
The modern machine learning landscape demands sophisticated data infrastructure capable of processing massive volumes of information in real-time, transforming raw data streams into actionable insights that drive intelligent decision-making. At the heart of this transformation lie powerful streaming platforms that serve as the backbone of ML pipelines, enabling organizations to harness the full potential of their data assets through continuous processing and analysis. Two platforms have emerged as dominant forces in this space: Apache Kafka and Apache Pulsar, each offering unique architectural advantages and capabilities that cater to different aspects of machine learning workloads.
Explore the latest developments in streaming technologies to understand how real-time data processing is evolving alongside artificial intelligence and machine learning innovations. The choice between Kafka and Pulsar for ML applications represents more than a technical decision; it fundamentally shapes how organizations approach data architecture, system scalability, and the overall effectiveness of their machine learning initiatives.
The Foundation of Real-Time ML Infrastructure
Real-time machine learning applications require streaming platforms that can handle diverse data types, maintain low latency, ensure high throughput, and provide reliable message delivery guarantees. These requirements become particularly critical when dealing with applications such as fraud detection, recommendation systems, real-time personalization, and automated trading systems where milliseconds can determine success or failure. The streaming platform serves as the central nervous system that connects data producers, processing engines, and consumer applications in a seamless flow of information.
Both Kafka and Pulsar have been designed to address these challenges, but their architectural approaches and design philosophies differ significantly. Understanding these fundamental differences is crucial for making informed decisions about which platform best aligns with specific ML use cases and organizational requirements. The complexity of modern ML workflows, which often involve multiple data sources, various processing stages, and diverse consumer patterns, requires careful consideration of how each platform handles these scenarios.
Apache Kafka: The Battle-Tested Stream Processing Giant
Apache Kafka has established itself as the de facto standard for stream processing across industries, building a reputation for reliability, performance, and ecosystem maturity that spans over a decade of production deployments. Originally developed at LinkedIn to handle their massive data streaming needs, Kafka’s log-based architecture provides a robust foundation for building real-time ML applications that require guaranteed message ordering and durable storage of streaming data.
The platform’s strength lies in its simplicity and proven scalability, having been battle-tested in some of the world’s largest technology companies. Kafka’s partition-based approach to data distribution enables horizontal scaling while maintaining message ordering within partitions, making it particularly well-suited for ML applications that require sequential processing of events or maintain state across related messages. The extensive ecosystem surrounding Kafka, including Kafka Streams, Kafka Connect, and numerous third-party integrations, provides ML engineers with a comprehensive toolkit for building sophisticated streaming pipelines.
Enhance your streaming architecture with advanced AI tools like Claude to optimize data processing workflows and improve system design decisions through intelligent analysis and recommendations. The maturity of Kafka’s ecosystem means that most ML frameworks and tools have native integration capabilities, reducing development complexity and enabling faster time-to-market for streaming ML applications.
Apache Pulsar: The Next-Generation Cloud-Native Alternative
Apache Pulsar represents a newer approach to distributed messaging and streaming, designed from the ground up to address some of the limitations and operational challenges associated with traditional streaming platforms. Originally developed at Yahoo to handle their global-scale messaging requirements, Pulsar introduces innovative architectural concepts such as segment-centric storage and multi-layer architecture that provide significant advantages for certain ML use cases.
Pulsar’s cloud-native design emphasizes operational simplicity, automatic scaling, and multi-tenancy capabilities that align well with modern containerized deployment patterns. The platform’s ability to seamlessly handle both streaming and queuing workloads in a unified system makes it particularly attractive for ML applications that require diverse messaging patterns and consumption models. The separation of serving and storage layers in Pulsar’s architecture enables independent scaling of compute and storage resources, providing more flexibility in resource optimization for ML workloads.
Architectural Foundations and Design Philosophy
The fundamental architectural differences between Kafka and Pulsar have profound implications for ML applications, particularly in terms of scalability, operational complexity, and performance characteristics. Kafka’s monolithic broker architecture combines message serving, storage, and replication responsibilities into a single process, creating tight coupling between compute and storage resources. This design provides excellent performance and simplicity but can lead to challenges when scaling individual components or managing storage independently.
