiency compared to general-purpose computational units. The proliferation of these specialized components reflects the maturation of AI workload understanding and the ability to optimize hardware for well-characterized computational patterns.
Manufacturing Process and Power Efficiency Correlations
The relationship between semiconductor manufacturing processes and AI chip power efficiency represents a critical factor that influences the competitive landscape of AI accelerators. Advanced process nodes, including 7nm, 5nm, and emerging 3nm technologies, enable higher transistor densities and improved switching characteristics that directly contribute to better watts per TOPS metrics through reduced leakage currents and enhanced performance per unit area.
However, the benefits of advanced manufacturing processes must be balanced against increased costs, design complexity, and potential yield challenges that can impact the economic viability of AI accelerator products. Leading manufacturers have demonstrated that careful optimization of circuit design, layout techniques, and power delivery systems can achieve significant efficiency improvements even within established process nodes, suggesting that architectural innovation remains as important as manufacturing advancement.
The integration of advanced packaging technologies, including chiplet designs, through-silicon vias, and heterogeneous integration approaches, enables AI accelerator designers to optimize different functional blocks using the most appropriate manufacturing processes and materials. This approach can achieve system-level efficiency improvements that exceed the capabilities of monolithic designs while maintaining cost-effectiveness and manufacturing scalability.
Thermal Management and Sustained Performance Considerations
The relationship between power efficiency and thermal management represents a critical consideration for practical AI accelerator deployment, as sustained performance depends heavily on the ability to dissipate heat generated during intensive computational workloads. Even highly efficient AI chips can experience performance throttling when thermal limits are exceeded, effectively reducing their practical TOPS ratings and degrading overall system efficiency.
Advanced thermal management techniques, including sophisticated heat spreader designs, liquid cooling solutions, and intelligent thermal throttling algorithms, enable AI accelerators to maintain peak performance levels for extended periods. The most effective solutions integrate thermal considerations into the chip architecture itself, using techniques such as thermal-aware workload scheduling, distributed processing to minimize hotspots, and dynamic voltage scaling to reduce heat generation during less demanding operations.
The correlation between chip power efficiency and cooling requirements creates a multiplicative effect on system-level energy consumption, as more efficient chips require less cooling infrastructure and can operate at higher densities without thermal constraints. This relationship makes watts per TOPS improvements particularly valuable in large-scale deployments where cooling costs represent a significant portion of total operational expenses.
Software Optimization and Hardware Efficiency Synergies
The practical realization of optimal watts per TOPS performance requires sophisticated software optimization strategies that complement hardware capabilities through intelligent workload management, efficient memory utilization patterns, and adaptive algorithm implementations. Modern AI frameworks incorporate hardware-aware optimizations that automatically adjust computational strategies based on the capabilities and constraints of target accelerators, maximizing efficiency without requiring extensive manual tuning.
Compiler technologies specifically designed for AI workloads play crucial roles in achieving optimal hardware utilization by analyzing neural network topologies, identifying optimization opportunities, and generating highly efficient code that leverages specialized hardware features. These tools can automatically implement techniques such as operator fusion, memory layout optimization, and precision selection that significantly impact real-world efficiency metrics.
Runtime optimization systems enable dynamic adaptation to changing workload characteristics and system conditions, adjusting execution strategies to maintain optimal efficiency across diverse operational scenarios. These capabilities are particularly important for production AI systems that must handle varying input characteristics, fluctuating performance requirements, and changing resource availability while maintaining consistent power efficiency profiles.
Future Trends and Emerging Technologies
The evolution of AI accelerator power efficiency continues to accelerate through emerging technologies and novel architectural approaches that promise to further improve watts per TOPS metrics while expanding the capabilities of AI systems. Photonic computing represents a potentially transformative technology that could achieve unprecedented efficiency levels for specific types of AI operations by leveraging the inherent parallelism and low energy requirements of optical processing.
Quantum-classical hybrid approaches offer potential advantages for certain classes of optimization problems and machine learning algorithms, though practical implementations remain in early research phases. The development of quantum processing units optimized for AI workloads could eventually provide efficiency advantages for problems that map well to quantum computational models.
