
The foundation of credible artificial intelligence research rests upon the principle of reproducibility, a cornerstone that ensures scientific validity and enables the broader research community to build upon previous discoveries. In an era where machine learning models increasingly influence critical decisions across industries, the ability to replicate experimental results has become not merely an academic ideal but an essential requirement for trustworthy AI systems. The complexity inherent in modern AI research, with its intricate datasets, sophisticated algorithms, and computational dependencies, presents unique challenges that demand systematic approaches to experimental design and documentation.
Explore the latest trends in AI research methodologies to understand how the scientific community is addressing reproducibility challenges in machine learning and artificial intelligence research. The pursuit of reproducible AI research transcends individual studies and contributes to the collective advancement of the field by establishing reliable baselines, facilitating peer review processes, and enabling the systematic evaluation of novel approaches against established benchmarks.
The Reproducibility Crisis in AI Research
The artificial intelligence research community has grappled with a growing reproducibility crisis that threatens the scientific integrity of the field. Studies have revealed alarming rates of non-reproducible results, with researchers frequently unable to replicate findings from published papers despite access to similar computational resources and datasets. This crisis stems from multiple interconnected factors, including insufficient documentation of experimental procedures, lack of standardized evaluation protocols, and the inherent stochasticity present in many machine learning algorithms.
The consequences of poor reproducibility extend far beyond academic discourse, affecting the practical deployment of AI systems in real-world applications where reliability and consistency are paramount. Organizations investing in AI technologies require confidence that research findings can be translated into operational systems with predictable performance characteristics. The reproducibility crisis has thus catalyzed efforts to establish comprehensive frameworks and best practices that address the unique challenges inherent in AI research methodologies.
Fundamental Principles of Reproducible ML Experiments
Establishing reproducible machine learning experiments requires adherence to fundamental principles that span the entire research lifecycle from initial data collection through final results publication. The principle of complete documentation mandates that every aspect of the experimental process be thoroughly recorded, including data preprocessing steps, model architectures, hyperparameter configurations, and computational environments. This comprehensive documentation serves as a blueprint that enables other researchers to reconstruct identical experimental conditions and validate reported findings.
Version control represents another critical principle that extends beyond traditional software development practices to encompass datasets, model weights, and experimental configurations. The dynamic nature of machine learning research, where iterative improvements and ablation studies are commonplace, necessitates sophisticated versioning strategies that maintain clear lineage tracking between different experimental iterations. Additionally, the principle of environment isolation ensures that computational dependencies and system configurations are precisely specified and reproducible across different computing platforms and time periods.
Discover advanced AI research tools with Claude to enhance your experimental workflows with sophisticated analysis capabilities and comprehensive documentation support. The integration of AI assistants into research processes can significantly improve the consistency and thoroughness of experimental documentation while reducing the likelihood of oversight in critical procedural details.
Data Management and Versioning Strategies
Effective data management forms the bedrock of reproducible AI research, requiring systematic approaches to data collection, preprocessing, and version control that ensure experimental consistency across time and research teams. The establishment of immutable datasets with cryptographic hashes provides a foundation for verifying data integrity and detecting unauthorized modifications that could compromise experimental validity. Comprehensive metadata documentation accompanies each dataset version, capturing essential information about data sources, collection methodologies, preprocessing transformations, and quality assessment procedures.
Data lineage tracking becomes particularly crucial in machine learning projects where datasets undergo multiple transformation stages, from raw data ingestion through feature engineering and augmentation processes. Modern data management platforms provide sophisticated capabilities for maintaining complete audit trails of data transformations, enabling researchers to trace any specific data point back to its original source and understand the complete processing pipeline that produced the final experimental dataset.
The implementation of data validation frameworks ensures that dataset integrity is maintained throughout the research process, with automated checks that verify data consistency, detect anomalies, and flag potential quality issues that could affect experimental outcomes. These validation frameworks incorporate statistical tests, schema validation, and distribution monitoring to provide comprehensive quality assurance for research datasets.
Code Organization and Documentation Standards
The organization and documentation of research code represents a critical component of reproducible AI experiments, requiring structured approaches that balance flexibility for iterative development with the rigor necessary for scientific validation. Modern software engineering practices, including modular design principles, comprehensive testing frameworks, and continuous integration workflows, provide essential foundations for maintaining code quality and reproducibility in research environments.
Effective code organization follows hierarchical structures that separate data processing, model implementation, experimental configuration, and evaluation components into distinct modules with clearly defined interfaces. This modular approach enables independent testing and validation of individual components while facilitating code reuse across different experimental configurations. Documentation standards encompass both inline code comments that explain implementation details and comprehensive README files that provide high-level overviews of experimental procedures and usage instructions.
