
The exponential growth of artificial intelligence applications has created an unprecedented demand for vast amounts of training data, yet this requirement directly conflicts with increasingly stringent privacy regulations and growing concerns about data sovereignty. Federated learning has emerged as a revolutionary paradigm that addresses this fundamental tension by enabling machine learning models to be trained across decentralized data sources without requiring centralized data collection or storage. This innovative approach represents a paradigmatic shift from traditional centralized learning methodologies, offering organizations the ability to harness collective intelligence while maintaining strict data privacy and regulatory compliance.
Discover the latest developments in AI privacy technologies to understand how federated learning is reshaping the landscape of responsible AI development. The convergence of privacy-preserving techniques with advanced machine learning capabilities has opened new frontiers for collaborative AI development that respects individual privacy rights while enabling breakthrough innovations across industries ranging from healthcare and finance to telecommunications and autonomous systems.
Fundamentals of Federated Learning Architecture
Federated learning fundamentally reimagines the traditional machine learning pipeline by distributing the training process across multiple edge devices or institutional boundaries while keeping raw data localized at its source. This decentralized approach operates on the principle that model parameters, rather than raw data, are shared and aggregated to create a global model that benefits from the collective knowledge of all participating entities. The architecture typically involves a central coordination server that orchestrates the training process, manages model aggregation, and distributes updated global models back to participating clients.
The federated learning ecosystem consists of several critical components that work in harmony to ensure effective model training while maintaining privacy guarantees. Edge devices or participating organizations maintain their local datasets and perform model training using locally available computational resources. The central aggregation server coordinates training rounds, collects model updates from participants, and applies sophisticated aggregation algorithms to combine these updates into an improved global model. Communication protocols ensure efficient and secure transmission of model parameters while minimizing bandwidth requirements and protecting against various attack vectors.
The iterative nature of federated learning involves multiple rounds of local training followed by global aggregation, creating a continuous improvement cycle that gradually enhances model performance across all participants. Each training round begins with participants downloading the current global model, performing local training on their private datasets, and uploading only the computed gradients or model parameters to the central server. This process continues until convergence criteria are met or predetermined training objectives are achieved, resulting in a globally optimized model that incorporates insights from all participating data sources without compromising individual privacy.
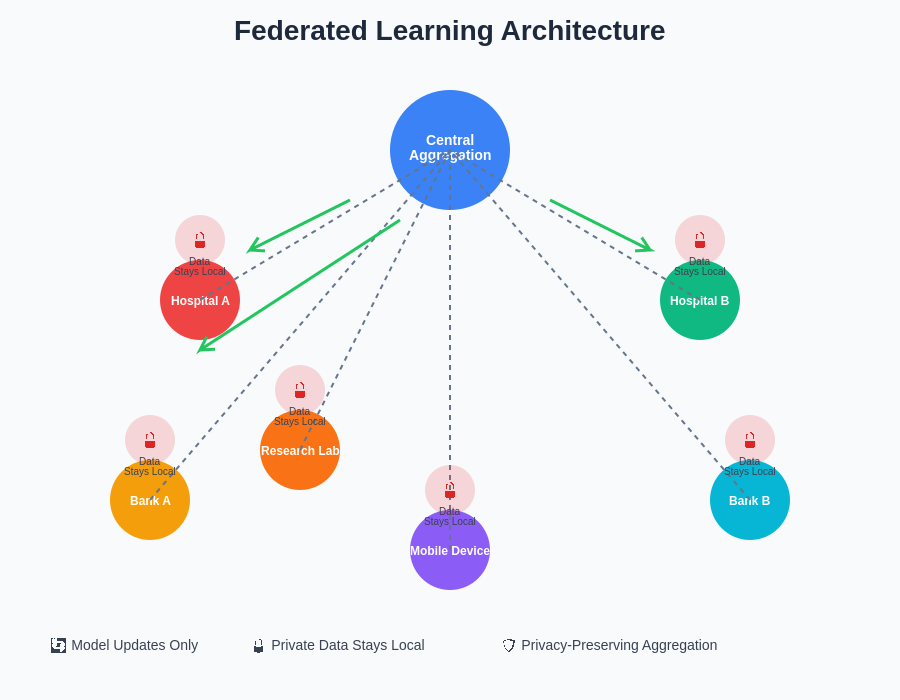
The distributed architecture of federated learning systems demonstrates how multiple organizations can collaborate on machine learning projects while maintaining strict data sovereignty and privacy controls. Each participating entity retains full control over their local datasets while contributing to the development of globally beneficial AI models through secure parameter sharing mechanisms.