Advanced materials research, including carbon nanotube transistors, graphene-based components, and novel semiconductor compounds, may enable future generations of AI accelerators to achieve efficiency improvements that exceed the limitations of traditional silicon-based technologies. These materials offer theoretical advantages in terms of switching speed, power consumption, and thermal characteristics that could translate to substantial improvements in watts per TOPS metrics.
The integration of AI capabilities directly into memory systems, including processing-in-memory and near-data computing approaches, represents another promising direction for efficiency improvements. By eliminating or reducing data movement requirements, these architectures can achieve significant energy savings while enabling new computational paradigms that better match the characteristics of AI workloads.
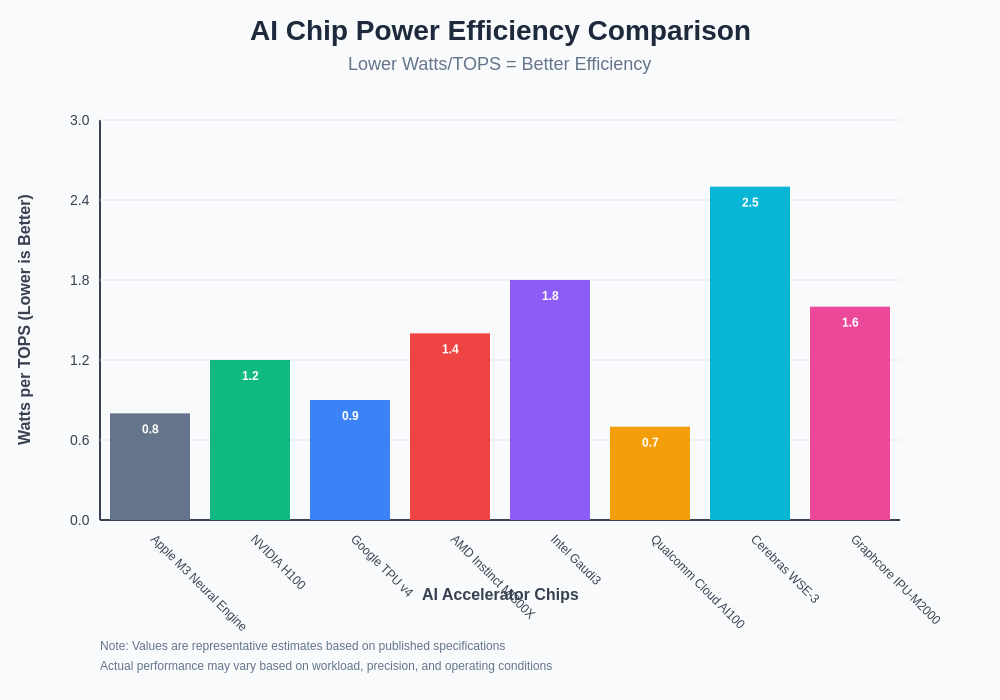
The competitive landscape of AI accelerators demonstrates significant variation in power efficiency across different architectures, manufacturers, and application domains. Understanding these differences enables informed decision-making for AI infrastructure investments and highlights the importance of matching accelerator capabilities to specific workload requirements. The chart reveals that specialized chips like Apple’s Neural Engine and Google’s TPU achieve superior watts per TOPS ratios compared to general-purpose solutions, though the latter often provide higher absolute performance levels.