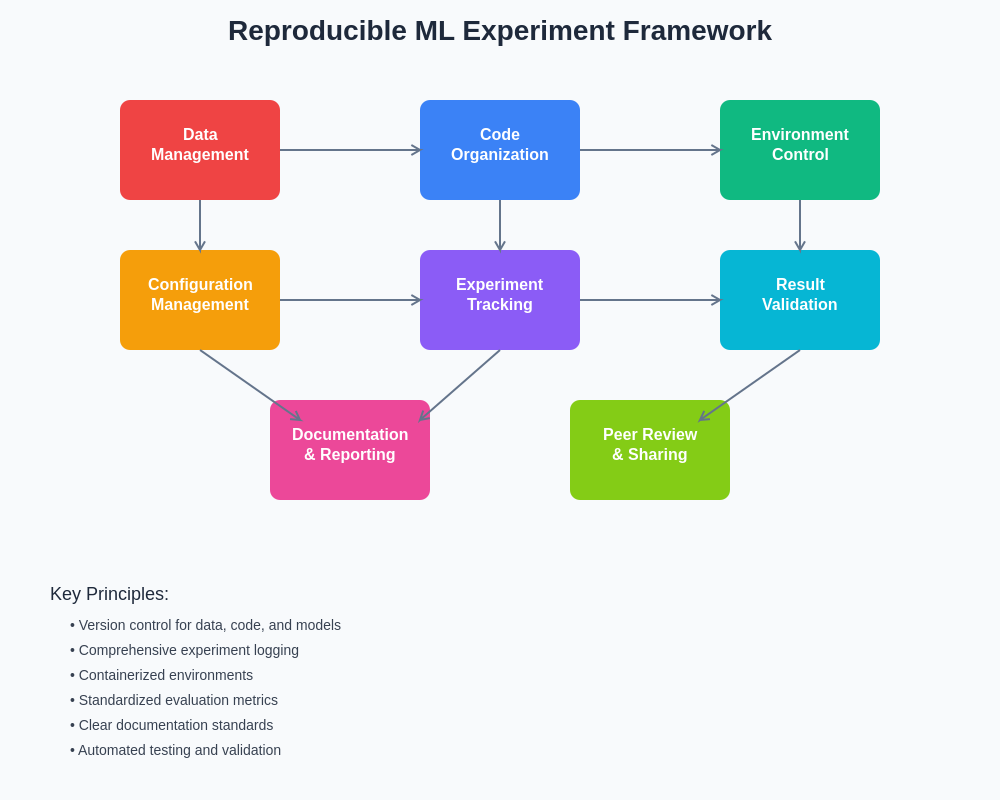
The systematic organization of machine learning experiments requires careful consideration of code structure, data management, configuration handling, and result tracking to ensure that every aspect of the research process can be precisely replicated and validated by independent researchers.
Environment Management and Containerization
The computational environment in which machine learning experiments are conducted significantly impacts the reproducibility of results, necessitating sophisticated approaches to dependency management and system configuration standardization. Containerization technologies provide powerful solutions for encapsulating complete experimental environments, including operating system configurations, software dependencies, and runtime parameters, into portable units that can be executed consistently across different computing platforms.
Docker containers have emerged as the de facto standard for environment isolation in AI research, enabling researchers to package their complete experimental stack into self-contained units that eliminate the variability introduced by different system configurations. These containerized environments include precise versions of machine learning frameworks, mathematical libraries, and system-level dependencies, ensuring that computational results remain consistent regardless of the underlying hardware or host operating system.
Environment specification files, such as Conda environment configurations or Python requirements.txt files, provide human-readable documentation of software dependencies while enabling automated environment reconstruction. These specifications must include exact version numbers for all dependencies, including transitive dependencies that might not be explicitly imported by research code but could influence computational behavior through underlying library interactions.
Experiment Configuration and Parameter Management
Systematic management of experimental configurations and hyperparameters represents a cornerstone of reproducible AI research, requiring structured approaches that ensure complete parameter specification and facilitate systematic exploration of the experimental space. Configuration management systems separate experimental parameters from implementation code, enabling researchers to maintain clear records of all parameter settings used in different experimental runs while facilitating systematic hyperparameter optimization studies.
Hierarchical configuration systems accommodate the complexity of modern machine learning experiments, where parameters may be specified at multiple levels including dataset preprocessing, model architecture, training procedures, and evaluation protocols. These systems support parameter inheritance and override mechanisms that enable efficient exploration of parameter variations while maintaining complete documentation of all experimental configurations.
