
The machine learning landscape continues to evolve rapidly, with programming languages serving as the foundation for innovation and discovery in artificial intelligence and data science. As we navigate through 2025, three languages have emerged as dominant forces in the machine learning ecosystem: Python, R, and Julia. Each brings unique strengths and capabilities that cater to different aspects of machine learning development, from research and prototyping to production deployment and high-performance computing.
Stay updated with the latest AI and ML trends to understand how these programming languages are shaping the future of artificial intelligence and data science applications. The choice between Python, R, and Julia represents more than a technical decision; it reflects strategic considerations about project requirements, team expertise, performance needs, and long-term maintainability that can significantly impact the success of machine learning initiatives.
The Current State of Machine Learning Languages
The machine learning programming landscape has matured significantly, with each language carving out distinct niches while maintaining competitive overlap in core functionality. Python has established itself as the industry standard for general-purpose machine learning applications, offering an extensive ecosystem of libraries and frameworks that support everything from basic data manipulation to cutting-edge deep learning research. Its versatility and ease of learning have made it the preferred choice for both beginners and experienced practitioners across various domains.
R continues to dominate statistical analysis and academic research environments, providing unparalleled capabilities for statistical modeling, data visualization, and exploratory data analysis. The language’s functional programming paradigm and comprehensive statistical library ecosystem make it particularly well-suited for rigorous statistical inference, hypothesis testing, and complex mathematical modeling that requires deep statistical understanding and validation.
Julia represents the newest entrant in this comparison, designed specifically to address performance limitations that traditionally plagued high-level programming languages in scientific computing. By combining the ease of use associated with dynamic languages like Python and R with the performance characteristics of compiled languages like C and Fortran, Julia aims to eliminate the traditional two-language problem where prototyping occurs in high-level languages but production systems require reimplementation in lower-level languages for performance reasons.
Python: The Versatile Machine Learning Champion
Python’s dominance in machine learning stems from its exceptional balance of simplicity, versatility, and comprehensive ecosystem support. The language’s readable syntax and intuitive design philosophy make it accessible to practitioners from diverse backgrounds, including those without extensive programming experience. This accessibility has contributed to Python’s adoption across industries, from startups developing innovative AI applications to large enterprises implementing production-scale machine learning systems.
The Python machine learning ecosystem encompasses a rich collection of specialized libraries and frameworks that address virtually every aspect of the machine learning pipeline. NumPy and Pandas provide foundational data manipulation and numerical computing capabilities, while Scikit-learn offers comprehensive implementations of traditional machine learning algorithms with consistent interfaces and excellent documentation. For deep learning applications, TensorFlow and PyTorch have emerged as the dominant frameworks, each offering unique advantages for different types of neural network development and deployment scenarios.
Explore advanced AI tools like Claude to enhance your machine learning development workflow with intelligent code generation and problem-solving capabilities. Python’s integration with modern AI development tools creates a powerful synergy that accelerates both learning and implementation of complex machine learning solutions.
Python’s strength in machine learning extends beyond its technical capabilities to include exceptional community support, extensive documentation, and continuous innovation. The language benefits from active contributions from both academic researchers and industry practitioners, resulting in rapid adoption of new techniques and algorithms. This collaborative ecosystem ensures that Python remains at the forefront of machine learning innovation, with new libraries and tools constantly emerging to address evolving needs and challenges.
The versatility of Python becomes particularly apparent in end-to-end machine learning projects that require integration with web services, databases, cloud platforms, and production systems. Python’s extensive standard library and third-party package ecosystem enable seamless integration with various technologies, making it possible to build complete machine learning solutions without switching between multiple programming environments. This capability is especially valuable in enterprise settings where machine learning models must integrate with existing business systems and workflows.
However, Python’s interpreted nature can present performance limitations for computationally intensive tasks, particularly when working with large datasets or implementing custom algorithms that require extensive numerical computation. While libraries like NumPy and TensorFlow mitigate many performance concerns by implementing critical operations in optimized C and CUDA code, pure Python implementations can still be significantly slower than compiled alternatives for certain types of computational workloads.
