The exponential growth of data volumes and the increasing complexity of machine learning models have created an urgent demand for distributed computing solutions that can scale beyond the limitations of single-machine processing. In this landscape, two Python-based frameworks have emerged as leading contenders for distributed computing in machine learning: Ray and Dask. Both frameworks promise to democratize distributed computing by providing intuitive APIs that enable data scientists and machine learning engineers to scale their computations across multiple cores and machines with minimal code changes.
Explore the latest AI and machine learning trends to understand how distributed computing frameworks are shaping the future of scalable AI applications. The choice between Ray and Dask represents more than just a technical decision; it fundamentally determines how organizations approach scalability, performance optimization, and resource utilization in their machine learning pipelines.
The evolution of distributed computing frameworks has been driven by the recognition that traditional single-threaded Python execution becomes a significant bottleneck when dealing with large datasets, complex model training procedures, and computationally intensive feature engineering tasks. Both Ray and Dask address these challenges through different architectural philosophies and design principles, each offering unique advantages for specific use cases and computational patterns.
Understanding Ray: The Universal Distributed Computing Framework
Ray represents a paradigm shift in how distributed computing systems are designed and implemented, offering a unified framework that seamlessly handles both data processing and machine learning workloads. Originally developed at UC Berkeley’s RISELab, Ray has evolved into a comprehensive ecosystem that encompasses not only distributed computing primitives but also specialized libraries for machine learning, reinforcement learning, and hyperparameter tuning. The framework’s architecture is built around the concept of tasks and actors, providing developers with flexible abstractions that can be composed to create sophisticated distributed applications.
The core strength of Ray lies in its ability to provide low-latency distributed computing capabilities while maintaining simplicity in its programming model. Unlike traditional distributed computing frameworks that often require extensive configuration and deep understanding of cluster management, Ray abstracts away much of this complexity through its intelligent scheduling system and automatic resource management. This approach enables data scientists and machine learning practitioners to focus on their algorithms and models rather than the intricacies of distributed system management.
Ray’s ecosystem extends far beyond basic distributed computing, encompassing specialized libraries such as Ray Tune for hyperparameter optimization, Ray Serve for model serving, and Ray RLlib for reinforcement learning. This comprehensive approach creates a unified platform where the entire machine learning lifecycle can be managed and scaled using consistent APIs and architectural patterns, reducing the cognitive overhead associated with managing multiple disparate tools and frameworks.
Exploring Dask: Flexible Parallel Computing for Analytics
Dask approaches distributed computing from a different angle, focusing primarily on extending the familiar pandas and NumPy APIs to distributed environments. This design philosophy makes Dask particularly appealing to data scientists who are already comfortable with the Python scientific computing ecosystem and want to scale their existing workflows without learning entirely new programming paradigms. Dask’s strength lies in its ability to provide familiar interfaces while handling the complexity of distributed computation behind the scenes.
The architecture of Dask is built around dynamic task graphs that represent computations as directed acyclic graphs, enabling sophisticated optimization strategies such as task fusion, data locality optimization, and intelligent caching. This approach allows Dask to optimize computation patterns automatically, often achieving performance improvements that would be difficult to implement manually in traditional distributed computing frameworks.
Enhance your development workflow with Claude AI to leverage advanced reasoning capabilities for complex distributed computing architectures and optimization strategies. Dask’s flexibility extends to its deployment options, supporting everything from local multi-core processing to large-scale cluster deployments on cloud platforms, making it suitable for organizations with diverse infrastructure requirements and scaling needs.
Architectural Foundations and Design Philosophy
The fundamental architectural differences between Ray and Dask reflect their distinct design philosophies and target use cases. Ray employs a centralized scheduling approach with a global control store that maintains cluster state and coordinates task execution across distributed workers. This architecture enables Ray to provide strong consistency guarantees and sophisticated scheduling policies that can optimize for various objectives such as minimizing latency, maximizing throughput, or balancing resource utilization across the cluster.
