
The convergence of Progressive Web Apps and artificial intelligence has created unprecedented opportunities for delivering sophisticated machine learning capabilities directly within web browsers, even in offline environments. This revolutionary approach to application architecture transforms how users interact with AI-powered features, ensuring seamless functionality regardless of network connectivity while maintaining the performance and responsiveness users expect from modern web applications.
Discover the latest AI trends shaping web development and see how cutting-edge technologies are enabling new possibilities for offline-first applications. The integration of AI caching strategies within PWAs represents a fundamental shift toward more resilient, user-centric application architectures that prioritize accessibility and performance across diverse network conditions.
The Foundation of PWA AI Architecture
Progressive Web Apps have fundamentally redefined the boundaries between web and native applications by leveraging service workers, web app manifests, and advanced caching strategies to deliver app-like experiences through web browsers. When combined with artificial intelligence capabilities, PWAs create powerful platforms that can process complex machine learning tasks without requiring constant server connectivity. This architectural approach addresses critical challenges in modern application development, including network reliability, data privacy, and computational efficiency.
The foundation of PWA AI architecture rests on several key technologies that work in harmony to deliver sophisticated offline capabilities. Service workers act as programmable network proxies, intercepting network requests and managing sophisticated caching strategies that ensure critical AI models and processing capabilities remain available even when network connectivity is unreliable or completely unavailable. This approach enables applications to maintain full functionality across diverse usage scenarios while providing users with consistent, predictable experiences.
The strategic implementation of AI caching within PWAs requires careful consideration of resource management, model optimization, and user experience design. Developers must balance the computational requirements of machine learning models with the storage limitations and processing capabilities of client devices while ensuring that offline functionality seamlessly integrates with online features when connectivity is restored.
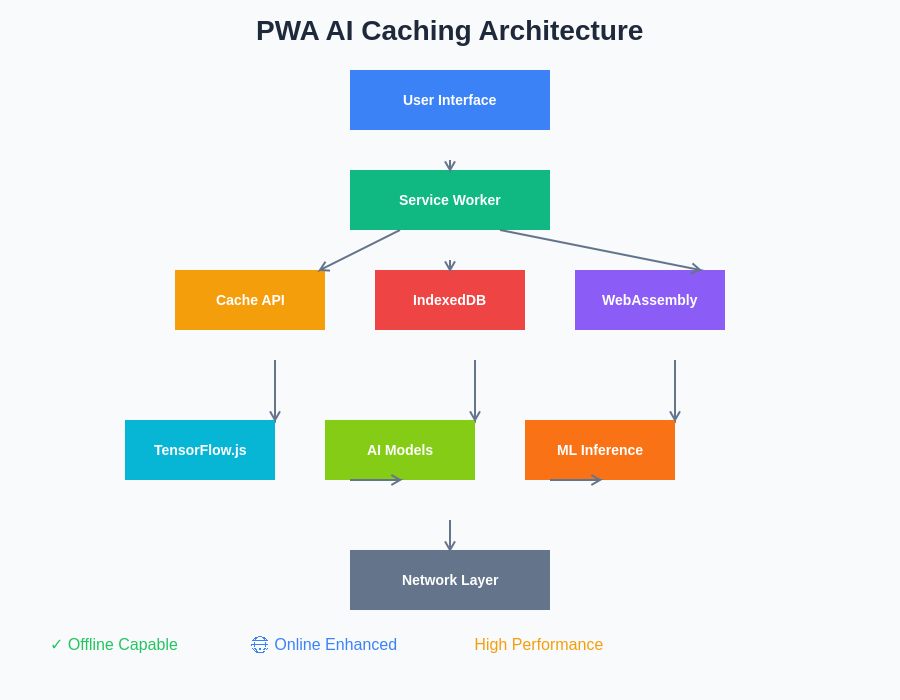
The comprehensive PWA AI architecture demonstrates how multiple technologies work together to deliver sophisticated offline machine learning capabilities. This layered approach ensures that AI functionality remains available across diverse network conditions while maintaining optimal performance and user experience.
Service Worker Implementation for AI Model Caching
Service workers serve as the backbone of PWA AI caching strategies, providing sophisticated mechanisms for intercepting network requests, managing cache storage, and implementing intelligent fallback strategies when AI models or related resources are unavailable through network requests. The implementation of service worker-based AI caching requires careful orchestration of resource prioritization, cache versioning, and intelligent prefetching strategies that ensure critical machine learning models are available when needed.