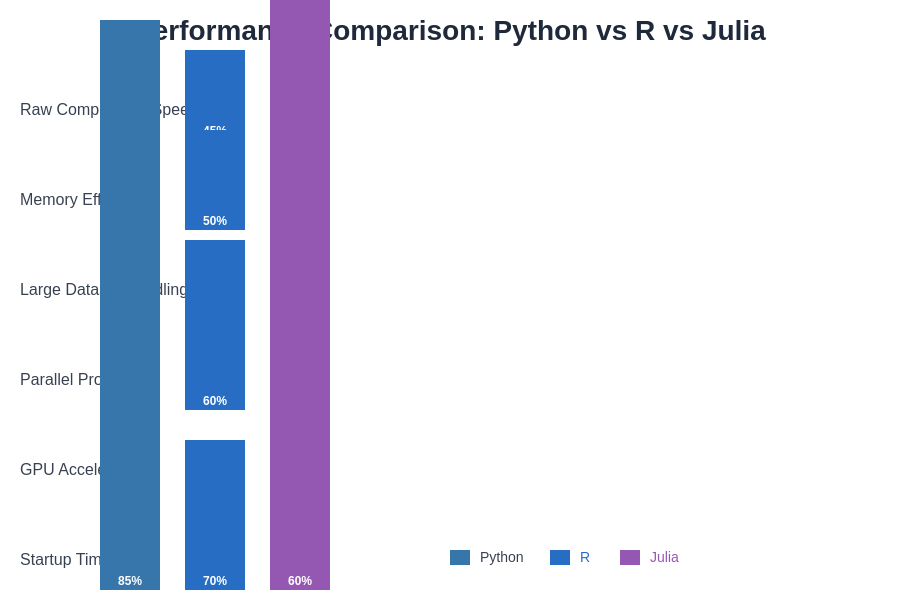
The performance characteristics of Python, R, and Julia vary significantly across different computational tasks, with Julia demonstrating superior raw computation speed and memory efficiency, while Python excels in GPU acceleration capabilities and R shows limitations in memory-intensive applications.
R: The Statistical Powerhouse
R’s position in the machine learning landscape is unique and irreplaceable, particularly for applications that require rigorous statistical analysis, hypothesis testing, and comprehensive data exploration. The language was designed by statisticians for statisticians, resulting in a programming environment that naturally aligns with statistical thinking and methodology. This foundation makes R exceptionally well-suited for machine learning applications where statistical validity, interpretability, and rigorous analysis are paramount concerns.
The R ecosystem for statistical machine learning is unparalleled in its depth and sophistication. The Comprehensive R Archive Network (CRAN) hosts thousands of packages that implement cutting-edge statistical methods, many of which are contributed directly by the researchers who developed the underlying algorithms. This direct connection between research and implementation ensures that R users have access to the most current statistical techniques, often months or years before they become available in other programming languages.
R’s approach to data visualization represents another significant advantage for machine learning practitioners. The ggplot2 package and related visualization libraries provide a grammar of graphics that enables the creation of sophisticated, publication-quality visualizations with minimal code. This capability is essential for exploratory data analysis, model interpretation, and communication of results to stakeholders who may not have technical backgrounds but need to understand model behavior and implications.
The functional programming paradigm that underlies R encourages a different approach to problem-solving that can be particularly beneficial for statistical machine learning tasks. R’s emphasis on vectorized operations, functional composition, and immutable data structures aligns well with mathematical formulations of statistical algorithms and can lead to more concise and mathematically transparent implementations of complex models.
R’s integration with reproducible research practices through tools like R Markdown and Shiny applications provides exceptional capabilities for creating interactive reports, dashboards, and web applications that combine code, analysis, and visualization in cohesive documents. This integration is particularly valuable for communicating machine learning results to diverse audiences and ensuring that analyses can be reproduced and validated by other researchers or practitioners.