Dask, in contrast, utilizes a more decentralized approach where task graphs are constructed dynamically and can be executed using various schedulers depending on the deployment context. The single-machine threaded scheduler is optimized for development and small-scale processing, while the distributed scheduler provides scalability for production workloads. This flexibility allows Dask to adapt to different deployment scenarios and performance requirements without requiring significant changes to user code.
The memory management strategies employed by these frameworks also differ significantly. Ray implements a distributed object store that enables efficient sharing of large objects across tasks and actors, reducing serialization overhead and enabling sophisticated caching strategies. Dask focuses on lazy evaluation and intelligent task graph optimization, minimizing memory usage through techniques such as task fusion and automatic garbage collection of intermediate results.
Performance Characteristics and Scalability Patterns
Performance evaluation of distributed computing frameworks requires careful consideration of various factors including task granularity, communication patterns, data locality, and fault tolerance mechanisms. Ray excels in scenarios involving fine-grained tasks, low-latency communication requirements, and stateful computations that benefit from the actor model. The framework’s shared memory object store and efficient serialization mechanisms make it particularly well-suited for machine learning workloads that involve frequent sharing of large model parameters or feature matrices.
Dask demonstrates superior performance in coarse-grained analytical workloads that align well with its optimization strategies. The framework’s ability to optimize task graphs and minimize data movement makes it highly effective for traditional data processing pipelines, exploratory data analysis, and batch processing scenarios. Dask’s integration with the existing NumPy and pandas ecosystem also provides performance benefits through optimized implementations of common operations and the ability to leverage existing C and Fortran libraries.
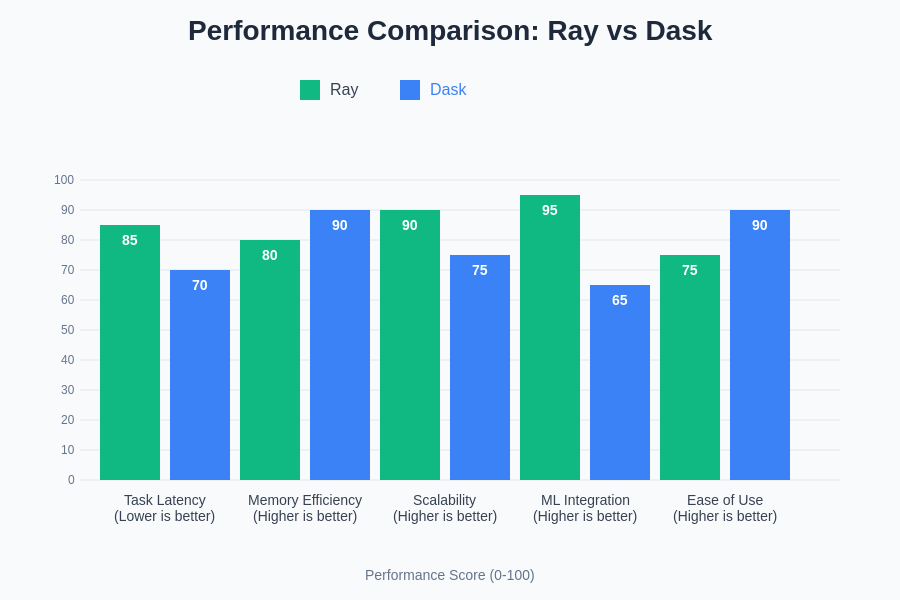
The scalability characteristics of both frameworks depend heavily on the specific workload patterns and cluster configurations. Ray’s centralized scheduling approach can become a bottleneck in extremely large clusters or scenarios with very high task creation rates, although recent architectural improvements have significantly mitigated these limitations. Dask’s distributed scheduler scales well with cluster size but may face challenges with very dynamic workloads that don’t align well with its task graph optimization strategies.