Privacy-Preserving Mechanisms in Federated Systems
The implementation of robust privacy-preserving mechanisms represents the cornerstone of effective federated learning systems, requiring sophisticated techniques that protect sensitive information throughout the entire training lifecycle. Differential privacy has emerged as one of the most mathematically rigorous approaches to privacy preservation, providing quantifiable privacy guarantees by adding carefully calibrated noise to model updates before transmission. This technique ensures that the contribution of any individual data point cannot be reliably determined from the resulting model updates, even by adversaries with extensive background knowledge.
Experience advanced AI privacy solutions with Claude to understand how cutting-edge differential privacy techniques can be integrated into your federated learning implementations. The application of differential privacy in federated settings requires careful consideration of privacy budget allocation, noise scaling mechanisms, and the trade-offs between privacy guarantees and model utility. Advanced implementations utilize composition theorems and privacy accounting methods to optimize privacy budget utilization across multiple training rounds while maintaining acceptable model performance.
Secure multi-party computation protocols provide another layer of privacy protection by enabling participants to jointly compute model aggregations without revealing individual contributions. These cryptographic techniques utilize advanced mathematical constructions such as secret sharing, homomorphic encryption, and secure aggregation protocols to perform computations on encrypted data. The implementation of secure aggregation ensures that even the central coordination server cannot access individual model updates, providing protection against both external adversaries and potential server compromise scenarios.
Homomorphic encryption techniques enable computations to be performed directly on encrypted model parameters, ensuring that sensitive information remains protected throughout the aggregation process. These advanced cryptographic methods allow for complex mathematical operations to be executed on encrypted data while producing encrypted results that, when decrypted, match the outcomes of performing the same operations on plaintext data. The integration of homomorphic encryption into federated learning systems provides strong security guarantees but requires careful optimization to manage computational overhead and communication costs.
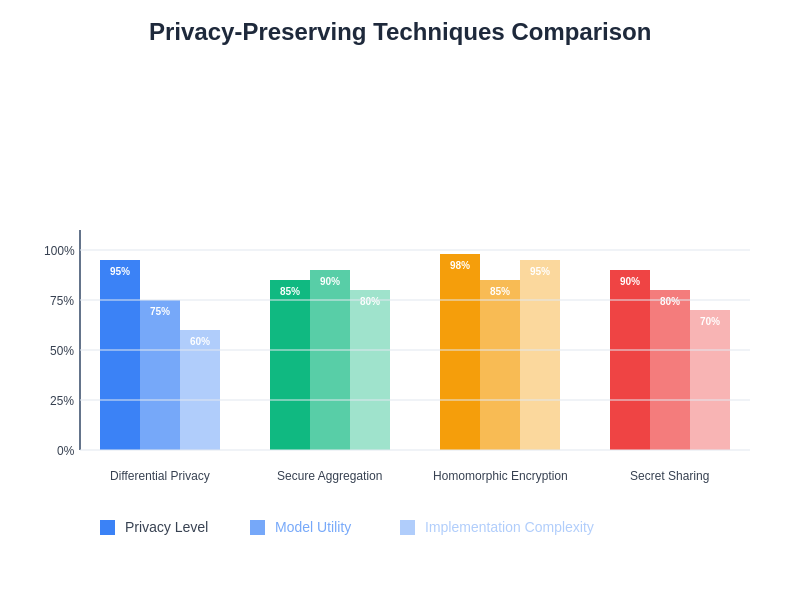
The comparative analysis of privacy-preserving techniques reveals the trade-offs between privacy guarantees, model utility, and implementation complexity that organizations must consider when designing federated learning systems. Each approach offers distinct advantages and challenges that must be carefully evaluated based on specific use case requirements and regulatory constraints.
Decentralized Learning Architectures
The evolution of federated learning has given rise to increasingly sophisticated decentralized architectures that eliminate single points of failure and reduce dependence on centralized coordination mechanisms. Peer-to-peer federated learning networks enable direct communication between participating devices, creating resilient systems that can continue operating even when individual nodes become unavailable. These decentralized topologies utilize gossip protocols, blockchain-based coordination mechanisms, and distributed consensus algorithms to achieve model synchronization without requiring centralized oversight.
