The modern data landscape demands unprecedented speed and precision in analytics processing, particularly when artificial intelligence algorithms require immediate insights from continuously flowing data streams. Real-time AI analytics represents the convergence of high-performance database technologies, sophisticated stream processing frameworks, and machine learning algorithms that together enable organizations to extract actionable intelligence from data as it arrives, rather than waiting for traditional batch processing cycles to complete.
Explore the latest developments in AI analytics to understand how cutting-edge technologies are reshaping data processing and real-time decision making capabilities. The integration of specialized database systems like ClickHouse and TimescaleDB with advanced stream processing architectures has created a new paradigm where millisecond-level response times and petabyte-scale data handling become not just possible, but practical for enterprise applications.
The Evolution of Real-Time Analytics Architecture
Traditional analytics architectures were designed around batch processing models that emphasized throughput over latency, processing large volumes of data in scheduled intervals that could span hours or even days. This approach, while suitable for historical analysis and reporting, falls short of meeting the demands of modern AI applications that require immediate responses to changing conditions, real-time fraud detection, dynamic pricing adjustments, and instant personalization based on user behavior patterns.
The emergence of real-time analytics architecture represents a fundamental shift toward event-driven systems that can process, analyze, and respond to data as it streams through the system. This transformation has been enabled by advances in distributed computing, in-memory processing technologies, and specialized database systems optimized for time-series data and analytical workloads. The result is an ecosystem where artificial intelligence algorithms can operate on live data streams, making predictions and recommendations with minimal latency while maintaining the accuracy and reliability required for business-critical applications.
ClickHouse: Columnar Analytics Powerhouse
ClickHouse has emerged as a revolutionary force in the analytics database landscape, delivering unprecedented query performance through its innovative columnar storage architecture and aggressive optimization strategies. Originally developed by Yandex to handle massive web analytics workloads, ClickHouse has evolved into a comprehensive platform capable of supporting complex AI analytics scenarios that demand both speed and scalability.
The fundamental architecture of ClickHouse is built around columnar data storage, which provides significant advantages for analytical workloads by enabling efficient compression, vectorized query execution, and optimal I/O patterns that align with the access patterns typical of analytics queries. This design philosophy extends to every aspect of the system, from its custom query processing engine that can execute complex aggregations across billions of rows in seconds, to its distributed architecture that can scale horizontally across hundreds of nodes while maintaining query performance.
Enhance your analytics capabilities with Claude’s advanced reasoning for complex data analysis and optimization strategies that maximize the performance of your real-time analytics infrastructure. The integration of ClickHouse into AI analytics workflows enables organizations to process massive volumes of structured and semi-structured data with query response times measured in milliseconds rather than minutes or hours.
The performance characteristics of ClickHouse make it particularly well-suited for AI analytics applications that require rapid aggregation of historical data for model training, real-time feature computation for online machine learning systems, and fast retrieval of contextual information for recommendation engines. Its ability to handle complex analytical queries while maintaining consistent performance under high concurrent load makes it an ideal foundation for AI systems that must serve predictions and insights to large numbers of users simultaneously.
TimescaleDB: Time-Series Intelligence at Scale
TimescaleDB represents a specialized approach to time-series data management that combines the familiar SQL interface and ACID guarantees of PostgreSQL with optimizations specifically designed for time-stamped data. This hybrid approach has proven particularly valuable for AI analytics applications that must process sensor data, financial market information, IoT telemetry, and other time-series datasets that form the backbone of many machine learning and artificial intelligence systems.
The architecture of TimescaleDB introduces the concept of hypertables, which automatically partition time-series data across multiple chunks based on time intervals and optional space dimensions. This partitioning strategy enables the system to maintain optimal query performance as datasets grow into the petabyte range while providing the granular control over data retention, compression, and archival policies that are essential for managing long-term time-series datasets efficiently.
The advanced compression capabilities of TimescaleDB, including columnar compression for older data and sophisticated algorithms that can achieve compression ratios exceeding 90% while maintaining query performance, make it possible to store years of high-frequency data cost-effectively. This capability is particularly important for AI systems that require access to extensive historical datasets for training complex models while also serving real-time queries for inference and monitoring applications.
Stream Processing: The Neural Network of Data Flow
Stream processing technologies form the nervous system of real-time AI analytics architectures, enabling the continuous ingestion, transformation, and routing of data streams to appropriate processing and storage systems. Modern stream processing frameworks like Apache Kafka, Apache Flink, and Apache Pulsar have evolved beyond simple message passing to become sophisticated platforms capable of supporting complex event processing, stateful stream transformations, and exactly-once processing guarantees that are essential for mission-critical AI applications.