Parameter validation frameworks provide automated verification that experimental configurations conform to expected schemas and constraints, reducing the likelihood of experimental errors caused by invalid parameter combinations or typographical errors in configuration files. These validation systems incorporate domain-specific knowledge about parameter relationships and constraints, providing intelligent error messages that guide researchers toward valid experimental configurations.
Enhance your research workflow with Perplexity for comprehensive literature review and parameter optimization research that can inform your experimental design decisions. The integration of AI-powered research assistants into parameter management workflows can significantly improve the thoroughness of hyperparameter exploration and the identification of optimal experimental configurations.
Randomness Control and Seed Management
The stochastic nature of many machine learning algorithms presents unique challenges for reproducibility, requiring systematic approaches to randomness control that balance the benefits of stochastic exploration with the need for deterministic experimental outcomes. Comprehensive seed management strategies ensure that all sources of randomness within experimental procedures are controlled and documented, enabling precise replication of experimental results across different computational environments and time periods.
Modern machine learning frameworks incorporate multiple sources of randomness, including data shuffling operations, parameter initialization procedures, dropout mechanisms, and stochastic optimization algorithms. Effective randomness control requires identification and management of all these sources, with explicit seed setting for each random number generator used throughout the experimental pipeline. Hierarchical seed management systems provide structured approaches to seed allocation that ensure independence between different random processes while maintaining overall experimental determinism.
The implementation of reproducible randomness extends beyond simple seed setting to encompass more sophisticated considerations such as parallel processing environments where multiple threads or processes may access shared random number generators. Advanced randomness control frameworks provide thread-safe random number generation and deterministic scheduling mechanisms that ensure consistent behavior across different parallel execution configurations.
Model Checkpointing and Version Control
Systematic model checkpointing and version control practices ensure that the complete state of machine learning models can be preserved and reconstructed at any point during the experimental process. Modern checkpointing strategies extend beyond simple model weight preservation to encompass optimizer states, learning rate schedules, and training metadata that collectively define the complete model state. This comprehensive state preservation enables researchers to resume training from arbitrary points, investigate model behavior at different stages of development, and compare performance across different training configurations.
Version control for machine learning models requires specialized tools that can efficiently handle the large binary files typically associated with trained models while providing meaningful tracking of model evolution throughout the development process. Git-based solutions with large file support provide familiar version control interfaces while accommodating the unique requirements of machine learning artifacts. Alternative specialized platforms offer enhanced capabilities specifically designed for machine learning model management, including automatic metadata extraction, performance tracking, and visualization capabilities.
Model registry systems provide centralized repositories for trained models with comprehensive metadata tracking, enabling teams to maintain organized collections of experimental results while facilitating model comparison and selection processes. These registries incorporate automated quality metrics, performance benchmarking, and documentation requirements that ensure consistent standards across different experimental iterations.
Evaluation Metrics and Benchmark Standardization
The standardization of evaluation metrics and benchmark datasets represents a critical component of reproducible AI research that enables meaningful comparison of results across different studies and research groups. Comprehensive evaluation frameworks incorporate multiple complementary metrics that capture different aspects of model performance, providing robust assessments that are less susceptible to metric-specific biases or optimization artifacts. These frameworks must account for the inherent trade-offs between different performance dimensions while providing clear guidance on metric selection and interpretation.
Benchmark dataset standardization requires careful consideration of data splits, evaluation protocols, and performance reporting standards that ensure fair and meaningful comparisons across different approaches. Standardized benchmark suites provide reference implementations of evaluation procedures, including data preprocessing steps, metric calculations, and statistical significance testing protocols that eliminate potential sources of variation in experimental results.
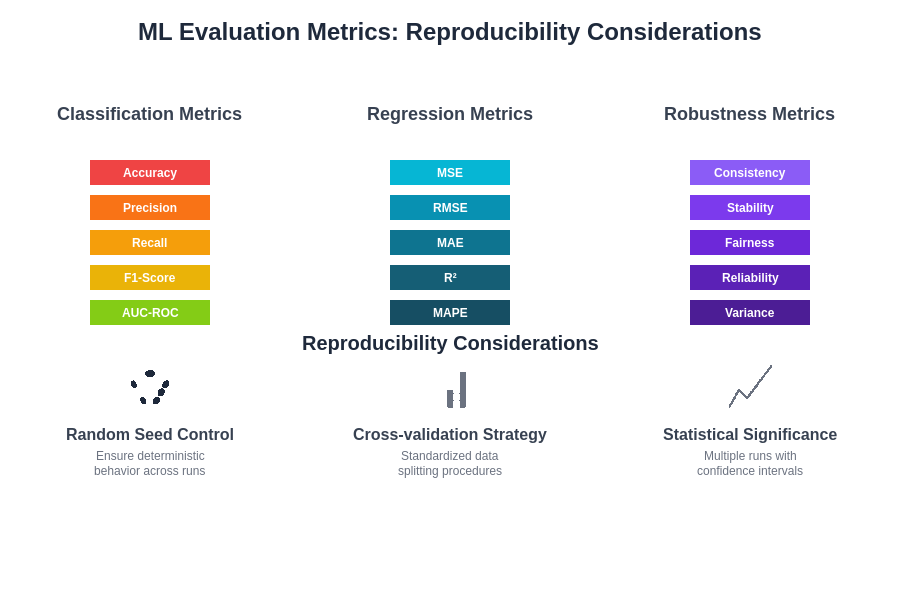
The selection and application of appropriate evaluation metrics requires careful consideration of task characteristics, dataset properties, and practical deployment requirements to ensure that experimental results provide meaningful insights into real-world model performance.