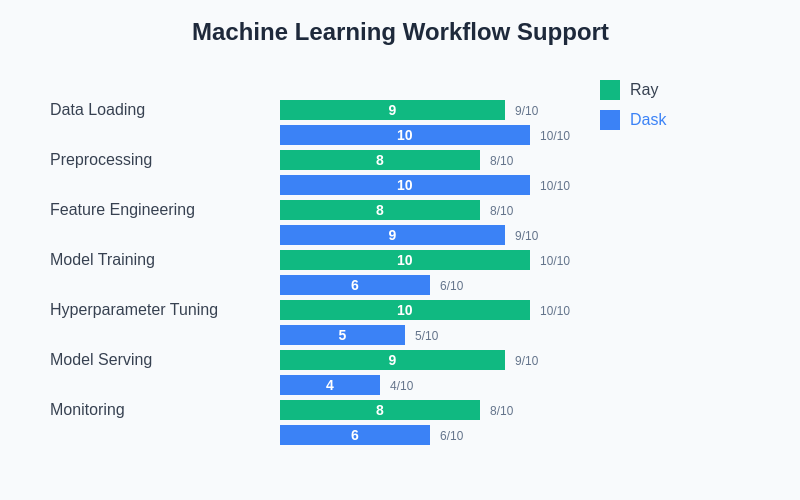
The comprehensive evaluation of machine learning workflow support reveals distinct strengths in each framework’s approach to different stages of the ML pipeline. Ray demonstrates superior performance in model training, hyperparameter tuning, and serving scenarios, while Dask excels in data loading, preprocessing, and traditional analytical workloads.
Machine Learning Integration and Ecosystem Support
The machine learning ecosystem integration represents one of the most significant differentiating factors between Ray and Dask. Ray provides native support for distributed machine learning through Ray ML, which includes distributed implementations of popular algorithms and seamless integration with frameworks such as TensorFlow, PyTorch, and Scikit-learn. This integration extends beyond simple parallelization to include sophisticated features such as distributed hyperparameter optimization, federated learning capabilities, and advanced model serving infrastructure.
Ray Tune, the hyperparameter optimization library within the Ray ecosystem, demonstrates the framework’s commitment to providing end-to-end machine learning solutions. The library supports various optimization algorithms, early stopping strategies, and resource allocation policies, enabling efficient exploration of hyperparameter spaces even for computationally expensive models. The integration with popular machine learning libraries is seamless, requiring minimal code changes to scale existing training procedures across distributed resources.
Dask’s machine learning capabilities center around Dask-ML, which provides distributed implementations of Scikit-learn algorithms and preprocessing utilities. While not as comprehensive as Ray’s machine learning ecosystem, Dask-ML excels in scenarios involving large-scale feature engineering, data preprocessing, and traditional machine learning algorithms that benefit from Dask’s array and DataFrame abstractions. The framework’s strength lies in its ability to scale existing pandas and NumPy-based workflows with minimal modifications.
Development Experience and Learning Curve
The development experience and associated learning curve represent crucial factors in framework adoption, particularly for teams with varying levels of distributed computing expertise. Ray’s programming model, based on decorators and remote function calls, provides an intuitive abstraction that allows developers to convert existing Python functions into distributed tasks with minimal code changes. This approach significantly reduces the barrier to entry for distributed computing while providing access to advanced features for users who need them.
The Ray ecosystem’s comprehensive documentation, extensive example collection, and active community support contribute to a positive development experience. The framework’s integration with popular development tools and cloud platforms simplifies the deployment and management of distributed applications, enabling teams to focus on their core machine learning objectives rather than infrastructure concerns.
Dask’s development experience is characterized by its familiar API design that closely mirrors existing pandas and NumPy interfaces. This similarity allows data scientists to leverage their existing knowledge while gaining access to distributed computing capabilities. The lazy evaluation model and intelligent task graph visualization tools provide valuable insights into computation patterns and performance characteristics, facilitating debugging and optimization of distributed workflows.
Access comprehensive AI research capabilities with Perplexity to stay updated on the latest developments in distributed computing frameworks and their applications in machine learning. The combination of both platforms creates a powerful knowledge base for making informed decisions about distributed computing architecture choices.