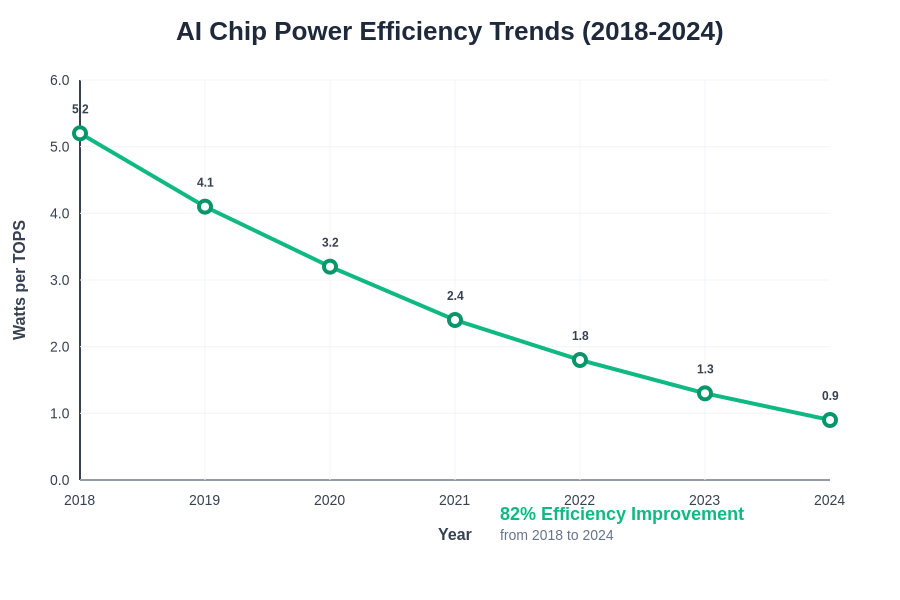
The historical progression of AI accelerator power efficiency reveals consistent improvement trends driven by manufacturing advances, architectural innovations, and software optimization developments. The remarkable 82% improvement from 2018 to 2024 demonstrates the industry’s commitment to energy-efficient AI computing, with each generation of chips delivering substantially better performance per watt consumed.
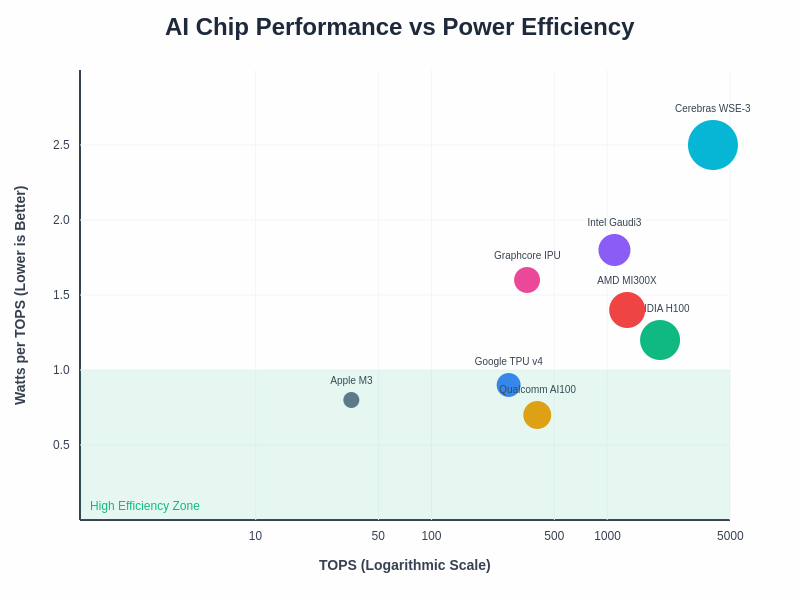
The relationship between raw computational performance and power efficiency creates distinct categories of AI accelerators optimized for different deployment scenarios. High-efficiency chips excel in edge computing applications where power constraints dominate, while high-performance solutions remain essential for data center workloads that prioritize computational throughput over energy consumption.
The continued advancement of power-efficient AI accelerators represents a critical enabler for the broader adoption of artificial intelligence across diverse applications and deployment scenarios. As the industry matures and workload characteristics become better understood, the focus on watts per TOPS optimization will likely intensify, driving further innovations that make AI capabilities more accessible, cost-effective, and environmentally sustainable.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The performance metrics and comparisons presented are based on publicly available information and may not reflect the latest product specifications or real-world performance characteristics. Readers should conduct their own research and testing when evaluating AI accelerator options for specific applications. Power efficiency measurements can vary significantly based on workload characteristics, system configuration, and operational conditions.