Pulsar’s multi-layer architecture separates these concerns, with Apache BookKeeper handling persistent storage while Pulsar brokers focus on serving messages and managing metadata. This separation enables more granular scaling decisions and provides better resource utilization for ML workloads with varying compute and storage requirements. The architectural flexibility of Pulsar allows ML teams to optimize costs by scaling compute and storage independently based on actual usage patterns rather than being constrained by the limitations of monolithic scaling.
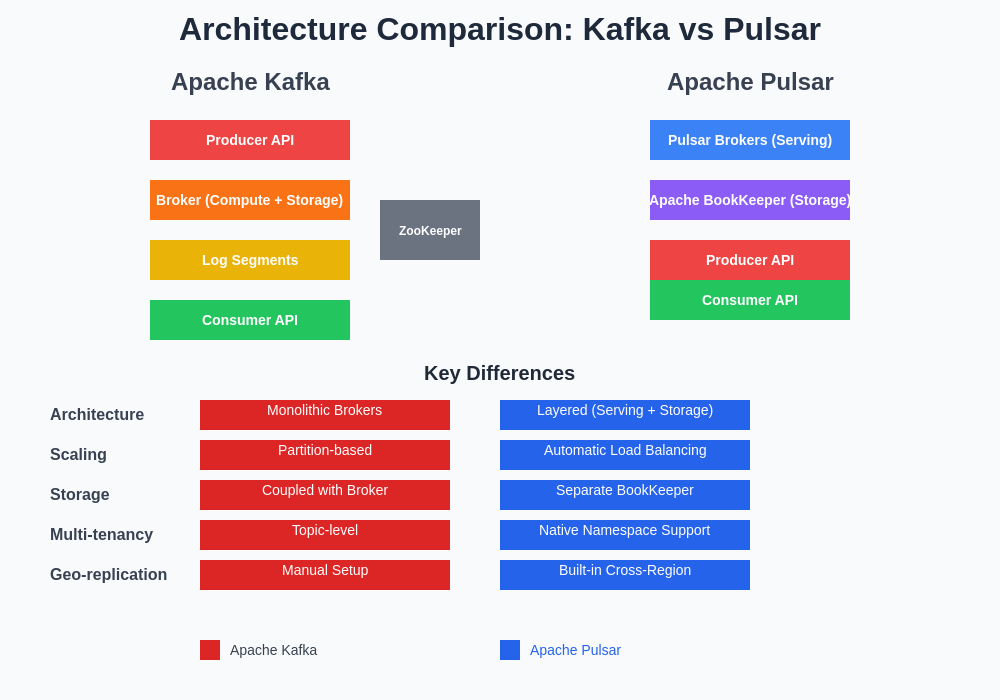
The architectural distinctions between these platforms directly impact how ML applications handle data persistence, replication, and recovery scenarios. Understanding these differences is crucial for designing resilient ML systems that can maintain service availability and data integrity under various failure conditions.
Performance Characteristics for ML Workloads
Performance evaluation for ML streaming platforms must consider multiple dimensions including throughput, latency, resource utilization, and scalability characteristics under diverse workload patterns. Kafka’s mature optimization and extensive tuning options have resulted in exceptional performance for high-throughput scenarios, making it the preferred choice for ML applications that prioritize maximum data ingestion rates and can tolerate slightly higher operational complexity.
The platform’s zero-copy optimization, efficient batch processing, and mature client libraries contribute to its superior performance in scenarios involving large message volumes and high-frequency data streams. ML applications such as real-time feature extraction from high-velocity sensor data or processing massive streams of user interaction events often benefit from Kafka’s optimized performance characteristics.
Pulsar’s performance profile reflects its focus on operational simplicity and cloud-native deployment patterns. While it may not match Kafka’s peak throughput in all scenarios, Pulsar provides more predictable performance characteristics and better resource utilization efficiency, particularly in multi-tenant environments where multiple ML applications share the same streaming infrastructure. The platform’s automatic load balancing and dynamic scaling capabilities reduce the operational overhead associated with maintaining optimal performance across varying workloads.
Scalability and Resource Management
Scalability considerations for ML streaming platforms extend beyond simple horizontal scaling to encompass dynamic resource allocation, multi-tenancy support, and cost optimization strategies. Kafka’s partition-based scaling model provides excellent performance but requires careful planning and manual intervention to optimize resource utilization and handle changing workload patterns. ML teams must proactively manage partition distribution, broker allocation, and storage capacity to maintain optimal performance as data volumes and processing requirements evolve.