Fault Tolerance and Reliability Mechanisms
Fault tolerance represents a critical consideration for distributed computing frameworks, particularly in production environments where hardware failures, network partitions, and transient errors are inevitable. Ray implements a comprehensive fault tolerance mechanism that includes automatic task retry, actor reconstruction, and cluster-level failure recovery. The framework’s lineage tracking enables efficient reconstruction of lost computations, while its distributed object store provides redundancy for critical data objects.
The Ray cluster’s self-healing capabilities extend to automatic node replacement and dynamic scaling, enabling resilient operation even in unreliable cloud environments. These features are particularly important for long-running machine learning workloads such as hyperparameter optimization or reinforcement learning training that may span hours or days. The framework’s ability to maintain progress despite individual node failures significantly improves the reliability of distributed machine learning pipelines.
Dask’s fault tolerance mechanisms are primarily based on task graph reconstruction and automatic retry of failed computations. The framework’s functional approach to computation enables efficient recomputation of lost results, while its integration with cluster managers such as Kubernetes and YARN provides infrastructure-level resilience. Dask’s approach to fault tolerance is well-suited for batch processing workloads where occasional recomputation is acceptable and the focus is on eventual consistency rather than real-time reliability.
Resource Management and Cost Optimization
Effective resource management and cost optimization become increasingly important as distributed computing workloads scale to larger clusters and longer execution times. Ray provides sophisticated resource allocation mechanisms that enable fine-grained control over CPU, memory, and GPU resources for individual tasks and actors. This granular control allows for efficient resource utilization in heterogeneous clusters where different computations have varying resource requirements.
The Ray cluster’s autoscaling capabilities automatically adjust cluster size based on workload demands, providing cost optimization for cloud deployments where resources are billed based on usage. The framework’s integration with cloud-native technologies such as Kubernetes enables sophisticated resource management policies that can balance performance requirements with cost constraints. These capabilities are particularly valuable for organizations running variable workloads or those seeking to optimize their cloud spending.
Dask’s resource management approach focuses on automatic optimization of computation patterns and efficient utilization of available resources. The framework’s ability to optimize task graphs and minimize data movement reduces overall resource requirements while improving performance. Dask’s integration with cluster schedulers enables sophisticated resource allocation policies that can prioritize different workloads based on organizational requirements and resource constraints.
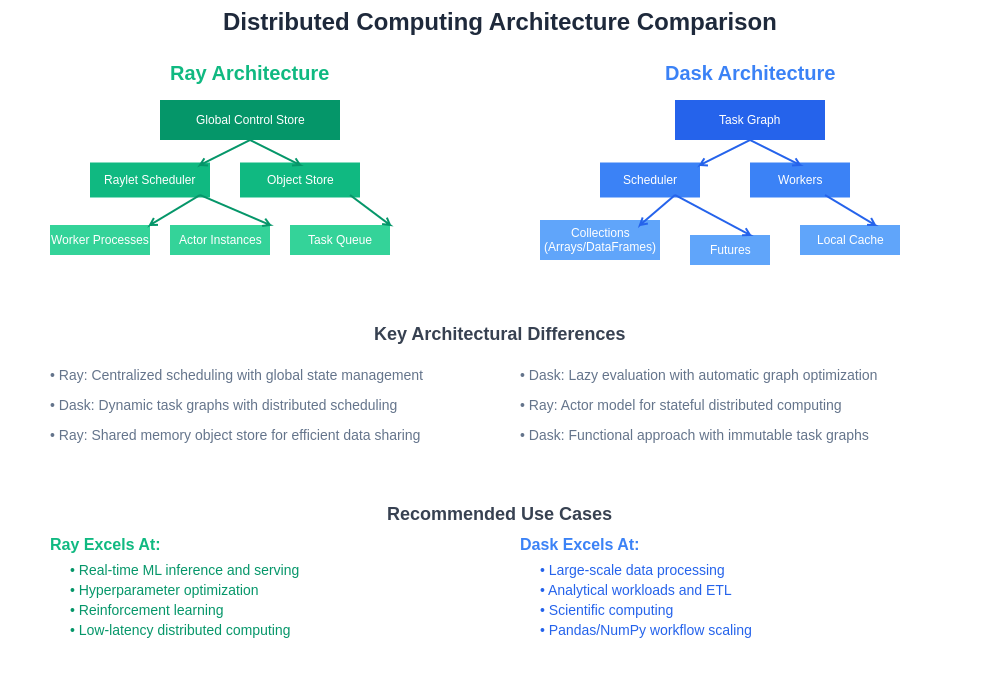
The architectural differences between Ray and Dask reflect fundamentally different approaches to distributed computing, each optimized for specific use cases and performance requirements. Understanding these architectural patterns is crucial for making informed decisions about framework selection and deployment strategies.