Modern service worker implementations for AI caching typically employ multi-layered caching strategies that differentiate between various types of AI-related resources, including pre-trained models, training data, inference results, and supporting libraries. These sophisticated caching mechanisms enable applications to maintain different cache policies for different resource types, optimizing storage utilization while ensuring that the most critical components remain available during offline periods.
Experience advanced AI capabilities with Claude to understand how sophisticated reasoning and analysis can be integrated into offline-capable applications. The evolution of service worker capabilities continues to expand the possibilities for implementing complex AI workflows that operate independently of network connectivity while maintaining high performance standards.
TensorFlow.js and Client-Side ML Processing
TensorFlow.js has emerged as a cornerstone technology for implementing client-side machine learning capabilities within PWAs, providing comprehensive tools for loading, executing, and managing AI models directly within web browsers. This JavaScript-based machine learning library enables developers to implement sophisticated AI features that operate entirely on client devices, eliminating dependencies on server-side processing while ensuring user data privacy and reducing latency for real-time applications.
The integration of TensorFlow.js within PWA architectures enables powerful offline machine learning scenarios, including image recognition, natural language processing, predictive analytics, and recommendation systems that continue functioning even when network connectivity is unavailable. These capabilities transform how users interact with AI-powered features, providing immediate responses and maintaining functionality across diverse network conditions.
The optimization of TensorFlow.js models for offline PWA deployment requires careful consideration of model size, computational complexity, and memory utilization. Developers must implement effective model compression techniques, leverage quantization strategies, and optimize inference pipelines to ensure that AI capabilities remain responsive and efficient when operating on client devices with varying computational capabilities.
WebAssembly Integration for High-Performance AI
WebAssembly represents a transformative technology for implementing high-performance machine learning capabilities within PWAs, providing near-native execution speeds for computationally intensive AI workloads. The integration of WebAssembly modules within PWA architectures enables sophisticated AI processing that approaches the performance of native applications while maintaining the accessibility and deployment advantages of web-based platforms.
The strategic use of WebAssembly for AI processing within PWAs particularly benefits applications requiring real-time inference, complex mathematical computations, or processing of large datasets. This technology enables developers to leverage existing machine learning libraries written in languages like C++ or Rust while seamlessly integrating these capabilities within JavaScript-based PWA environments.
WebAssembly-based AI implementations within PWAs can effectively utilize multi-threading capabilities and SIMD instructions to maximize performance on modern processors, enabling sophisticated machine learning workflows that were previously impossible within web browser environments. This advancement opens new possibilities for implementing complex AI algorithms that deliver enterprise-grade performance within accessible web applications.
IndexedDB for AI Model and Data Storage
IndexedDB provides essential infrastructure for storing machine learning models, training data, and inference results within PWA environments, offering the storage capacity and performance characteristics required for sophisticated AI applications. The strategic implementation of IndexedDB for AI-related storage enables applications to maintain large datasets and complex models locally while providing efficient access patterns that support real-time machine learning workflows.
Modern PWA AI implementations leverage IndexedDB’s transaction-based architecture to ensure data consistency when managing AI models and related resources across different application sessions. This approach enables sophisticated version management for machine learning models while supporting incremental updates and rollback capabilities that ensure application stability during model transitions.
The optimization of IndexedDB storage strategies for AI applications requires careful consideration of data organization, indexing strategies, and garbage collection mechanisms that prevent storage bloat while maintaining optimal access performance. Developers must implement effective data lifecycle management that balances storage efficiency with the accessibility requirements of machine learning workflows.
Enhance your research capabilities with Perplexity to explore advanced techniques for optimizing storage and retrieval of machine learning models in browser environments. The continued evolution of browser storage capabilities enables increasingly sophisticated approaches to local AI model management.
Cache Strategies for Different AI Workloads
Implementing effective cache strategies for AI workloads within PWAs requires understanding the diverse characteristics and requirements of different machine learning scenarios. Image processing applications may require different caching approaches than natural language processing systems, while real-time inference applications have distinct requirements from batch processing workloads. This diversity necessitates sophisticated cache management strategies that adapt to specific AI workload characteristics.