The platform’s scaling approach works exceptionally well for predictable workloads with steady growth patterns but can present challenges for ML applications with highly variable or bursty traffic patterns. Scaling decisions often require deep understanding of Kafka’s internal mechanics and careful coordination between different operational teams to ensure smooth scaling operations without service disruption.
Leverage advanced research capabilities with Perplexity to stay informed about scaling best practices and emerging patterns in streaming platform optimization for ML applications. Pulsar’s approach to scalability emphasizes automation and cloud-native principles, providing automatic load balancing, dynamic broker discovery, and intelligent partition assignment that reduces the operational burden on ML teams.
Data Durability and Consistency Guarantees
Data integrity and consistency guarantees play a critical role in ML applications where data loss or duplication can significantly impact model training, inference accuracy, and business outcomes. Kafka’s log-based storage model provides strong durability guarantees through configurable replication factors and acknowledgment modes that allow ML applications to balance between performance and data safety requirements.
The platform’s exactly-once semantics, implemented through idempotent producers and transactional messaging, ensures that ML pipelines can process data reliably without introducing duplicates or data corruption. These guarantees are particularly important for financial ML applications, where data accuracy directly impacts regulatory compliance and business risk management.
Pulsar’s layered architecture provides similar durability guarantees while offering additional flexibility in storage configuration and disaster recovery scenarios. The separation of serving and storage layers enables more sophisticated backup and recovery strategies, allowing ML teams to implement geo-distributed deployments with automatic failover capabilities that maintain data consistency across multiple data centers.
Integration with ML Frameworks and Tools
The ecosystem integration capabilities of streaming platforms significantly influence their suitability for ML applications, as seamless connectivity with popular ML frameworks, feature stores, and model serving platforms reduces development complexity and accelerates deployment cycles. Kafka’s mature ecosystem provides native integration with virtually all major ML platforms including Apache Spark, Apache Flink, TensorFlow, and cloud-native ML services from major providers.
The extensive library of Kafka connectors enables direct integration with databases, data warehouses, and external APIs, simplifying the creation of comprehensive ML data pipelines that span multiple systems and data sources. This ecosystem maturity translates into reduced development time, better community support, and more extensive documentation for common integration patterns and troubleshooting scenarios.
Pulsar’s growing ecosystem provides similar integration capabilities with a focus on modern cloud-native deployments and containerized environments. The platform’s Functions feature provides built-in stream processing capabilities that can handle simple ML preprocessing tasks without requiring external stream processing frameworks, reducing infrastructure complexity for lightweight ML applications.
Operational Complexity and Management Overhead
Operational considerations often become the deciding factor in platform selection, as the long-term success of ML streaming infrastructure depends heavily on the team’s ability to maintain, monitor, and optimize the system effectively. Kafka’s operational model requires specialized expertise in cluster management, performance tuning, and troubleshooting complex distributed system issues that can arise in production environments.
The platform’s configuration complexity, with hundreds of tuning parameters and interdependent settings, demands deep understanding of Kafka internals to achieve optimal performance and reliability. ML teams must invest significant resources in developing operational expertise and establishing monitoring and alerting systems that can detect and respond to various failure modes and performance degradation scenarios.
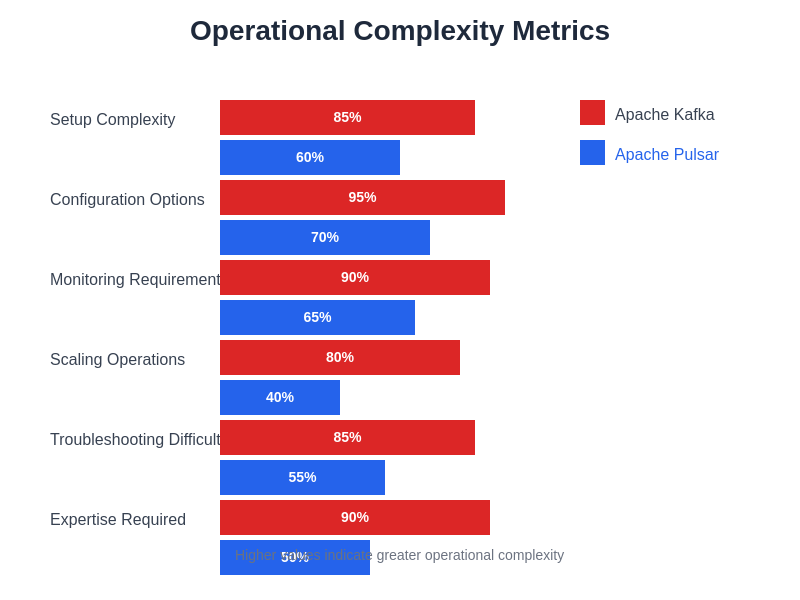
Pulsar’s design philosophy prioritizes operational simplicity through automated management features, self-healing capabilities, and intelligent resource allocation that reduces the expertise required for day-to-day operations. The platform’s cloud-native architecture aligns well with modern DevOps practices and containerized deployment patterns that many ML teams have already adopted.