Despite these strengths, R faces challenges in modern machine learning environments, particularly regarding performance for large-scale applications and integration with production systems. R’s memory management model, which loads entire datasets into RAM, can be limiting when working with big data applications. Additionally, R’s ecosystem for deep learning and neural networks, while improving, remains less mature than Python’s offerings, potentially limiting its applicability for certain types of modern machine learning applications.
Julia: The High-Performance Newcomer
Julia represents a paradigm shift in scientific computing and machine learning, addressing fundamental performance limitations that have traditionally required compromises between ease of development and computational efficiency. The language’s design philosophy centers on eliminating the two-language problem, where initial development and prototyping occur in high-level languages like Python or R, but production implementations require translation to lower-level languages like C or Fortran to achieve acceptable performance.
The technical foundation of Julia’s performance advantages lies in its sophisticated just-in-time compilation system, which analyzes code at runtime and generates optimized machine code that can achieve performance comparable to statically compiled languages. This approach enables Julia to provide the interactive development experience associated with dynamic languages while delivering the computational performance required for large-scale scientific computing applications.
Julia’s mathematical syntax and built-in support for advanced numerical computing concepts make it particularly well-suited for implementing novel machine learning algorithms from scratch. The language’s type system supports multiple dispatch, enabling the creation of generic algorithms that can work efficiently with different data types while maintaining type safety and performance. This capability is especially valuable for research applications where custom algorithms and mathematical formulations are common requirements.
The emerging Julia machine learning ecosystem shows significant promise, with packages like MLJ.jl providing unified interfaces for machine learning workflows, Flux.jl offering flexible neural network implementations, and Distributions.jl supporting sophisticated probabilistic modeling. While this ecosystem is less mature than Python’s, it benefits from Julia’s performance characteristics and mathematical expressiveness, potentially offering advantages for certain types of computationally intensive applications.
Enhance your research capabilities with Perplexity to stay current with the latest developments in Julia’s rapidly evolving machine learning ecosystem and understand emerging best practices for high-performance scientific computing. The intersection of Julia’s technical capabilities with modern AI research methodologies creates opportunities for innovative approaches to machine learning implementation and optimization.
Julia’s interoperability capabilities allow seamless integration with existing code written in other languages, including Python, R, and C. This interoperability means that organizations can adopt Julia incrementally, using it for performance-critical components while maintaining existing workflows and leveraging established libraries from other ecosystems. Such flexibility can be crucial for teams that need to balance performance requirements with practical constraints and existing investments in other technologies.
However, Julia’s relative youth in the programming language landscape presents certain challenges for widespread adoption. The ecosystem, while growing rapidly, lacks the maturity and comprehensive coverage found in Python’s machine learning libraries. Documentation and learning resources, though improving, are not as extensive as those available for Python or R. Additionally, the job market for Julia developers remains smaller, which can impact hiring decisions and long-term project sustainability considerations.
Performance Analysis and Benchmarking
Performance considerations play a crucial role in machine learning language selection, particularly for applications involving large datasets, complex models, or real-time inference requirements. Python’s performance characteristics vary significantly depending on the specific libraries and implementation approaches used. While pure Python code can be relatively slow for numerical computations, the extensive use of optimized libraries like NumPy, SciPy, and specialized machine learning frameworks can achieve performance levels comparable to lower-level languages for many common tasks.
The performance story for Python becomes more complex when considering deep learning applications, where frameworks like TensorFlow and PyTorch leverage GPU acceleration and highly optimized linear algebra libraries. In these scenarios, the bottleneck often shifts from language performance to factors like data preprocessing, I/O operations, and algorithm design rather than the underlying language implementation. However, for custom algorithm development or applications that cannot leverage existing optimized libraries, Python’s interpreted nature can result in significant performance penalties.
R’s performance characteristics reflect its design priorities, which emphasize statistical correctness and ease of use over raw computational speed. For typical statistical machine learning tasks involving moderate-sized datasets, R’s performance is generally acceptable, particularly when leveraging vectorized operations and optimized packages. However, R can struggle with memory-intensive applications due to its approach of loading entire datasets into memory, and its single-threaded execution model can limit performance on modern multi-core systems.