The implementation of workload-specific cache strategies typically involves analyzing usage patterns, model characteristics, and performance requirements to develop optimized approaches for different AI scenarios. Applications focused on computer vision may prioritize caching image preprocessing pipelines and model weights, while conversational AI applications might emphasize caching tokenization resources and language model components.
Advanced cache strategies for AI workloads often implement predictive prefetching mechanisms that anticipate user interactions and preload relevant models or data before they are explicitly requested. These intelligent caching approaches significantly improve user experience by reducing perceived latency while optimizing resource utilization across diverse usage scenarios.
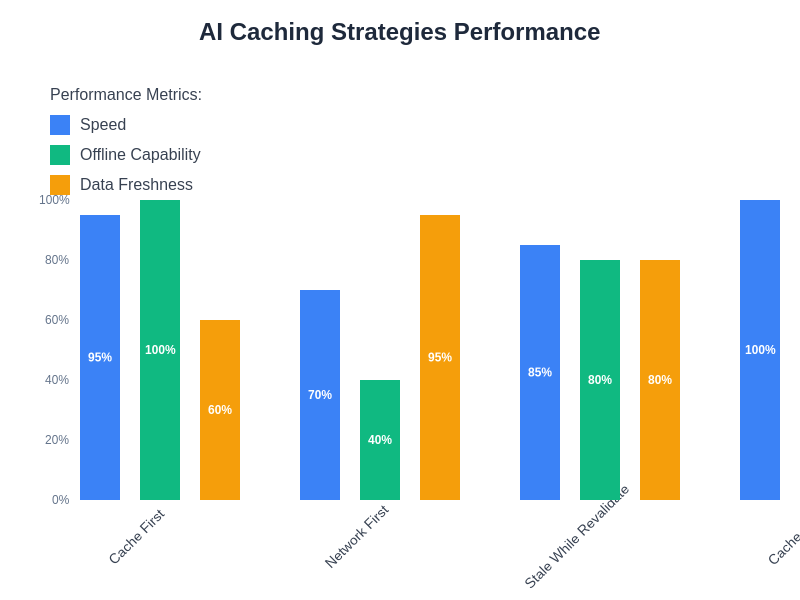
The comparative analysis of different caching strategies reveals significant variations in performance characteristics across key metrics. Understanding these trade-offs enables developers to select optimal caching approaches based on specific application requirements and user experience priorities.
Offline Training and Model Updates
The implementation of offline training capabilities within PWAs represents an advanced application of client-side machine learning that enables applications to improve and adapt their AI models based on user interactions and local data without requiring network connectivity. This approach enables personalized machine learning experiences while maintaining data privacy and reducing dependencies on external services.
Offline model training within PWAs typically focuses on incremental learning approaches that can efficiently update existing models with new data while operating within the computational and storage constraints of client devices. These implementations often leverage transfer learning techniques and lightweight optimization algorithms that can effectively improve model performance without requiring extensive computational resources.
The management of offline model updates requires sophisticated versioning and synchronization mechanisms that ensure consistency between local model improvements and potential server-side updates when connectivity is restored. These systems must carefully balance local personalization with global model improvements while maintaining system stability and performance.
Performance Optimization Techniques
Optimizing performance for PWA AI applications requires comprehensive approaches that address multiple aspects of the application architecture, including model loading, inference execution, and resource management. The implementation of effective performance optimization techniques ensures that AI capabilities remain responsive and efficient across diverse device capabilities and network conditions.
Critical performance optimization strategies for PWA AI applications include model quantization techniques that reduce memory requirements while maintaining inference accuracy, intelligent batching mechanisms that optimize GPU utilization, and sophisticated resource scheduling that balances AI processing with other application requirements. These optimizations enable smooth user experiences even on devices with limited computational capabilities.
Advanced performance optimization often involves implementing adaptive quality mechanisms that automatically adjust model complexity or inference parameters based on device capabilities and battery status. These intelligent systems ensure that AI features remain accessible across diverse hardware configurations while optimizing battery life and system responsiveness.
Real-World Implementation Examples
Practical implementations of PWA AI caching demonstrate the transformative potential of these technologies across diverse application domains. Photo editing applications leverage offline computer vision models to provide real-time image enhancement and object recognition capabilities that operate independently of network connectivity. These implementations showcase how sophisticated AI capabilities can be seamlessly integrated within accessible web applications.
