
The realm of audio technology has witnessed a revolutionary transformation with the advent of real-time voice conversion systems that leverage artificial intelligence to manipulate, modify, and synthesize human speech with unprecedented accuracy and speed. This groundbreaking technology has evolved from simple pitch modification tools to sophisticated neural networks capable of converting one person’s voice into another’s while preserving the natural cadence, emotion, and linguistic nuances that make human speech uniquely expressive and authentic.
Real-time voice conversion represents one of the most technically challenging and ethically complex applications of artificial intelligence in the audio domain. The technology combines advanced signal processing techniques with deep learning algorithms to analyze the fundamental characteristics of human speech, extract essential vocal features, and reconstruct audio output that maintains the semantic content while transforming the acoustic properties to match a target voice profile.
Discover the latest AI audio innovations and trends that are shaping the future of voice technology and transforming how we interact with digital audio content. The convergence of machine learning, signal processing, and computational linguistics has created unprecedented opportunities for voice manipulation that were previously confined to the realm of science fiction.
The Technical Foundation of Voice Conversion
The underlying architecture of modern voice conversion systems relies on sophisticated neural network models that have been trained on vast datasets of human speech to understand the complex relationships between acoustic features and perceptual qualities of voice. These systems typically employ encoder-decoder architectures that first decompose incoming audio into fundamental components such as pitch, timbre, formant frequencies, and spectral characteristics, then reconstruct these elements according to the parameters of a target voice model.
The real-time aspect of these systems presents significant computational challenges that require optimized algorithms capable of processing audio streams with minimal latency while maintaining high fidelity output. Modern implementations utilize techniques such as streaming neural networks, parallel processing architectures, and specialized hardware acceleration to achieve the sub-100 millisecond latency requirements necessary for interactive applications such as live streaming, gaming, and real-time communication platforms.
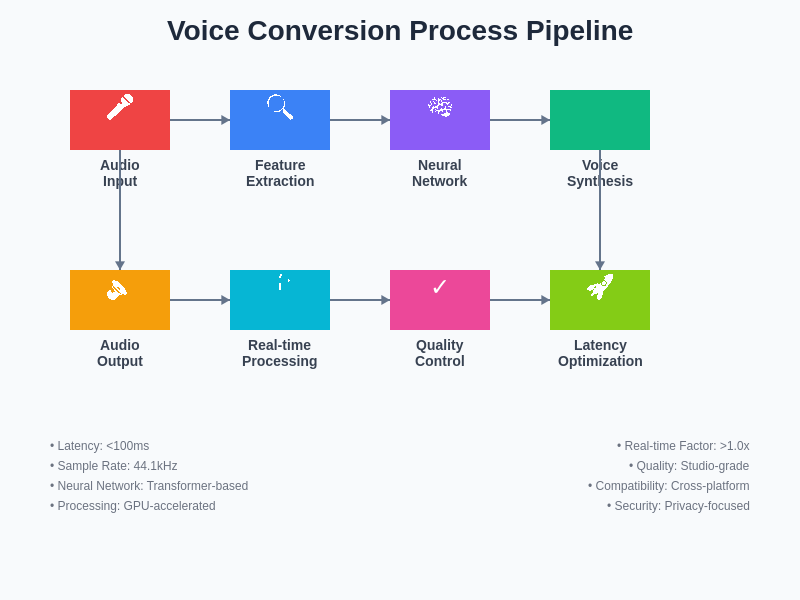
The technical pipeline for real-time voice conversion encompasses multiple sophisticated processing stages that work in concert to transform input audio while maintaining natural speech characteristics and minimizing processing delays. Each component in this pipeline has been optimized for both quality and performance to meet the demanding requirements of real-time applications.
The sophistication of contemporary voice conversion technology extends beyond simple parameter manipulation to encompass complex modeling of human vocal tract characteristics, breathing patterns, and even subtle emotional inflections that contribute to the perceived authenticity of synthesized speech. These advances have been made possible through the development of more sophisticated training methodologies, larger and more diverse datasets, and improved neural network architectures specifically designed for audio processing tasks.
Deep Learning Architectures in Voice Conversion
The evolution of voice conversion technology has been closely tied to advances in deep learning architectures specifically adapted for audio processing tasks. Convolutional neural networks have proven particularly effective at capturing the spectral patterns and temporal dependencies inherent in human speech, while recurrent neural networks excel at modeling the sequential nature of audio signals and maintaining temporal consistency across longer utterances.