Blockchain-integrated federated learning systems provide immutable audit trails for training processes while enabling decentralized governance and incentive mechanisms. Smart contracts can automate participant verification, model validation, and reward distribution, creating trustless environments where participants can contribute to collaborative learning without requiring mutual trust relationships. The integration of blockchain technology also enables the implementation of reputation systems that encourage high-quality contributions while discouraging malicious behavior.
Hierarchical federated learning architectures address scalability challenges by organizing participants into clusters or tiers, enabling more efficient communication patterns and reducing coordination overhead. These multi-level systems can optimize bandwidth utilization by performing local aggregation within clusters before contributing to higher-level global aggregation processes. Edge computing integration enables processing to occur closer to data sources, reducing latency and improving real-time responsiveness for applications requiring immediate model updates.
Advanced Aggregation Techniques
The effectiveness of federated learning systems depends heavily on sophisticated aggregation algorithms that can combine diverse model updates while maintaining training stability and convergence properties. Federated averaging represents the foundational aggregation approach, computing weighted averages of model parameters based on the relative sizes of local datasets. However, advanced implementations require more nuanced approaches that account for data heterogeneity, varying computational capabilities, and potential adversarial contributions.
Robust aggregation mechanisms protect against Byzantine failures and malicious participants by implementing statistical techniques that identify and filter anomalous contributions. These methods utilize median-based aggregation, trimmed mean calculations, and outlier detection algorithms to ensure that model quality is maintained even when a subset of participants provides corrupted or adversarial updates. Advanced robust aggregation techniques can maintain training effectiveness even when significant percentages of participants exhibit malicious behavior.
Adaptive aggregation algorithms dynamically adjust aggregation weights based on participant reliability, data quality metrics, and historical contribution patterns. These intelligent systems can learn to identify high-quality contributors and assign appropriate influence levels to their updates, improving overall model quality while maintaining fairness across participants. Machine learning techniques are increasingly being applied to optimize aggregation strategies, creating meta-learning systems that continuously improve their ability to combine diverse contributions effectively.
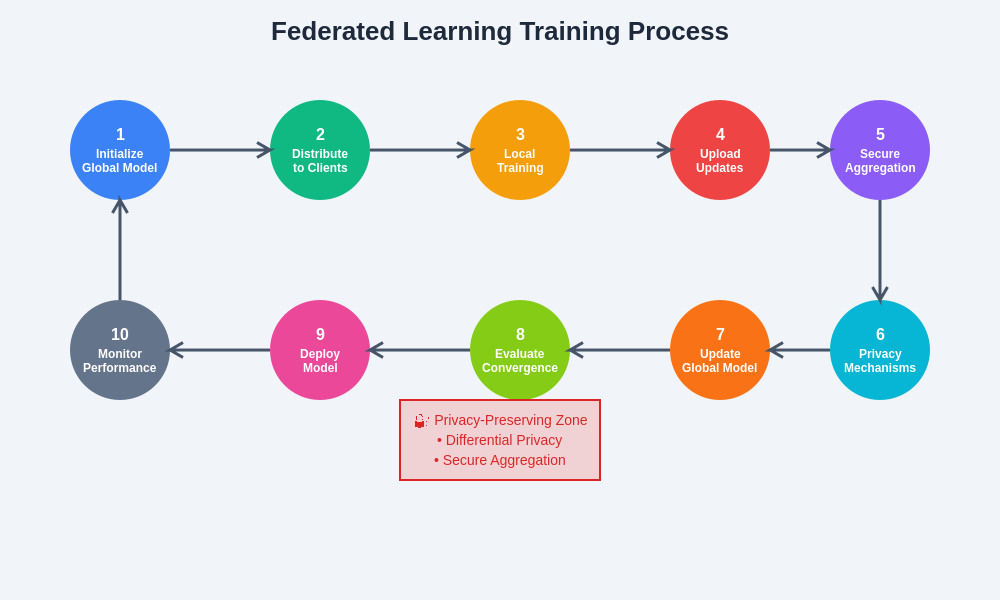
The comprehensive training process in federated learning systems illustrates the cyclical nature of collaborative model development, where privacy-preserving mechanisms are integrated at every stage to ensure data protection while maintaining model effectiveness. This systematic approach enables organizations to participate in collaborative AI development without compromising sensitive information or violating regulatory requirements.