Conversational AI applications represent another compelling use case for PWA AI caching, enabling natural language processing capabilities that continue functioning during network outages while maintaining conversational context and user preferences. These applications demonstrate how offline AI capabilities can provide consistent user experiences across varying connectivity conditions.
Educational applications utilizing PWA AI caching enable personalized learning experiences that adapt to individual student needs while operating reliably in environments with limited internet access. These implementations highlight the democratizing potential of offline AI capabilities for expanding access to sophisticated educational tools.
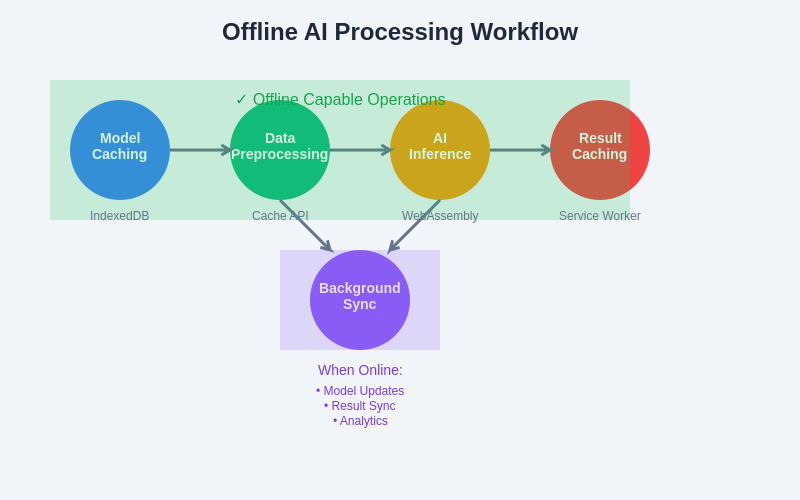
The offline AI processing workflow illustrates how different components collaborate to deliver seamless machine learning capabilities without network dependency. This systematic approach ensures consistent performance while enabling background synchronization when connectivity becomes available.
Security Considerations for Offline AI
Implementing AI capabilities within offline PWA environments introduces unique security considerations that must be carefully addressed to protect user data and maintain application integrity. The local storage of machine learning models and sensitive data requires robust encryption mechanisms and secure key management strategies that protect against various attack vectors while maintaining performance and usability.
The implementation of secure offline AI systems typically involves end-to-end encryption for stored models and data, secure communication protocols for model updates, and robust authentication mechanisms that prevent unauthorized access to AI capabilities. These security measures must be carefully balanced with performance requirements and user experience considerations.
Advanced security implementations for offline AI often include integrity verification mechanisms that ensure stored models and data have not been tampered with, privacy-preserving inference techniques that protect sensitive user data during processing, and secure sandboxing approaches that isolate AI processing from other application components.
Future Trends and Emerging Technologies
The future of PWA AI caching is being shaped by emerging technologies and evolving standards that promise to expand the capabilities and accessibility of offline machine learning applications. WebGPU represents a particularly significant advancement, providing direct access to graphics processing units for high-performance AI computations within web browsers while maintaining the security and accessibility advantages of web platforms.
The development of more sophisticated compression algorithms and model optimization techniques continues to expand the complexity of AI models that can be effectively deployed within PWA environments. These advancements enable the implementation of larger, more capable models while maintaining the storage and performance constraints required for offline operation.
The emergence of federated learning approaches specifically designed for web environments promises to enable collaborative machine learning scenarios where PWAs can contribute to model improvements while maintaining data privacy and offline capabilities. These developments represent significant steps toward more intelligent, adaptive applications that learn and evolve based on collective user interactions.
The continued evolution of browser capabilities and web standards ensures that PWA AI caching will become increasingly sophisticated and accessible, enabling new classes of applications that blur the boundaries between web and native experiences while providing unprecedented offline AI capabilities. The future of web development lies in these intelligent, resilient applications that deliver powerful AI features regardless of network connectivity.
Disclaimer
This article is for informational purposes only and does not constitute professional advice regarding PWA development or AI implementation. The technologies and techniques discussed are based on current understanding of web standards and machine learning frameworks, which continue to evolve rapidly. Readers should conduct thorough testing and validation when implementing offline AI capabilities and consider their specific requirements for security, performance, and user experience. The effectiveness of PWA AI caching strategies may vary depending on target devices, user scenarios, and application requirements.