Julia’s performance advantages become most apparent in applications that require extensive numerical computation, custom algorithm implementation, or processing of large datasets. Benchmarks consistently show Julia achieving performance within a factor of two of optimized C code for many numerical computing tasks, while maintaining the development productivity associated with high-level languages. This performance capability can be particularly valuable for research applications where novel algorithms must be implemented from scratch or for production systems where computational efficiency directly impacts operational costs.
Ecosystem Maturity and Library Support
The ecosystem maturity surrounding each language significantly influences practical usability for machine learning projects. Python’s ecosystem represents the gold standard for comprehensiveness and maturity, with well-established libraries covering virtually every aspect of machine learning development. The scikit-learn library provides consistent interfaces for traditional machine learning algorithms, while TensorFlow and PyTorch dominate deep learning applications with extensive documentation, community support, and regular updates.
Python’s ecosystem extends beyond core machine learning libraries to include comprehensive support for data preprocessing, feature engineering, model deployment, and production monitoring. Libraries like Pandas for data manipulation, Matplotlib and Seaborn for visualization, Flask and FastAPI for web service development, and MLflow for experiment tracking create a complete toolkit for end-to-end machine learning development. This ecosystem maturity means that Python developers can typically find existing solutions for most common machine learning challenges, reducing development time and improving reliability.
R’s ecosystem strength lies in its deep statistical foundation and specialized packages for advanced statistical methods. CRAN hosts thousands of packages that implement state-of-the-art statistical techniques, many contributed directly by academic researchers. This direct research-to-implementation pipeline means that R users often have access to the latest statistical methods before they become available in other languages. The ecosystem particularly excels in areas like survival analysis, time series forecasting, experimental design, and Bayesian statistics.
The R ecosystem also provides exceptional support for reproducible research through packages like R Markdown, which enables the creation of documents that combine code, analysis, and narrative text. The Shiny framework allows for the development of interactive web applications that can make R-based analyses accessible to non-technical users. These capabilities are particularly valuable in academic and research environments where documentation, reproducibility, and knowledge sharing are essential requirements.
Julia’s ecosystem represents the newest and most rapidly evolving component of this comparison. While significantly smaller than Python’s or R’s ecosystems, Julia’s libraries benefit from the language’s performance characteristics and mathematical expressiveness. The MLJ.jl package provides a unified interface for machine learning that aims to combine the best aspects of scikit-learn’s consistency with Julia’s performance advantages. Flux.jl offers a flexible approach to neural network development that leverages Julia’s mathematical syntax for intuitive model specification.
The Julia ecosystem’s relative youth means that some specialized libraries and tools available in Python or R may not yet have Julia equivalents. However, Julia’s excellent interoperability with other languages allows users to leverage existing libraries when needed. This interoperability, combined with Julia’s growing ecosystem, creates a development environment that can combine the best aspects of different language ecosystems while maintaining Julia’s performance advantages for critical components.
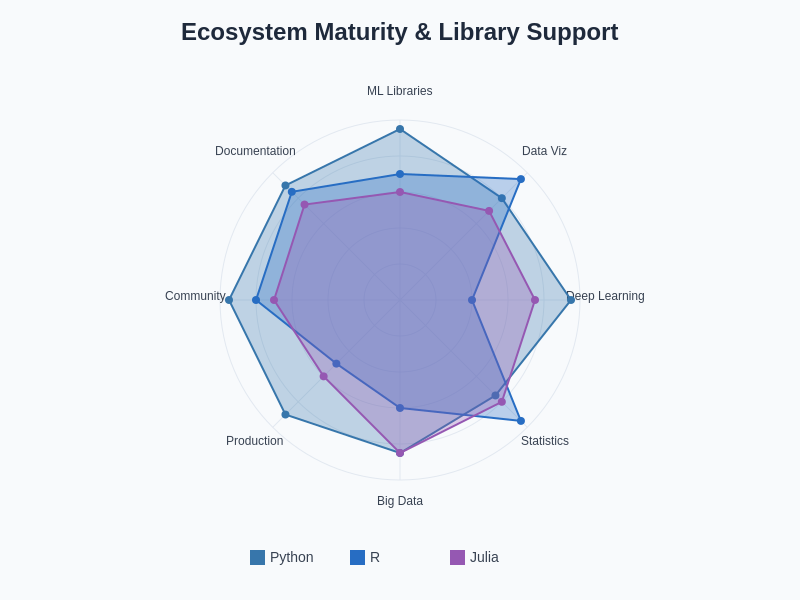
The ecosystem comparison reveals Python’s dominance in machine learning libraries and production readiness, R’s superiority in statistical capabilities and data visualization, and Julia’s emerging strength in high-performance computing applications, though with less mature community support and documentation.