Explore comprehensive AI research capabilities with Perplexity to stay current with the latest developments in federated aggregation algorithms and privacy-preserving techniques. The continuous evolution of aggregation methodologies drives improvements in federated learning effectiveness while addressing emerging challenges related to scalability, security, and model performance.
Handling Data Heterogeneity and Non-IID Distributions
One of the most significant challenges in federated learning involves managing the inherent heterogeneity of data distributions across participating devices and organizations. Real-world federated scenarios typically involve non-independently and identically distributed data, where different participants possess datasets with varying statistical properties, feature distributions, and label frequencies. This data heterogeneity can significantly impact model convergence, generalization performance, and fairness across different participant groups.
Statistical heterogeneity manifests in various forms, including feature distribution skew, label distribution imbalance, temporal variations, and concept drift across different participants. Healthcare federated learning scenarios exemplify these challenges, where different hospitals may have patient populations with distinct demographic characteristics, disease prevalences, and diagnostic procedures. Financial institutions participating in fraud detection federated learning face similar challenges due to varying customer bases, transaction patterns, and risk profiles.
Addressing data heterogeneity requires sophisticated techniques that can accommodate diverse data characteristics while maintaining global model effectiveness. Personalization approaches enable the creation of customized models that perform well on individual participant datasets while benefiting from collective learning experiences. Multi-task learning frameworks allow participants to jointly optimize related but distinct objectives, enabling knowledge transfer across different tasks while respecting local data characteristics.
Federated transfer learning techniques leverage pre-trained models and domain adaptation methods to improve performance in scenarios where participants have limited local data or significantly different data distributions. These approaches utilize knowledge distillation, fine-tuning strategies, and domain adversarial training to create models that can generalize effectively across diverse participant environments while maintaining strong performance on local datasets.
Security Considerations and Attack Mitigation
The distributed nature of federated learning systems introduces unique security challenges that require comprehensive defense strategies addressing both external threats and potential insider attacks. Adversarial participants may attempt to poison training processes by contributing malicious model updates designed to degrade global model performance or introduce backdoors that compromise model integrity. These attacks can be particularly insidious because they may not be immediately detectable and can persist across multiple training rounds.
Model inversion attacks represent sophisticated threats where adversaries attempt to reconstruct training data from shared model parameters or gradients. These attacks leverage optimization techniques and generative models to reverse-engineer sensitive information from seemingly anonymized model updates. Advanced model inversion techniques can potentially recover high-fidelity reconstructions of training samples, highlighting the critical importance of robust privacy-preserving mechanisms.
Membership inference attacks enable adversaries to determine whether specific data points were included in training datasets by analyzing model behavior or parameter patterns. These attacks pose significant privacy risks in sensitive domains such as healthcare or finance, where revealing participation in training datasets could disclose confidential information about individuals or organizations. Defending against membership inference requires careful implementation of differential privacy techniques and regularization methods that limit model memorization.
Byzantine-robust aggregation protocols provide defense mechanisms against coordinated attacks by malicious participants attempting to manipulate global model behavior. These protocols implement statistical techniques, cryptographic verification methods, and anomaly detection algorithms to identify and mitigate the impact of adversarial contributions. Advanced Byzantine-robust systems can maintain training effectiveness even when significant fractions of participants exhibit malicious behavior.
Real-World Applications and Case Studies
Healthcare represents one of the most compelling application domains for federated learning, where privacy regulations such as HIPAA and GDPR create significant barriers to traditional centralized learning approaches. Federated learning enables hospitals and research institutions to collaboratively develop diagnostic models, drug discovery algorithms, and treatment optimization systems without sharing sensitive patient data. Medical imaging applications have demonstrated particularly strong results, with federated models achieving performance comparable to centralized approaches while maintaining strict privacy compliance.
The COVID-19 pandemic accelerated adoption of federated learning in healthcare, with multiple international collaborations utilizing these techniques to develop diagnostic tools, treatment protocols, and epidemiological models. These projects demonstrated the practical feasibility of large-scale federated learning deployments while highlighting the importance of robust privacy-preserving mechanisms in sensitive applications. Lessons learned from pandemic response efforts continue to inform best practices for healthcare federated learning implementations.