Cost Considerations and Resource Efficiency
Cost optimization for streaming platforms involves multiple factors including infrastructure resources, operational overhead, development velocity, and long-term maintenance requirements. Kafka’s resource utilization patterns and scaling characteristics can lead to over-provisioning in environments with variable workloads, as the platform requires sufficient resources to handle peak loads even during periods of lower activity.
The operational expertise required for Kafka optimization represents a significant ongoing cost that organizations must factor into their total cost of ownership calculations. However, Kafka’s exceptional performance and ecosystem maturity can provide substantial value for organizations with high-volume, mission-critical ML applications that justify the investment in specialized operational expertise.
Pulsar’s resource efficiency and automatic scaling capabilities can provide cost advantages for organizations with variable workloads or multi-tenant environments where resources are shared across multiple ML applications. The platform’s operational simplicity reduces the staffing requirements for infrastructure management, potentially offsetting higher per-unit resource costs with reduced operational expenses.
Security and Compliance Considerations
Security requirements for ML streaming platforms encompass data encryption, access control, audit logging, and compliance with industry regulations that govern data handling and privacy protection. Both Kafka and Pulsar provide comprehensive security features including TLS encryption, SASL authentication, and fine-grained authorization controls that meet the requirements of enterprise ML applications.
Kafka’s security model provides robust protection mechanisms with extensive configuration options for implementing defense-in-depth strategies. The platform’s integration with enterprise identity management systems and support for multiple authentication protocols enables seamless integration with existing security infrastructure and compliance frameworks.
Pulsar’s multi-tenant architecture provides natural isolation boundaries that simplify security implementation and compliance verification for organizations serving multiple clients or business units through shared streaming infrastructure. The platform’s namespace-based isolation and fine-grained access controls enable secure resource sharing while maintaining strict data segregation requirements.
Real-World ML Use Cases and Success Stories
The practical application of streaming platforms in production ML environments provides valuable insights into the strengths and limitations of each platform across different use case scenarios. Kafka has demonstrated exceptional performance in high-frequency trading systems, real-time fraud detection, and large-scale recommendation engines where maximum throughput and minimal latency are paramount concerns.
Organizations such as Netflix, Uber, and LinkedIn have built their core ML infrastructure on Kafka, processing billions of events daily to power recommendation algorithms, demand forecasting, and user behavior analysis. These implementations showcase Kafka’s ability to handle massive scale while maintaining the reliability and performance requirements of business-critical ML applications.
Pulsar has gained traction in cloud-native organizations and companies requiring sophisticated multi-tenancy capabilities. Companies like Splunk, Tencent, and Yahoo have leveraged Pulsar’s architectural advantages to build scalable ML platforms that serve diverse user bases while maintaining operational efficiency and cost effectiveness.
Performance Benchmarking and Comparative Analysis
Objective performance comparison between Kafka and Pulsar requires careful consideration of workload characteristics, deployment configurations, and measurement methodologies that accurately reflect real-world ML application requirements. Independent benchmarking studies have shown that Kafka generally achieves higher peak throughput in scenarios involving large batch sizes and high-volume steady-state workloads.
Pulsar demonstrates competitive performance while providing better resource utilization efficiency and more predictable performance characteristics across varying workload patterns. The platform’s automatic load balancing and dynamic scaling capabilities result in more consistent performance during traffic spikes and resource constraints that commonly occur in production ML environments.