More recent developments have incorporated attention mechanisms and transformer architectures that allow voice conversion systems to focus selectively on relevant acoustic features while maintaining global context awareness throughout the conversion process. These architectural improvements have resulted in more natural-sounding output that preserves the emotional content and speaking style of the original speaker while successfully transforming the vocal characteristics to match the target voice profile.
Experience advanced AI capabilities with Claude for developing and understanding complex voice processing algorithms that power next-generation audio applications. The integration of multiple neural network architectures within a single voice conversion system has enabled more robust and versatile performance across diverse acoustic conditions and speaker characteristics.
Real-Time Processing Challenges and Solutions
Achieving real-time performance in voice conversion systems requires careful optimization of both algorithmic complexity and computational efficiency. Traditional approaches often involved computationally intensive spectral analysis and synthesis techniques that were incompatible with real-time constraints, necessitating the development of streamlined processing pipelines specifically designed for low-latency applications.
Modern real-time voice conversion systems employ various optimization strategies including model quantization, pruning techniques, and specialized inference engines that reduce computational overhead while maintaining conversion quality. Additionally, the implementation of streaming processing algorithms allows these systems to begin generating output before complete input utterances are received, further reducing perceived latency and enabling more natural interactive experiences.
The challenge of maintaining conversion quality while meeting real-time constraints has driven innovation in model architecture design, leading to the development of lightweight neural networks that achieve comparable performance to their computationally intensive counterparts. These optimizations have made real-time voice conversion accessible on consumer-grade hardware, democratizing access to sophisticated voice manipulation technology.
Applications in Gaming and Entertainment
The gaming industry has emerged as one of the primary drivers of real-time voice conversion technology adoption, with applications ranging from character voice modification in role-playing games to privacy protection in online multiplayer environments. Players can now assume different vocal identities while maintaining natural communication with other participants, enhancing immersion and enabling new forms of creative expression within virtual worlds.
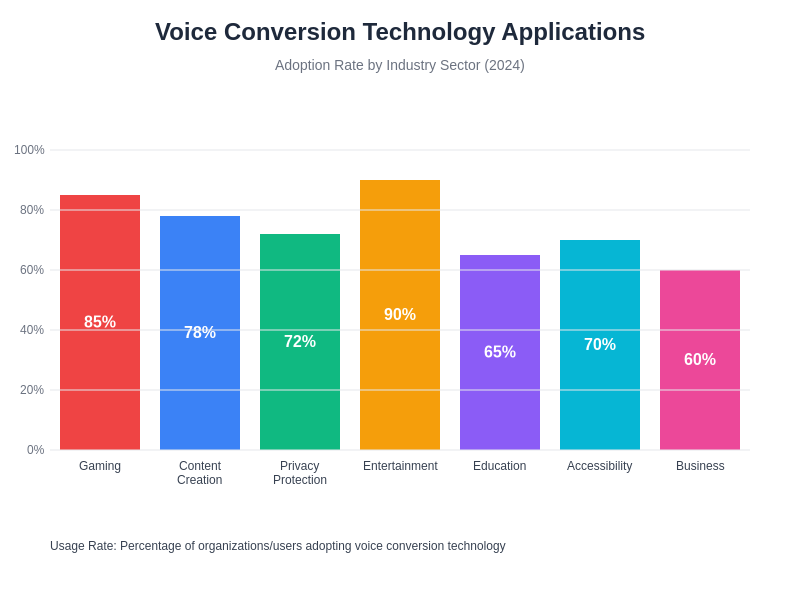
The adoption rates across different industry sectors demonstrate the broad appeal and utility of voice conversion technology, with gaming and entertainment leading the way while emerging applications in education, accessibility, and business communications continue to expand the market reach of these sophisticated audio processing systems.
Streaming platforms and content creation tools have integrated voice conversion capabilities to provide creators with enhanced storytelling possibilities and character development options. Content creators can embody multiple characters within a single production, create unique vocal personas for different content types, or protect their personal identity while maintaining engaging audience interactions.
The entertainment industry’s adoption of real-time voice conversion extends to live performance applications where actors and performers can modify their vocal characteristics during live productions, creating dynamic character transformations that were previously impossible without post-production editing. This technology has opened new creative possibilities for theater, live streaming, and interactive entertainment experiences.
Privacy and Security Implications
Real-time voice conversion technology presents significant implications for personal privacy and digital security that extend far beyond its entertainment applications. The ability to convincingly modify one’s voice in real-time provides powerful privacy protection capabilities for individuals who wish to participate in online communications while protecting their identity, particularly relevant for whistleblowers, activists, or individuals in sensitive professional situations.
However, the same technology that enables privacy protection also creates potential security vulnerabilities through voice spoofing attacks that could circumvent voice-based authentication systems. Financial institutions, security services, and other organizations that rely on voice biometrics for identity verification must adapt their security protocols to account for the possibility of sophisticated voice conversion attacks.