Collaborative Research Workflows
Modern AI research increasingly involves collaborative efforts across distributed teams, necessitating sophisticated workflows that maintain reproducibility standards while accommodating diverse working styles and computational environments. Collaborative reproducibility frameworks establish shared standards for code organization, documentation practices, and experimental procedures that enable seamless integration of contributions from multiple researchers while maintaining scientific rigor.
Version control systems optimized for machine learning research provide specialized capabilities for handling the unique artifacts generated during AI experiments, including large datasets, trained models, and experimental results. These systems incorporate conflict resolution mechanisms tailored to machine learning workflows, automated testing procedures for experimental code, and comprehensive audit trails that track all modifications to experimental procedures and results.
Communication and documentation platforms facilitate knowledge sharing and collaborative problem-solving while maintaining complete records of research decisions and their rationales. These platforms integrate with experimental tracking systems to provide contextual documentation that links research discussions to specific experimental results, creating comprehensive research narratives that support reproducibility and knowledge transfer.
Computational Resource Documentation
The computational requirements and resource utilization patterns of machine learning experiments significantly impact both the reproducibility and accessibility of research results. Comprehensive documentation of computational resources includes detailed specifications of hardware configurations, including processor types, memory capacity, storage characteristics, and accelerator devices such as GPUs or specialized AI processors. This documentation enables other researchers to assess the feasibility of replicating experiments within their available computational budgets while providing important context for interpreting experimental results.
Resource monitoring and profiling tools provide automated collection of computational metrics during experimental execution, creating detailed records of resource utilization patterns that can inform both reproducibility efforts and optimization strategies. These tools track metrics such as processing time, memory consumption, storage requirements, and energy usage, providing comprehensive characterization of experimental computational demands.
Cloud computing platforms offer standardized computational environments that can enhance reproducibility by providing consistent hardware configurations and software stacks across different research groups. Documentation of cloud-specific configurations, including instance types, storage configurations, and networking settings, ensures that cloud-based experiments can be precisely replicated by other researchers using similar platforms.
Quality Assurance and Testing Frameworks
Rigorous quality assurance practices ensure that experimental code and procedures meet scientific standards for reliability and validity, reducing the likelihood of errors that could compromise research results or impede reproducibility efforts. Comprehensive testing frameworks for machine learning research encompass unit tests for individual code components, integration tests for complete experimental pipelines, and validation tests that verify experimental results against known benchmarks or theoretical expectations.
Automated testing procedures integrate with version control systems to provide continuous validation of experimental code throughout the development process, catching potential issues early in the development cycle before they can impact experimental results. These procedures include code quality checks, dependency validation, and experimental smoke tests that verify basic functionality across different computational environments.
Code review processes adapted for machine learning research provide systematic evaluation of experimental procedures by peers with relevant domain expertise, offering opportunities to identify potential issues and suggest improvements before experiments are executed. These review processes incorporate specialized checklists and evaluation criteria tailored to the unique challenges of AI research, including assessments of statistical validity, experimental design appropriateness, and reproducibility considerations.
Documentation and Reporting Standards
Comprehensive documentation represents the cornerstone of reproducible AI research, requiring systematic approaches to recording experimental procedures, results, and analysis that enable other researchers to understand, validate, and build upon published work. Modern documentation standards for machine learning research encompass multiple interconnected layers, including technical documentation of algorithms and implementations, methodological documentation of experimental procedures, and interpretive documentation that contextualizes results within broader research landscapes.
Structured reporting templates provide standardized frameworks for organizing and presenting research results, ensuring that critical information necessary for reproducibility is consistently included in research publications. These templates incorporate sections dedicated to computational requirements, data specifications, experimental procedures, and code availability, creating comprehensive research narratives that support both peer review processes and replication efforts.