Learning Curve and Developer Experience
The learning curve associated with each language varies significantly based on the developer’s background and intended use cases. Python’s design philosophy emphasizes readability and simplicity, making it often the most accessible choice for newcomers to machine learning. The language’s syntax closely resembles natural language constructs, and its extensive documentation and tutorial resources create a supportive learning environment for developers at all skill levels.
Python’s gentle learning curve extends to its machine learning libraries, which generally follow consistent design patterns and provide comprehensive documentation. The scikit-learn library, in particular, is renowned for its user-friendly API design and excellent educational resources that help newcomers understand both the technical implementation and the underlying mathematical concepts. This combination of language simplicity and library accessibility makes Python an excellent choice for educational environments and for teams that need to quickly onboard new machine learning practitioners.
R’s learning curve presents a different set of challenges and advantages. For individuals with strong statistical backgrounds, R’s functional programming paradigm and statistical focus can feel intuitive and natural. The language’s syntax directly reflects mathematical and statistical concepts, making it easier to translate statistical formulations into working code. However, for developers coming from imperative programming backgrounds, R’s functional approach and unique syntax can initially feel unfamiliar and challenging.
The R learning experience benefits from the language’s interactive nature and exceptional support for exploratory data analysis. The ability to quickly examine data, test hypotheses, and visualize results creates an engaging learning environment that encourages experimentation and discovery. This interactive capability, combined with R’s comprehensive statistical libraries, makes it an excellent choice for learning statistical concepts alongside programming skills.
Julia’s learning curve reflects its position as a more technically sophisticated language designed for advanced scientific computing applications. Developers with backgrounds in mathematics, physics, or engineering often find Julia’s mathematical syntax and performance focus appealing and intuitive. However, concepts like multiple dispatch and Julia’s type system can be challenging for newcomers to understand and utilize effectively.
The Julia learning experience benefits from the language’s modern design, which incorporates lessons learned from decades of scientific computing development. The language’s package manager, documentation system, and development tools reflect current best practices in software development, creating a more polished development experience than might be expected from a relatively new language. Additionally, Julia’s excellent performance characteristics mean that developers can focus on algorithm development and mathematical formulation without constantly worrying about performance optimization.
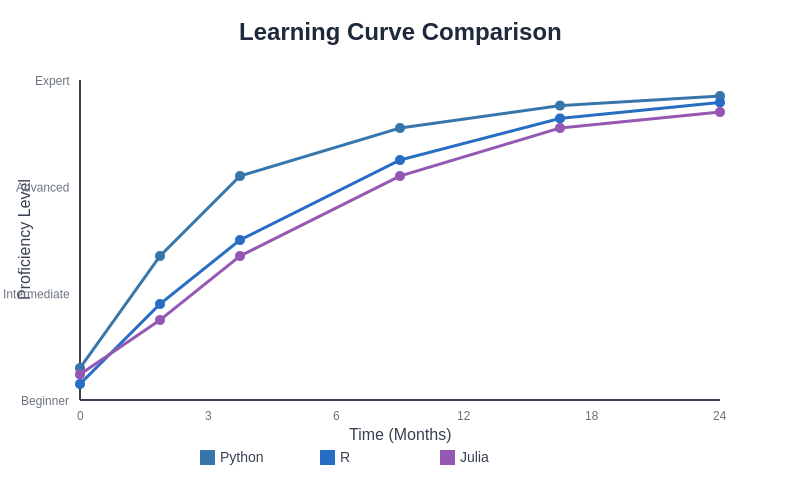
The learning trajectory analysis shows Python offering the fastest initial progress and easiest onboarding for beginners, while R requires more statistical background but provides steady advancement for data-focused applications. Julia presents a moderate learning curve with strong long-term potential for performance-critical applications.