The development of detection systems capable of identifying artificially generated or converted speech has become an active area of research as organizations seek to maintain security while accommodating legitimate uses of voice conversion technology. These detection systems employ similar machine learning techniques to identify subtle artifacts and inconsistencies that distinguish converted speech from natural human voice patterns.
Enhance your research capabilities with Perplexity to stay informed about the latest developments in voice security and privacy protection technologies. The ongoing arms race between voice conversion capabilities and detection systems continues to drive innovation in both offensive and defensive audio processing technologies.
Commercial Voice Conversion Platforms
The commercialization of voice conversion technology has resulted in a diverse ecosystem of platforms and services catering to different user needs and technical requirements. Consumer-focused applications typically prioritize ease of use and real-time performance, offering simplified interfaces that allow users to apply voice effects and character transformations without requiring technical expertise in audio processing or machine learning.
Professional-grade voice conversion systems provide more sophisticated control over conversion parameters, support for custom voice model training, and integration capabilities with existing audio production workflows. These platforms often include features such as batch processing, API access, and advanced quality control options that meet the demanding requirements of content production, dubbing, and professional audio post-production environments.
Cloud-based voice conversion services have emerged as popular solutions for developers and content creators who require sophisticated voice conversion capabilities without the complexity of managing local infrastructure. These services typically offer scalable processing power, regularly updated models, and comprehensive developer APIs that enable integration with existing applications and workflows.
Technical Implementation Considerations
Implementing real-time voice conversion systems requires careful consideration of multiple technical factors including audio quality requirements, latency constraints, computational resources, and integration requirements with existing audio processing pipelines. The choice of neural network architecture, training methodology, and optimization techniques significantly impacts both the quality and performance characteristics of the resulting system.
Audio preprocessing and feature extraction stages play crucial roles in conversion quality, requiring sophisticated algorithms for noise reduction, normalization, and spectral analysis that preserve essential voice characteristics while removing unwanted artifacts. The design of these preprocessing pipelines must balance thorough audio cleaning with minimal processing delay to maintain real-time performance requirements.
Post-processing techniques such as anti-aliasing, dynamic range compression, and psychoacoustic optimization ensure that converted audio meets professional quality standards while remaining compatible with various playback systems and transmission protocols. These considerations become particularly important in applications where converted speech must integrate seamlessly with other audio elements or meet specific broadcast quality requirements.
Training Data and Model Development
The quality and diversity of training data fundamentally determine the capabilities and limitations of voice conversion systems. Comprehensive training datasets must include diverse speaker demographics, various acoustic conditions, emotional expressions, and linguistic variations to ensure robust performance across real-world usage scenarios. The collection and curation of such datasets present significant logistical and ethical challenges that must be carefully managed.
Data preprocessing and augmentation techniques play essential roles in maximizing the effectiveness of available training data while ensuring model generalization across different speakers and acoustic environments. Advanced augmentation strategies can artificially expand training datasets through controlled modifications that preserve essential voice characteristics while introducing beneficial variation that improves model robustness.
The development of evaluation metrics and benchmarking methodologies specific to voice conversion tasks has become increasingly important as the field matures and commercial applications demand reliable quality assessment. These evaluation frameworks must capture both objective acoustic measures and subjective perceptual qualities that determine the practical effectiveness of voice conversion systems in real-world applications.
Emerging Trends and Future Developments
The trajectory of voice conversion technology development indicates several emerging trends that will significantly impact future capabilities and applications. Multi-speaker voice conversion systems that can simultaneously handle multiple input voices and apply different target transformations represent a natural evolution toward more sophisticated audio processing scenarios such as conference call modification and multi-character content creation.
Integration with other AI technologies such as natural language processing and emotion recognition systems promises to enable more sophisticated voice conversion capabilities that can modify not only vocal characteristics but also speaking style, emotional expression, and linguistic patterns. These integrated systems could provide unprecedented control over the communicative aspects of synthesized speech.
The development of few-shot and zero-shot voice conversion techniques aims to reduce the training data requirements for creating new target voice models, potentially enabling personalized voice conversion with minimal user input. These advances could democratize access to custom voice conversion capabilities while reducing the computational resources required for model training and deployment.
Ethical Considerations and Responsible Development
The powerful capabilities of real-time voice conversion technology raise important ethical questions regarding consent, authenticity, and potential misuse that require careful consideration by developers, users, and regulatory bodies. The ability to convincingly replicate or modify human voices creates opportunities for both beneficial applications and harmful exploitation that must be balanced through thoughtful design choices and appropriate safeguards.