The integration of stream processing with AI analytics creates opportunities for implementing sophisticated event-driven architectures where machine learning models can respond to patterns in data streams as they emerge, trigger automated responses based on detected anomalies, and continuously update their understanding of system behavior based on streaming observations. This capability enables the development of adaptive AI systems that can modify their behavior in response to changing conditions without requiring human intervention or system restarts.
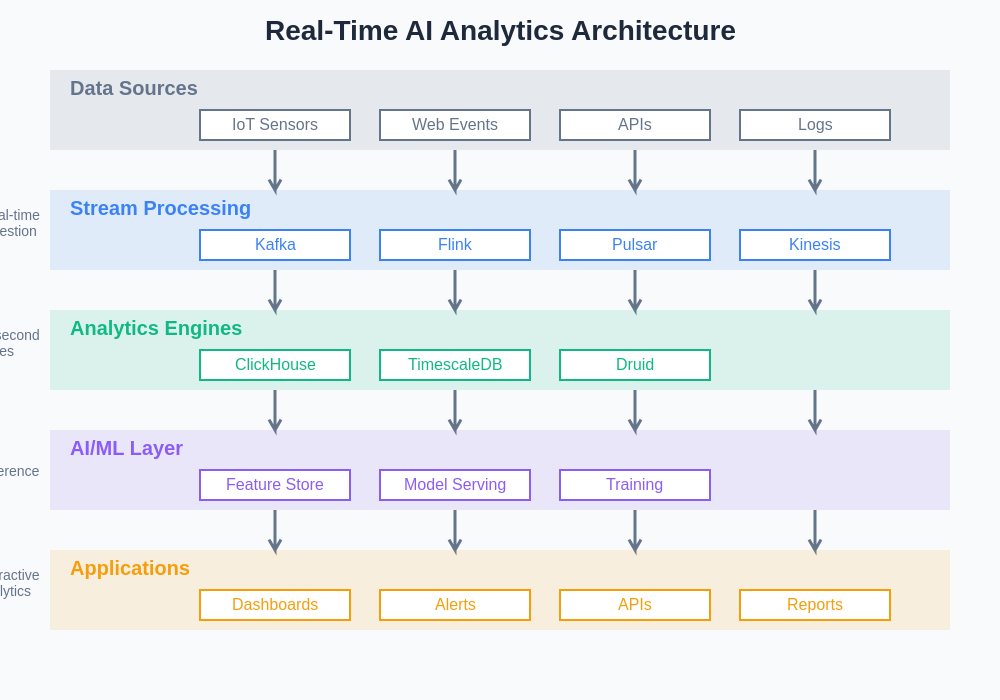
The layered architecture approach to real-time AI analytics provides clear separation of concerns while enabling efficient data flow from raw sources through processing stages to actionable insights. Each layer is optimized for specific functions while maintaining the flexibility to scale independently based on processing demands and performance requirements.
Architectural Patterns for Real-Time AI Analytics
The design of effective real-time AI analytics systems requires careful consideration of data flow patterns, processing latency requirements, and consistency guarantees that align with the specific needs of AI algorithms and business requirements. Lambda architecture patterns that combine batch and stream processing have given way to more sophisticated approaches that leverage the capabilities of modern stream processing frameworks to handle both real-time and historical data processing within unified architectures.
Kappa architecture represents an evolution toward stream-first designs where all data processing, including historical reprocessing, occurs within streaming frameworks that can handle both real-time and batch workloads efficiently. This approach simplifies system architecture while providing the flexibility to reprocess historical data with updated algorithms or respond to schema evolution without maintaining separate batch and streaming code paths.
Leverage Perplexity’s research capabilities to stay current with emerging architectural patterns and optimization techniques that can enhance your real-time analytics infrastructure performance and reliability. The combination of streaming architectures with AI-optimized databases creates a foundation for building systems that can scale to handle massive data volumes while maintaining the low-latency response times required for interactive AI applications.
Data Ingestion and Pipeline Optimization
Efficient data ingestion represents a critical bottleneck in real-time AI analytics systems, where the ability to process incoming data streams at scale determines the overall system performance and the freshness of insights available to AI algorithms. Modern ingestion frameworks must handle variable data rates, schema evolution, data quality validation, and routing decisions while maintaining high throughput and low latency characteristics.
The optimization of ingestion pipelines requires careful attention to serialization formats, partitioning strategies, and buffering mechanisms that can smooth out traffic spikes and ensure consistent performance under varying load conditions. Advanced ingestion systems incorporate features like automatic schema registry integration, data lineage tracking, and quality monitoring that enable robust operation in production environments where data quality and processing reliability are paramount.