Use Case Analysis and Selection Criteria
The selection between Ray and Dask should be based on careful analysis of specific use case requirements, organizational constraints, and long-term strategic objectives. Ray excels in scenarios involving real-time machine learning applications, reinforcement learning workloads, and situations requiring low-latency distributed computing capabilities. The framework’s comprehensive machine learning ecosystem makes it particularly attractive for organizations seeking an integrated platform for the entire ML lifecycle.
Ray’s strength in handling stateful computations and providing consistent performance across varying workload patterns makes it well-suited for production machine learning systems that require predictable behavior and robust fault tolerance. The framework’s extensive hyperparameter optimization capabilities and model serving infrastructure provide additional value for organizations focused on deploying and maintaining machine learning models at scale.
Dask is ideally suited for analytical workloads, data preprocessing pipelines, and scenarios where familiarity with existing Python data science tools is paramount. The framework’s ability to scale existing pandas and NumPy workflows with minimal code changes makes it an excellent choice for teams seeking to incrementally adopt distributed computing without extensive retraining or workflow modifications.
Organizations with significant investments in the traditional Python data science ecosystem may find Dask’s familiar APIs and gradual scaling approach more appealing than Ray’s more comprehensive but potentially overwhelming feature set. Dask’s strength in batch processing and analytical workloads makes it particularly suitable for traditional business intelligence applications and exploratory data analysis at scale.
Integration with Cloud Platforms and DevOps Practices
Modern distributed computing frameworks must integrate seamlessly with cloud platforms and contemporary DevOps practices to be viable for production deployments. Ray provides extensive cloud integration capabilities through Ray Clusters, which offer native support for major cloud providers including AWS, Google Cloud Platform, and Microsoft Azure. The framework’s Kubernetes operator enables sophisticated deployment patterns and resource management policies that align with cloud-native architectural principles.
Ray’s integration with machine learning platforms such as MLflow, Weights & Biases, and TensorBoard provides comprehensive observability and experiment tracking capabilities that are essential for production machine learning workflows. The framework’s support for containerized deployments and CI/CD pipelines enables teams to implement robust deployment and testing practices for their distributed computing applications.
Dask’s cloud integration capabilities focus primarily on leveraging existing cluster management solutions such as Kubernetes, YARN, and cloud-specific schedulers. This approach provides flexibility in deployment strategies while enabling organizations to leverage their existing infrastructure investments and operational expertise. Dask’s compatibility with various deployment patterns makes it suitable for organizations with diverse infrastructure requirements or those seeking to maintain consistency across different environments.
The framework’s integration with popular data engineering tools and workflow orchestrators such as Apache Airflow enables sophisticated pipeline management capabilities that are essential for production data processing workflows. Dask’s ability to integrate with existing data infrastructure and processing pipelines provides significant value for organizations seeking to enhance their current capabilities rather than replace them entirely.
