
The convergence of big data technologies and machine learning has created an unprecedented demand for scalable, efficient, and maintainable data processing pipelines that can handle massive volumes of information while delivering actionable insights. At the heart of this technological revolution lies the powerful combination of Scala programming language and Apache Spark framework, which together provide an unparalleled platform for developing sophisticated machine learning pipelines that can process petabytes of data across distributed computing clusters with remarkable efficiency and reliability.
Discover the latest trends in AI and big data technologies to stay informed about cutting-edge developments that are reshaping the landscape of data science and machine learning. The synergy between Scala’s functional programming paradigms and Spark’s distributed computing capabilities has established itself as the gold standard for enterprise-scale machine learning implementations, offering data engineers and scientists the tools necessary to build robust, scalable, and maintainable data processing solutions.
The Foundation of Modern Big Data Processing
Scala’s functional programming approach naturally aligns with the distributed computing model that Apache Spark employs, creating a harmonious development environment where immutable data structures, higher-order functions, and lazy evaluation combine to produce highly efficient and fault-tolerant data processing pipelines. This foundational synergy enables developers to write concise, expressive code that translates directly into optimized execution plans across distributed computing clusters, maximizing both performance and resource utilization while minimizing the complexity traditionally associated with big data processing.
The architectural elegance of Scala-based Spark applications stems from the language’s ability to seamlessly integrate object-oriented and functional programming concepts, allowing developers to create modular, reusable components that can be easily composed into complex data processing workflows. This compositional approach to pipeline development not only enhances code maintainability but also facilitates the creation of sophisticated machine learning algorithms that can adapt to changing data patterns and business requirements without requiring complete architectural overhauls.
Understanding Spark’s Machine Learning Ecosystem
Apache Spark’s MLlib library represents one of the most comprehensive and mature machine learning frameworks available for distributed computing environments, offering a rich collection of algorithms, utilities, and abstractions specifically designed for large-scale data analysis and model training. The library’s architecture embraces the concept of machine learning pipelines as first-class citizens, providing developers with powerful abstractions for chaining together data preprocessing, feature engineering, model training, and evaluation steps into cohesive, reproducible workflows that can be executed across massive datasets with consistent performance and reliability.
The pipeline-centric approach adopted by MLlib fundamentally transforms how machine learning workflows are conceptualized and implemented, moving away from the traditional imperative style of data processing toward a more declarative model where complex operations are expressed as transformations and actions that can be optimized, cached, and distributed automatically by the Spark engine. This paradigm shift not only improves performance but also enhances the reproducibility and maintainability of machine learning workflows, enabling data scientists to focus on algorithm design and feature engineering rather than the intricacies of distributed computing.
Experience advanced AI capabilities with Claude for comprehensive assistance in developing and optimizing your machine learning pipelines and distributed computing solutions. The integration of modern AI tools with traditional big data processing frameworks creates powerful synergies that accelerate development cycles and improve the quality of analytical solutions.
Designing Scalable Data Ingestion Architectures
The foundation of any successful machine learning pipeline lies in its ability to efficiently ingest, validate, and preprocess massive volumes of data from diverse sources while maintaining data quality and consistency standards. Scala’s strong type system combined with Spark’s flexible data source APIs enables the creation of robust data ingestion frameworks that can handle structured, semi-structured, and unstructured data formats with equal efficiency, providing built-in error handling, schema validation, and data quality assessment capabilities that are essential for production-grade machine learning systems.
The design of scalable data ingestion architectures requires careful consideration of factors such as data velocity, variety, and volume, along with specific requirements for data freshness, consistency, and availability. Spark’s unified batch and streaming processing model, implemented through the Structured Streaming API, enables the development of lambda and kappa architectures that can seamlessly handle both historical batch processing and real-time stream processing scenarios within a single, coherent framework that reduces operational complexity while maximizing processing flexibility.
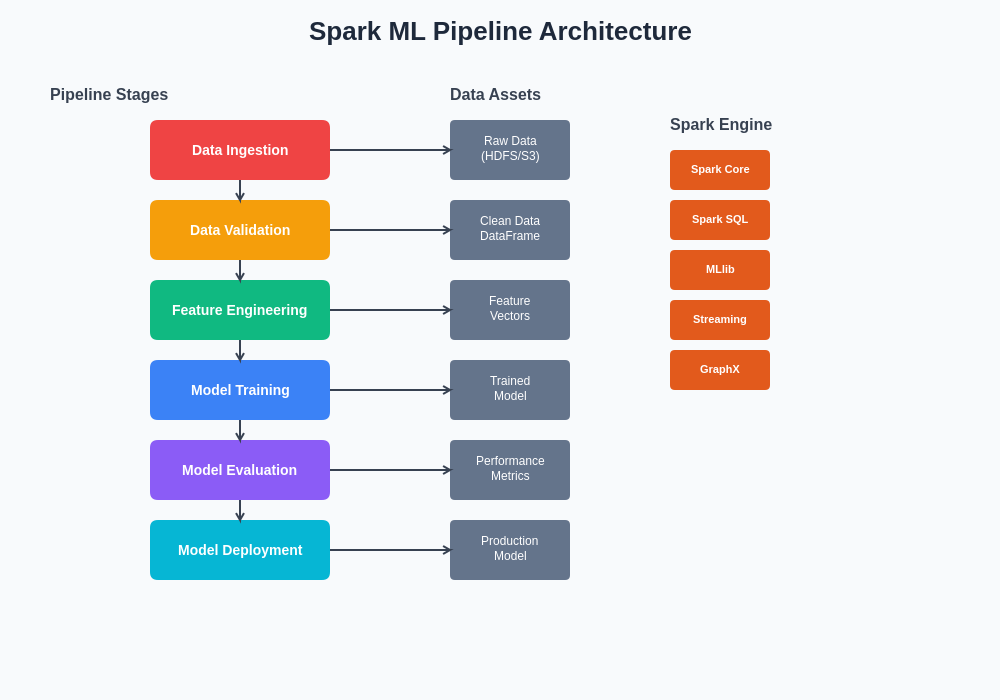
The architectural components of a typical Spark machine learning pipeline encompass multiple layers of abstraction, from low-level data ingestion and storage interfaces through high-level algorithm implementations and model deployment mechanisms. This layered approach enables the creation of modular, scalable systems that can be easily maintained, extended, and optimized according to evolving business requirements and technical constraints.