Automated documentation generation tools extract information directly from experimental code and configuration files, reducing the likelihood of inconsistencies between documented procedures and actual implementations. These tools generate technical specifications, parameter summaries, and execution logs that provide detailed records of experimental procedures while minimizing the manual effort required to maintain comprehensive documentation.
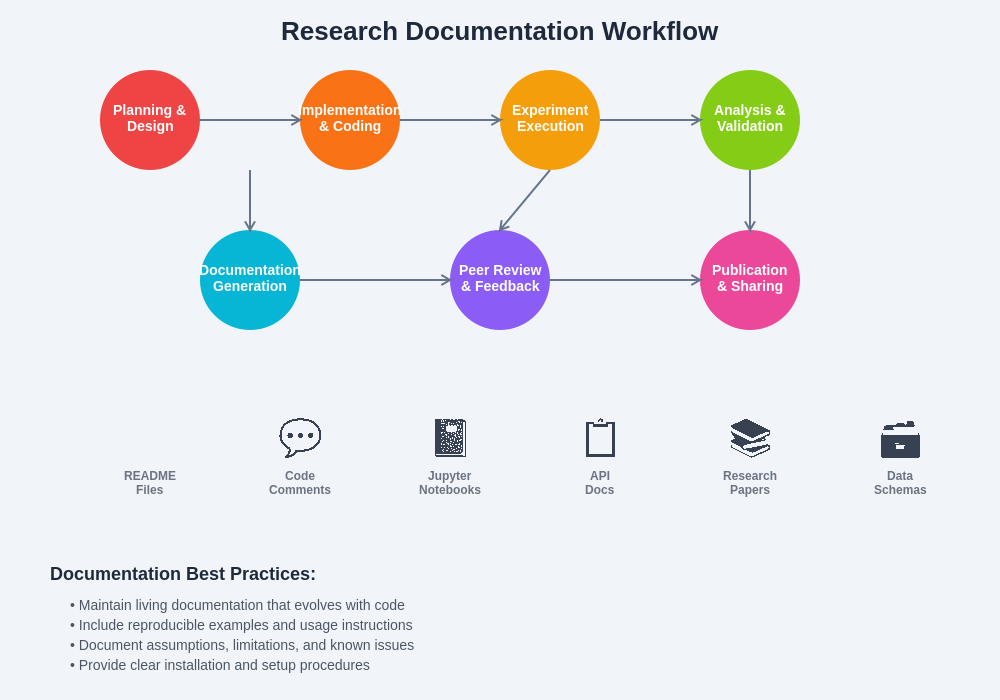
The systematic organization of research documentation requires careful consideration of audience needs, information hierarchy, and accessibility requirements to ensure that documentation serves both immediate research needs and long-term reproducibility objectives.
Future Directions and Emerging Technologies
The landscape of reproducible AI research continues to evolve rapidly as new technologies and methodologies emerge to address the unique challenges of machine learning reproducibility. Blockchain-based approaches to experimental verification offer potential solutions for creating immutable records of experimental procedures and results, providing cryptographic guarantees of data integrity and procedural authenticity that could enhance trust in published research results.
Automated experiment generation and optimization systems promise to reduce human error in experimental design while systematically exploring large experimental spaces with comprehensive documentation of all explored configurations. These systems incorporate machine learning techniques to optimize experimental procedures themselves, creating meta-level optimization frameworks that can identify optimal experimental strategies while maintaining complete reproducibility standards.
Federated learning and distributed research platforms present new challenges and opportunities for collaborative reproducible research across organizational boundaries, requiring novel approaches to maintaining experimental consistency and documentation standards in distributed computational environments. These platforms must balance the benefits of resource pooling and collaborative research with the stringent requirements of scientific reproducibility and intellectual property protection.
The integration of artificial intelligence techniques into reproducibility tooling itself represents a promising direction for enhancing the automation and reliability of reproducible research practices. AI-powered documentation assistants, automated experimental validation systems, and intelligent error detection mechanisms could significantly reduce the manual effort required to maintain high reproducibility standards while improving the overall quality and reliability of AI research.
Disclaimer
This article is for educational and informational purposes only and does not constitute professional research advice. The methodologies and practices described represent general guidelines that should be adapted to specific research contexts and requirements. Readers should consult relevant institutional policies, funding agency requirements, and journal guidelines when implementing reproducible research practices. The effectiveness of reproducibility approaches may vary depending on specific research domains, computational resources, and collaborative requirements. Always ensure compliance with data protection regulations and institutional review board requirements when conducting AI research involving human subjects or sensitive data.