Industry Adoption and Career Prospects
Industry adoption patterns for machine learning languages reflect a complex interplay of technical capabilities, ecosystem maturity, and organizational factors. Python’s dominance in industry machine learning applications is overwhelming, with major technology companies, startups, and traditional enterprises standardizing on Python for most machine learning development. This widespread adoption creates a positive feedback loop where more investment in Python tools and libraries leads to even broader adoption and better career prospects for Python developers.
The industrial Python ecosystem extends far beyond core machine learning capabilities to include comprehensive support for production deployment, monitoring, and integration with enterprise systems. Cloud platforms like AWS, Google Cloud Platform, and Microsoft Azure provide extensive Python-based machine learning services, while containerization technologies like Docker and orchestration platforms like Kubernetes have excellent Python support. This comprehensive industrial ecosystem means that Python skills translate directly to practical value in production machine learning environments.
R’s industry adoption follows different patterns, with stronger representation in traditional industries like pharmaceuticals, finance, and academic research where statistical rigor and regulatory compliance are critical concerns. Many financial institutions use R for risk modeling, clinical research organizations rely on R for statistical analysis of trial data, and academic institutions use R for research publications and educational purposes. While R’s overall industry presence is smaller than Python’s, it maintains strong positions in specialized domains where its statistical capabilities provide distinct advantages.
The career prospects for R developers tend to be more specialized but can be highly lucrative in appropriate domains. Positions requiring advanced statistical expertise, regulatory compliance knowledge, or academic research experience often value R skills highly. Additionally, the combination of R expertise with domain knowledge in areas like finance, healthcare, or scientific research can create unique career opportunities that leverage both technical and subject matter expertise.
Julia’s industry adoption remains limited but is growing rapidly in certain specialized applications, particularly in scientific computing, quantitative finance, and high-performance computing environments. Companies and research institutions that require both high-level expressiveness and exceptional performance are increasingly evaluating Julia for critical applications. While the job market for Julia developers is currently small, early adopters may benefit from reduced competition and high demand for specialized expertise.
The career prospects for Julia developers likely depend on the language’s continued growth and ecosystem development. Organizations that adopt Julia for performance-critical applications may offer excellent opportunities for developers who can bridge the gap between high-level algorithm development and high-performance implementation. Additionally, as Julia’s ecosystem matures, it may become more attractive for broader machine learning applications, potentially creating increased demand for Julia expertise.
Future Trends and Predictions
The future landscape of machine learning programming languages will likely be shaped by several key trends that are already beginning to influence development practices and technology adoption. The increasing scale and complexity of machine learning applications will continue to drive demand for performance optimization, potentially favoring languages like Julia that can deliver both development productivity and computational efficiency. As datasets grow larger and models become more sophisticated, the performance advantages offered by compiled or just-in-time compiled languages may become increasingly important for practical applications.
The trend toward democratization of machine learning through automated tools and platforms may influence language adoption patterns in unexpected ways. As machine learning becomes more accessible to non-experts through no-code and low-code platforms, the demand for traditional programming skills may shift toward more specialized applications that require custom development. This shift could benefit languages like R, which excels in specialized statistical applications, and Julia, which provides advantages for custom algorithm development and high-performance computing.