Responsible development practices include implementing robust user authentication, maintaining audit trails for voice conversion activities, and providing clear disclosure mechanisms that identify artificially modified audio content. These technical safeguards must be complemented by clear usage policies, user education initiatives, and industry standards that promote ethical application of voice conversion technology.
The development of technical standards and best practices for voice conversion systems represents an ongoing collaborative effort involving technologists, ethicists, legal experts, and industry stakeholders. These standards aim to maximize the beneficial applications of voice conversion technology while minimizing potential harms through technical design choices and operational guidelines.
Performance Optimization and Hardware Requirements
Optimizing voice conversion systems for real-time performance requires sophisticated understanding of both algorithmic efficiency and hardware utilization patterns. Modern implementations leverage specialized processing units such as graphics processing units and tensor processing units that provide substantial acceleration for the matrix operations underlying neural network inference while maintaining power efficiency requirements for mobile and embedded applications.
The implementation of dynamic quality adjustment mechanisms allows voice conversion systems to adapt their computational complexity based on available processing resources and quality requirements, ensuring consistent performance across diverse hardware platforms. These adaptive systems can automatically adjust model complexity, processing resolution, and output quality to maintain real-time performance while maximizing conversion quality within available computational constraints.
Edge computing implementations of voice conversion technology enable local processing that reduces network dependency, improves privacy protection, and minimizes latency for real-time applications. These implementations require careful optimization of model size, memory usage, and computational efficiency to operate effectively on resource-constrained edge devices while maintaining acceptable conversion quality.
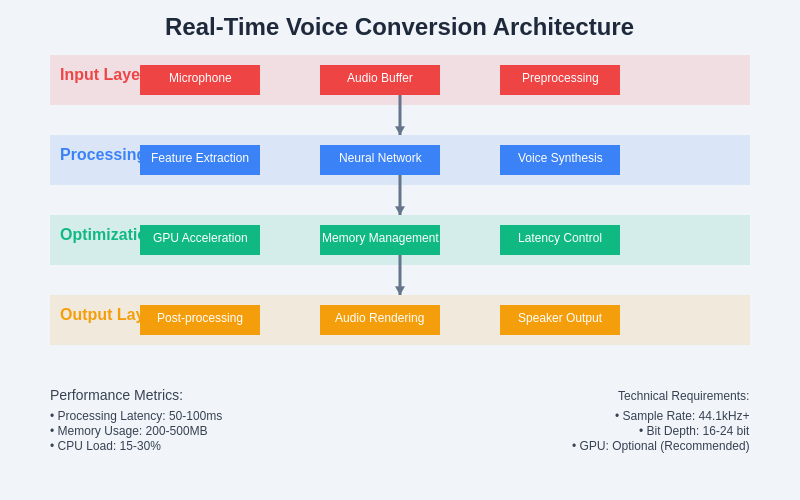
The layered architecture of real-time voice conversion systems demonstrates the sophisticated engineering required to achieve high-quality audio transformation within strict latency constraints. Each layer serves specific functions while contributing to the overall system performance through optimized data flow and processing efficiency.
Integration with Communication Platforms
The integration of real-time voice conversion capabilities with existing communication platforms presents both technical challenges and significant opportunities for enhancing user experiences. Modern video conferencing systems, messaging applications, and social media platforms increasingly incorporate voice modification features that enable users to protect privacy, enhance creative expression, or simply add entertainment value to their communications.
API development and standardization efforts aim to simplify the integration of voice conversion capabilities with third-party applications while providing developers with flexible control over conversion parameters and quality settings. These standardized interfaces enable rapid deployment of voice conversion features across diverse application ecosystems without requiring specialized expertise in audio processing or machine learning.
Cross-platform compatibility considerations ensure that voice conversion systems can operate effectively across different operating systems, hardware configurations, and network conditions while maintaining consistent user experiences and conversion quality. These compatibility requirements drive the development of platform-agnostic implementations and standardized audio processing protocols.
The future landscape of real-time voice conversion technology promises continued advancement in quality, efficiency, and accessibility while addressing the important ethical and security considerations that accompany such powerful capabilities. As these systems become more sophisticated and widely deployed, their impact on communication, entertainment, and creative expression will continue to expand, fundamentally altering how we interact with and manipulate audio content in digital environments.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on current understanding of voice conversion technologies and their applications. Readers should conduct their own research and consider ethical implications when implementing or using voice conversion tools. The effectiveness and appropriateness of voice conversion technology may vary depending on specific use cases, legal requirements, and ethical considerations in different jurisdictions.