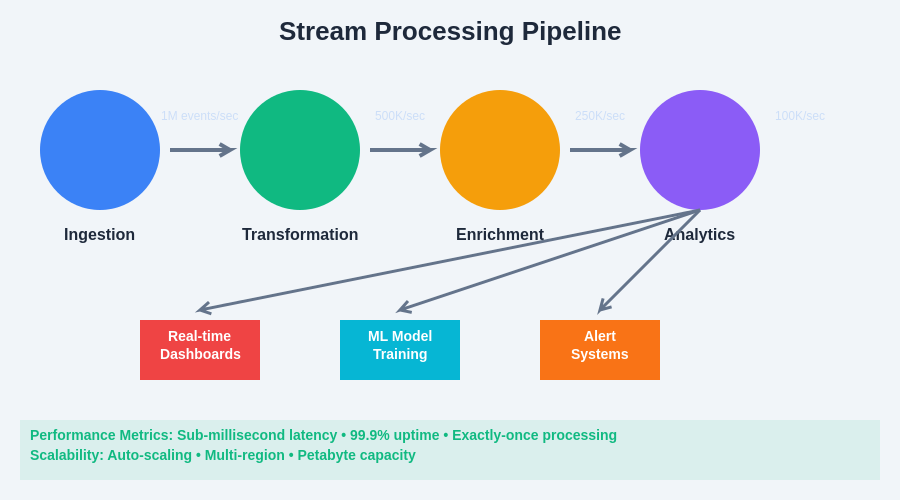
The stream processing pipeline architecture demonstrates the flow of data through various transformation stages, from initial ingestion through enrichment and analytics processing to final output destinations. Each stage is designed to handle specific processing requirements while maintaining high throughput and low latency characteristics essential for real-time AI applications.
Feature Engineering and Real-Time Computation
Feature engineering in real-time AI analytics systems presents unique challenges related to maintaining consistency between training and serving environments, handling late-arriving data, and computing complex features that depend on historical context or cross-entity relationships. Modern feature stores and computation frameworks have evolved to address these challenges by providing unified APIs for feature definition, storage, and retrieval that work consistently across batch training and real-time serving scenarios.
The implementation of real-time feature computation often requires sophisticated caching strategies, incremental computation algorithms, and conflict resolution mechanisms that can handle out-of-order data arrival while maintaining feature consistency. Advanced systems incorporate capabilities for feature versioning, A/B testing of feature implementations, and monitoring of feature drift that could impact model performance in production environments.
Model Serving and Inference Optimization
The deployment of machine learning models within real-time analytics systems requires careful optimization of inference latency, throughput capacity, and resource utilization to meet the performance requirements of interactive applications. Model serving frameworks have evolved to support features like dynamic batching, model ensembling, and A/B testing that enable sophisticated deployment strategies while maintaining predictable performance characteristics.
Advanced model serving systems incorporate capabilities for automatic scaling based on traffic patterns, canary deployments for safe model updates, and comprehensive monitoring of model performance metrics that can detect drift, bias, or degradation in model quality. The integration of model serving with real-time data processing pipelines enables the creation of closed-loop systems where model predictions can influence data processing decisions and trigger automated responses to detected patterns or anomalies.
Performance Monitoring and Observability
Comprehensive monitoring and observability represent essential capabilities for maintaining reliable real-time AI analytics systems that must operate continuously under varying load conditions while meeting strict performance and accuracy requirements. Modern observability platforms provide detailed visibility into data pipeline performance, query execution patterns, model inference latency, and system resource utilization that enables proactive identification and resolution of performance issues.
The implementation of effective monitoring strategies requires careful selection of metrics that provide meaningful insights into system health while avoiding the overhead that could impact real-time performance. Advanced monitoring systems incorporate features like distributed tracing, anomaly detection on system metrics, and automated alerting that can identify developing issues before they impact user-facing applications or compromise data quality.
Scalability and High Availability Design
The design of scalable and highly available real-time AI analytics systems requires careful consideration of failure modes, data consistency requirements, and recovery strategies that can maintain system operation in the face of hardware failures, network partitions, and software defects. Modern distributed systems leverage techniques like replication, sharding, and consensus algorithms to provide fault tolerance while maintaining performance characteristics under normal operating conditions.
Advanced availability designs incorporate multi-region deployment strategies, automated failover mechanisms, and data replication policies that can maintain service availability even during significant infrastructure outages. The implementation of these capabilities requires careful attention to consistency models, conflict resolution strategies, and recovery procedures that can restore normal operation quickly while preserving data integrity and avoiding service disruption.
Security and Compliance Considerations
Security and compliance requirements present significant challenges for real-time AI analytics systems that must process sensitive data while maintaining audit trails, access controls, and data governance policies required by regulatory frameworks. Modern security architectures incorporate features like end-to-end encryption, fine-grained access controls, and comprehensive audit logging that enable compliant operation while maintaining the performance characteristics required for real-time analytics.