The integration of machine learning with edge computing, mobile applications, and Internet of Things devices creates new requirements for deployment efficiency and resource optimization. Python’s interpreted nature and memory overhead may become limiting factors in these environments, potentially creating opportunities for more efficient alternatives. Julia’s compilation capabilities and R’s specialized statistical focus may find new applications in these emerging deployment scenarios.
The continued evolution of hardware architectures, including specialized AI accelerators, quantum computing platforms, and advanced GPU architectures, will likely influence programming language development and adoption. Languages that can effectively leverage new hardware capabilities while maintaining developer productivity will have significant advantages in future machine learning applications. Julia’s design philosophy of combining high-level expressiveness with low-level performance optimization positions it well for these emerging hardware trends.
The growing emphasis on explainable AI and model interpretability may favor languages and ecosystems that provide strong support for statistical analysis and visualization. R’s comprehensive statistical capabilities and sophisticated visualization tools align well with these requirements, potentially maintaining or strengthening its position in applications where model interpretability is crucial. Similarly, Julia’s mathematical expressiveness may prove valuable for implementing novel interpretability techniques and custom explanation methods.
Looking ahead to 2025 and beyond, the machine learning programming landscape will likely see continued diversification as different languages find their optimal niches rather than any single language achieving complete dominance. Python will likely maintain its position as the general-purpose machine learning language, benefiting from continued ecosystem development and industry investment. R will continue to excel in statistical applications and research environments, while potentially finding new applications in specialized domains requiring rigorous statistical analysis. Julia’s trajectory will depend largely on its ecosystem development and adoption by performance-critical applications, but its unique combination of ease of use and performance positions it well for growth in scientific computing and high-performance machine learning applications.
Making the Right Choice for Your Projects
Selecting the optimal programming language for machine learning projects requires careful consideration of multiple factors that extend beyond pure technical capabilities. Project requirements, team expertise, organizational constraints, and long-term maintenance considerations all play crucial roles in determining the most appropriate language choice. Understanding these factors and their relative importance for specific use cases enables more informed decision-making that aligns technical choices with business objectives and practical constraints.
For projects that prioritize rapid development, extensive library support, and easy integration with existing systems, Python represents the safest and most versatile choice. Its comprehensive ecosystem, extensive documentation, and large talent pool make it particularly suitable for startup environments, general-purpose machine learning applications, and projects that require integration with web services or cloud platforms. Python’s dominance in industry applications also means that knowledge and skills developed in Python projects are highly transferable and valuable in the job market.
Projects that require rigorous statistical analysis, hypothesis testing, or sophisticated data visualization may find R to be the superior choice despite its limitations in other areas. R’s unparalleled statistical capabilities and direct connection to academic research make it particularly valuable for applications in healthcare, finance, scientific research, and any domain where statistical validity and interpretability are paramount concerns. The language’s excellent support for reproducible research also makes it attractive for academic and regulatory environments.
Julia emerges as the optimal choice for projects that demand both high-level expressiveness and exceptional computational performance. Applications involving large-scale numerical computing, custom algorithm development, or performance-critical production systems may benefit significantly from Julia’s unique combination of ease of use and speed. However, organizations considering Julia must carefully evaluate their tolerance for ecosystem immaturity and the availability of Julia expertise in their talent pipeline.
Hybrid approaches that leverage multiple languages for different components of machine learning systems are becoming increasingly common and practical. Teams might use R for initial statistical analysis and model development, Python for data preprocessing and system integration, and Julia for performance-critical algorithm implementations. Modern containerization and microservices architectures make such multi-language approaches more feasible than in the past, allowing organizations to optimize language choice for specific components rather than making monolithic decisions.