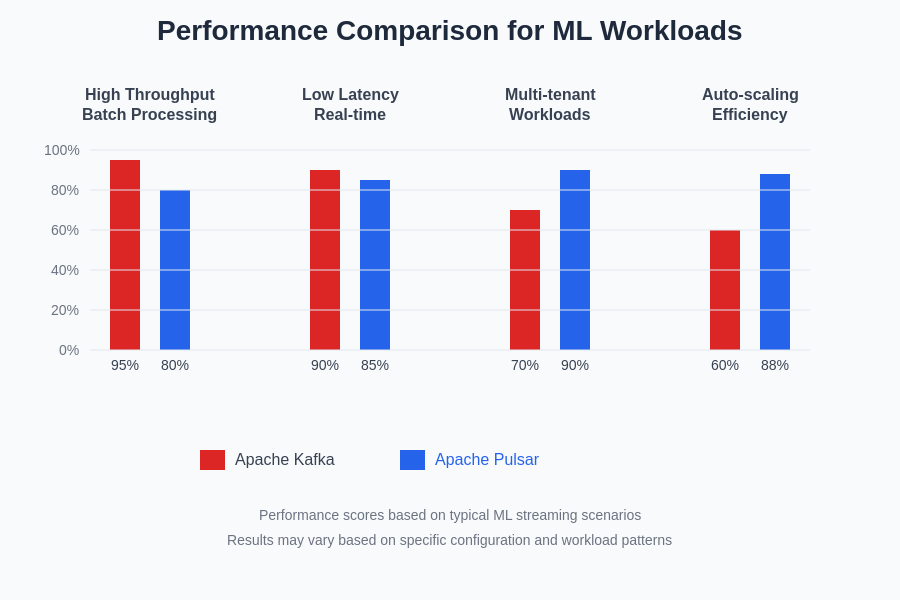
The performance characteristics of each platform vary significantly based on message size, batch configuration, replication settings, and consumer patterns, making it essential for ML teams to conduct platform-specific benchmarking using workloads that accurately represent their production requirements.
Future Evolution and Technology Roadmap
The streaming platform landscape continues to evolve rapidly, with both Kafka and Pulsar incorporating new features and capabilities that address emerging requirements in ML and data processing. Kafka’s roadmap emphasizes improving operational simplicity, enhancing exactly-once semantics, and providing better integration with cloud-native deployment patterns while maintaining its performance advantages.
The introduction of Kafka Raft (KRaft) mode eliminates the dependency on Apache ZooKeeper, simplifying deployment and management while improving scalability characteristics. These improvements address some of the operational challenges that have historically made Kafka more complex to manage compared to newer platforms.
Pulsar’s development focuses on expanding ecosystem integration, improving performance characteristics, and enhancing its cloud-native capabilities. The platform’s Functions feature continues to evolve toward a complete serverless computing platform for stream processing, potentially reducing the need for external processing frameworks in certain ML applications.
Making the Right Choice for Your ML Applications
The selection between Kafka and Pulsar for ML applications depends on a complex interplay of technical requirements, organizational capabilities, operational preferences, and long-term strategic considerations. Organizations with established Kafka expertise, high-throughput requirements, and complex stream processing needs may find Kafka’s mature ecosystem and proven scalability compelling advantages that justify its operational complexity.
Teams prioritizing operational simplicity, cloud-native deployment patterns, and multi-tenant capabilities may discover that Pulsar’s architectural advantages and automated management features provide better alignment with their operational model and resource constraints. The decision ultimately requires careful evaluation of specific use case requirements, performance characteristics, and organizational capabilities that influence long-term success.
The most successful ML streaming implementations often involve thorough proof-of-concept testing with realistic workloads, comprehensive operational planning, and clear understanding of the trade-offs inherent in each platform choice. Both Kafka and Pulsar represent powerful solutions capable of supporting sophisticated ML applications when properly implemented and managed according to their respective strengths and operational requirements.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on current understanding of streaming technologies and their applications in machine learning environments. Readers should conduct thorough evaluation and testing based on their specific requirements before making platform selection decisions. Performance characteristics and feature availability may vary depending on version, configuration, and deployment environment. Organizations should consult with qualified technical professionals and conduct comprehensive proof-of-concept testing before implementing production systems.