The implementation of security measures in streaming environments requires special attention to key management, certificate rotation, and secure communication protocols that can operate efficiently in high-throughput, low-latency scenarios. Advanced security frameworks provide capabilities for data masking, differential privacy, and secure multi-party computation that enable analytics on sensitive datasets while preserving privacy and meeting regulatory requirements.
Cost Optimization and Resource Management
Effective cost management for real-time AI analytics systems requires sophisticated approaches to resource allocation, auto-scaling, and workload optimization that can balance performance requirements with infrastructure costs. Modern cloud platforms provide detailed cost visibility and automated optimization tools that can adjust resource allocation based on actual usage patterns while maintaining service level objectives.
The optimization of resource utilization often requires careful analysis of workload patterns, data access frequencies, and processing requirements that can inform decisions about storage tiering, compute allocation, and network optimization. Advanced cost management strategies incorporate features like spot instance utilization, reserved capacity planning, and automated resource rightsizing that can significantly reduce operational costs while maintaining system performance.
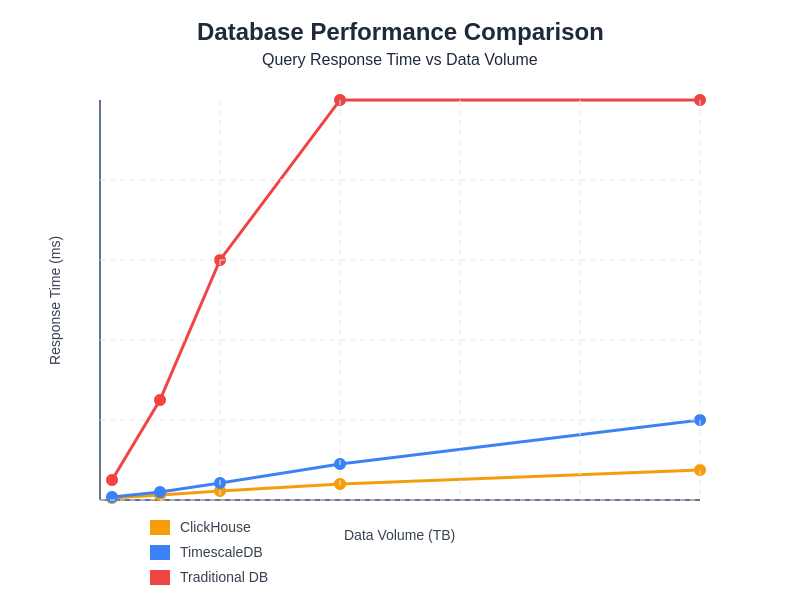
Performance benchmarks across different database technologies reveal significant differences in query response times as data volumes scale. ClickHouse demonstrates superior performance characteristics for analytical workloads, while TimescaleDB provides optimal performance for time-series specific operations, both significantly outperforming traditional database systems in real-time analytics scenarios.
Future Trends and Emerging Technologies
The evolution of real-time AI analytics continues to accelerate with advances in hardware acceleration, edge computing, and neuromorphic processing that promise to enable new classes of applications with even more demanding performance requirements. Emerging technologies like quantum computing, advanced GPU architectures, and specialized AI chips are beginning to influence system design decisions and create opportunities for breakthrough capabilities in real-time data processing and analysis.
The integration of edge computing with real-time analytics enables new deployment models where processing can occur closer to data sources, reducing latency and bandwidth requirements while enabling more responsive AI applications. Advanced edge architectures incorporate capabilities for distributed model serving, federated learning, and intelligent data filtering that can optimize the balance between local processing and centralized analytics while maintaining system coherence and data quality.
Implementation Best Practices and Lessons Learned
Successful implementation of real-time AI analytics systems requires careful attention to architectural decisions, technology selection, and operational practices that have been validated through production deployments across diverse industries and use cases. Best practices emphasize the importance of incremental system development, comprehensive testing strategies, and operational procedures that can maintain system reliability while supporting continuous evolution and improvement.
The lessons learned from production deployments highlight the critical importance of monitoring, alerting, and incident response procedures that can quickly identify and resolve issues that could impact system availability or data quality. Successful implementations also emphasize the value of cross-functional collaboration between data engineers, machine learning engineers, and operations teams that enables effective system design and reliable operation in production environments.
The continued advancement of real-time AI analytics technologies promises to enable new applications and use cases that were previously impractical due to performance, cost, or complexity constraints. Organizations that invest in building robust real-time analytics capabilities will be well-positioned to take advantage of these emerging opportunities while providing immediate value through improved decision-making, enhanced customer experiences, and more efficient operational processes.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The technologies and approaches discussed should be evaluated carefully in the context of specific requirements, existing infrastructure, and organizational constraints. Performance characteristics and capabilities may vary based on implementation details, data characteristics, and operational environments. Readers should conduct thorough testing and validation before implementing real-time AI analytics systems in production environments.