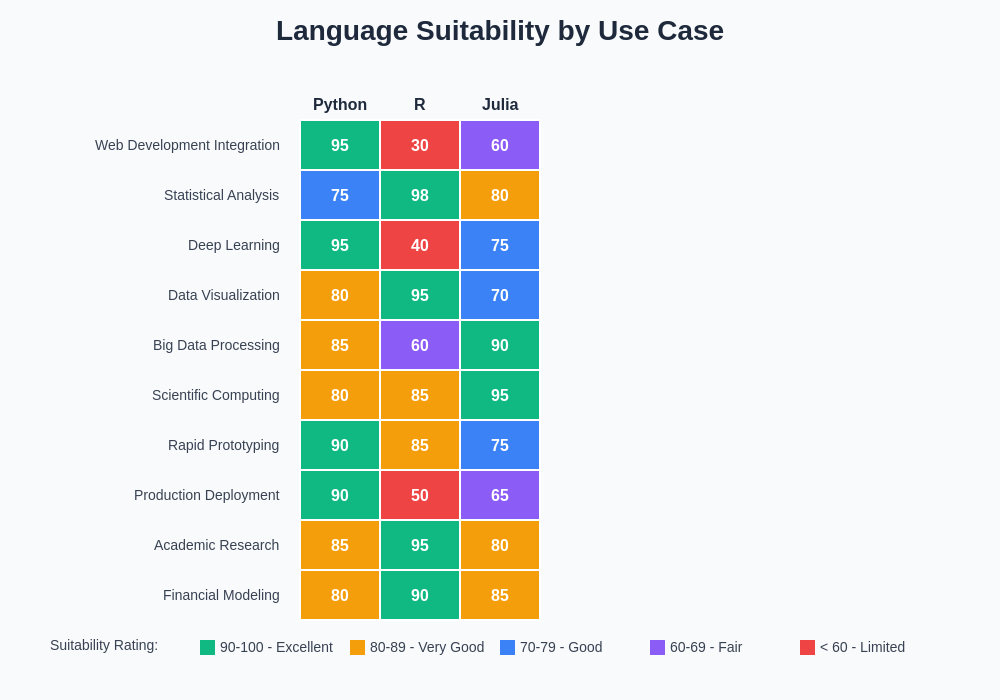
The comprehensive use case analysis demonstrates clear specialization patterns: Python excels in web development integration and deep learning applications, R dominates statistical analysis and academic research scenarios, while Julia shows particular strength in scientific computing and big data processing applications.
The decision framework should also consider long-term maintenance and evolution requirements. Projects with long lifecycles benefit from languages with stable ecosystems, extensive documentation, and large developer communities. Python and R both offer excellent long-term viability, while Julia’s trajectory, though promising, involves more uncertainty regarding future ecosystem development and community growth.
Conclusion
The comparison between Python, R, and Julia for machine learning in 2025 reveals a landscape where each language has carved out distinct advantages and optimal use cases rather than any single language achieving universal dominance. Python maintains its position as the versatile generalist, offering the best combination of ecosystem maturity, ease of learning, and industrial applicability for the majority of machine learning projects. Its comprehensive library support, extensive community resources, and seamless integration capabilities make it the default choice for most commercial machine learning applications.
R continues to excel in its traditional strongholds of statistical analysis and research applications, providing unmatched capabilities for rigorous statistical modeling, data visualization, and reproducible research. While its overall market share may be smaller than Python’s, R’s specialized strengths ensure its continued relevance in domains where statistical rigor and mathematical sophistication are paramount concerns.
Julia represents the most intriguing development in this comparison, offering a compelling vision of high-performance scientific computing that eliminates traditional trade-offs between development productivity and computational efficiency. While its ecosystem remains less mature than its competitors, Julia’s technical advantages and growing community suggest significant potential for expansion into performance-critical machine learning applications.
The future of machine learning programming will likely see continued coexistence and specialization of these languages rather than convergence toward a single solution. Teams and organizations that understand the unique strengths of each language and can strategically apply them to appropriate use cases will be best positioned to leverage the full potential of modern machine learning technologies while maintaining practical development efficiency and long-term maintainability.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on current understanding of programming languages and their applications in machine learning as of 2024. Technology landscapes evolve rapidly, and readers should conduct their own research and consider their specific requirements when selecting programming languages for machine learning projects. Performance comparisons and feature assessments may vary depending on specific use cases, hardware configurations, and implementation approaches.