Future Outlook and Technology Evolution
The distributed computing landscape continues to evolve rapidly, driven by advances in hardware architectures, networking technologies, and machine learning methodologies. Ray’s development trajectory focuses on expanding its machine learning capabilities, improving performance for large-scale workloads, and enhancing integration with emerging technologies such as edge computing and federated learning. The framework’s commitment to providing a unified platform for diverse computing workloads positions it well for future technological developments.
The ongoing development of specialized hardware such as TPUs, neuromorphic processors, and quantum computing devices will require distributed computing frameworks to evolve their resource management and task scheduling capabilities. Ray’s flexible architecture and active development community provide a strong foundation for adapting to these technological changes while maintaining backward compatibility and ease of use.
Dask’s future development emphasizes improving performance for analytical workloads, expanding integration with the broader data science ecosystem, and enhancing capabilities for streaming and real-time processing. The framework’s focus on maintaining familiar APIs while providing powerful distributed computing capabilities ensures continued relevance as the Python data science ecosystem evolves.
Both frameworks are investing in improved observability, debugging tools, and developer experience enhancements that will facilitate adoption and reduce the operational complexity associated with distributed computing. The continued maturation of these frameworks will likely result in more sophisticated optimization strategies, better fault tolerance mechanisms, and enhanced integration capabilities that benefit the entire distributed computing ecosystem.
Decision Framework and Implementation Strategies
Developing a systematic approach to framework selection requires careful consideration of technical requirements, organizational capabilities, and strategic objectives. Organizations should evaluate factors such as existing technology stacks, team expertise, performance requirements, and long-term scalability needs when choosing between Ray and Dask. The decision should also consider the total cost of ownership, including development time, operational complexity, and infrastructure requirements.
A phased implementation approach often provides the best balance between risk mitigation and capability development. Organizations can begin with pilot projects that demonstrate the value of distributed computing while building internal expertise and establishing best practices. This approach enables teams to evaluate framework capabilities in realistic scenarios while minimizing the impact of potential technical challenges or learning curve issues.
The selection criteria should include evaluation of community support, documentation quality, enterprise features, and vendor ecosystem partnerships that may influence long-term viability and support availability. Organizations should also consider the alignment between framework capabilities and their specific use cases, ensuring that the chosen solution provides value beyond simple parallelization and includes features that support their broader machine learning and data processing objectives.
Conclusion and Strategic Recommendations
The choice between Ray and Dask represents a strategic decision that will influence an organization’s distributed computing capabilities and machine learning infrastructure for years to come. Both frameworks offer compelling advantages for different use cases and organizational contexts, making the selection process highly dependent on specific requirements and constraints. Ray’s comprehensive machine learning ecosystem and low-latency distributed computing capabilities make it ideal for organizations focused on real-time applications, reinforcement learning, and integrated ML platforms.
Dask’s familiar APIs, excellent analytical performance, and gradual scaling approach provide significant value for organizations seeking to enhance existing data science workflows and analytical capabilities. The framework’s strength in traditional data processing scenarios and its compatibility with the broader Python ecosystem make it an excellent choice for teams prioritizing incremental adoption and minimal workflow disruption.
Organizations should approach framework selection as part of a broader distributed computing strategy that considers not only immediate technical requirements but also long-term scalability needs, team development objectives, and integration with existing systems and processes. The investment in distributed computing capabilities represents an opportunity to transform how data science and machine learning teams approach complex problems and scale their impact across the organization.
The continued evolution of both Ray and Dask ensures that organizations will have access to increasingly sophisticated distributed computing capabilities that can adapt to changing technological landscapes and business requirements. The key to success lies in thoughtful evaluation of specific needs, careful implementation planning, and commitment to building the organizational capabilities necessary to leverage these powerful distributed computing frameworks effectively.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on current understanding of distributed computing technologies and their applications in machine learning. Readers should conduct their own research and consider their specific requirements when selecting distributed computing frameworks. The effectiveness of these frameworks may vary depending on specific use cases, infrastructure requirements, and organizational capabilities. Performance characteristics and feature availability may change as both Ray and Dask continue to evolve.