Financial services applications of federated learning focus primarily on fraud detection, credit risk assessment, and anti-money laundering systems where regulatory requirements and competitive concerns limit data sharing opportunities. Banks and financial institutions utilize federated approaches to improve detection accuracy while maintaining customer privacy and regulatory compliance. These implementations often require sophisticated techniques for handling highly imbalanced datasets and evolving fraud patterns.
Telecommunications networks represent another significant application domain where federated learning enables network optimization, quality of service prediction, and security threat detection across distributed infrastructure. Mobile network operators utilize federated techniques to optimize resource allocation, predict network congestion, and detect anomalous behavior while protecting sensitive operational data and customer information.
Evaluation Metrics and Performance Assessment
Evaluating federated learning systems requires comprehensive metrics that assess not only traditional machine learning performance measures but also privacy preservation effectiveness, communication efficiency, and system robustness. Model accuracy and generalization performance remain fundamental evaluation criteria, but federated settings require careful consideration of how these metrics are computed and interpreted across heterogeneous participant datasets.
Privacy preservation assessment involves quantifying the actual privacy guarantees provided by implemented mechanisms through formal privacy analysis, empirical privacy auditing, and adversarial testing. Differential privacy implementations require careful measurement of privacy budget consumption, noise calibration effectiveness, and utility preservation under various privacy parameter settings. Security evaluations must assess resilience against known attack vectors through red team exercises and penetration testing methodologies.
Communication efficiency metrics evaluate bandwidth utilization, transmission frequency, and compression effectiveness, which are critical considerations for practical deployments involving resource-constrained devices or limited network connectivity. These assessments must consider both computational overhead and communication costs, particularly for mobile or edge computing scenarios where energy consumption and network usage directly impact system viability.
Fairness evaluation in federated learning requires assessment of model performance across different participant groups, ensuring that collaborative training does not inadvertently disadvantage certain populations or create biased outcomes. These evaluations must consider both individual fairness measures and group fairness criteria while accounting for the underlying data heterogeneity that characterizes federated learning scenarios.
Future Directions and Emerging Trends
The future evolution of federated learning will likely focus on addressing current limitations while expanding applicability to new domains and use cases. Automated federated learning systems that can dynamically optimize hyperparameters, aggregation strategies, and privacy mechanisms without human intervention represent a significant research frontier. These systems would utilize meta-learning techniques, automated machine learning approaches, and reinforcement learning algorithms to continuously improve federated training effectiveness.
Cross-device federated learning involving millions of mobile devices presents exciting opportunities for creating truly personalized AI systems while maintaining user privacy. These massive-scale deployments require innovations in communication protocols, device selection strategies, and fault tolerance mechanisms to handle the inherent challenges of mobile computing environments. Edge AI integration will enable more sophisticated local processing capabilities while reducing dependence on cloud-based coordination mechanisms.
Federated learning for emerging AI paradigms such as large language models, multimodal learning systems, and reinforcement learning agents represents another significant growth area. These applications require novel approaches to handle the massive parameter spaces, complex training dynamics, and diverse data modalities that characterize modern AI systems. The integration of federated learning with other privacy-preserving technologies such as trusted execution environments and confidential computing platforms will create even more robust privacy guarantees.
The development of standardized frameworks, protocols, and evaluation benchmarks will facilitate broader adoption of federated learning techniques across industries and research communities. These standardization efforts must balance flexibility for diverse use cases with interoperability requirements that enable collaborative development and deployment of federated learning systems.
The continued evolution of privacy-preserving AI through federated learning represents a critical pathway toward realizing the full potential of artificial intelligence while respecting individual privacy rights and maintaining public trust in AI systems. As these technologies mature and become more accessible, they will enable new forms of collaborative intelligence that were previously impossible due to privacy and regulatory constraints, ultimately accelerating AI innovation while protecting the fundamental rights and interests of all stakeholders.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on current understanding of federated learning and privacy-preserving AI technologies. Readers should conduct their own research and consult with qualified experts when implementing federated learning systems in production environments. Privacy and security requirements may vary significantly across different jurisdictions, industries, and use cases, requiring careful consideration of applicable regulations and best practices.