Advanced Feature Engineering Techniques
Feature engineering represents one of the most critical aspects of machine learning pipeline development, often determining the difference between models that provide marginal business value and those that deliver transformative insights and capabilities. Spark’s DataFrame and Dataset APIs, combined with Scala’s expressive syntax and functional programming constructs, provide powerful tools for implementing sophisticated feature engineering workflows that can handle complex transformations, aggregations, and statistical computations across massive datasets while maintaining type safety and performance optimization.
The implementation of advanced feature engineering techniques in Spark requires deep understanding of both the underlying data characteristics and the specific requirements of target machine learning algorithms, enabling the creation of feature transformation pipelines that not only improve model performance but also enhance interpretability and reduce computational complexity. Techniques such as dimensionality reduction, categorical encoding, temporal feature extraction, and statistical normalization can be seamlessly integrated into Spark MLlib pipelines using custom transformers and estimators that encapsulate domain-specific logic while maintaining compatibility with the broader machine learning ecosystem.
The scalability advantages of implementing feature engineering within Spark become particularly apparent when dealing with high-cardinality categorical variables, time-series data with complex seasonality patterns, or text data requiring sophisticated natural language processing transformations. Spark’s ability to distribute these computationally intensive operations across cluster resources while maintaining data locality and minimizing network overhead ensures that even the most complex feature engineering workflows can be executed efficiently on datasets containing billions of records and thousands of features.
Model Training and Hyperparameter Optimization
The training of machine learning models on large-scale datasets presents unique challenges related to computational efficiency, memory management, and convergence optimization that require specialized approaches tailored to distributed computing environments. Spark MLlib addresses these challenges through a combination of parallelized algorithm implementations, intelligent data partitioning strategies, and adaptive optimization techniques that can automatically adjust training parameters based on cluster characteristics and dataset properties, enabling the efficient training of complex models that would be infeasible on single-machine environments.
Hyperparameter optimization in distributed environments introduces additional complexity layers related to resource allocation, fault tolerance, and convergence monitoring that must be carefully managed to ensure optimal model performance while maintaining reasonable training times and computational costs. Spark’s support for cross-validation, grid search, and more advanced hyperparameter optimization techniques such as Bayesian optimization enables the systematic exploration of hyperparameter spaces while leveraging cluster resources efficiently through intelligent parallelization strategies that minimize redundant computations and maximize resource utilization.
Enhance your research capabilities with Perplexity to access comprehensive information about the latest developments in distributed machine learning and big data processing technologies. The rapid evolution of these fields requires continuous learning and adaptation to maintain competitive advantage in developing cutting-edge analytical solutions.
Implementing Robust Model Evaluation Frameworks
The evaluation of machine learning models in distributed environments requires sophisticated frameworks that can handle the complexities of cross-validation, statistical significance testing, and performance monitoring across multiple metrics and evaluation scenarios while maintaining the integrity of validation processes and preventing data leakage between training and testing datasets. Spark MLlib provides comprehensive evaluation utilities that support both regression and classification scenarios, including specialized metrics for imbalanced datasets, multi-class classification problems, and time-series forecasting applications.
The implementation of robust evaluation frameworks becomes particularly critical when dealing with streaming data scenarios where model performance must be continuously monitored and adapted based on evolving data patterns and concept drift. Spark Structured Streaming’s integration with MLlib enables the development of online evaluation systems that can detect performance degradation in real-time, trigger model retraining procedures automatically, and maintain detailed performance histories that facilitate root cause analysis and optimization efforts.
The scalability requirements of comprehensive model evaluation extend beyond simple accuracy measurements to encompass fairness assessment, explainability analysis, and robustness testing across diverse demographic groups and edge cases that may not be well-represented in training datasets. Advanced evaluation frameworks must incorporate statistical testing procedures, confidence interval calculations, and bias detection algorithms that can operate efficiently across distributed datasets while providing statistically meaningful results that support informed decision-making about model deployment and optimization strategies.
Production Deployment and Model Serving
The transition from experimental model development to production deployment represents a critical phase in the machine learning lifecycle that requires careful consideration of factors such as latency requirements, throughput expectations, fault tolerance specifications, and resource optimization constraints. Spark’s integration with various serving platforms and containerization technologies enables the deployment of trained models in diverse production environments, from real-time streaming applications requiring sub-millisecond response times to batch processing systems handling millions of predictions per hour.
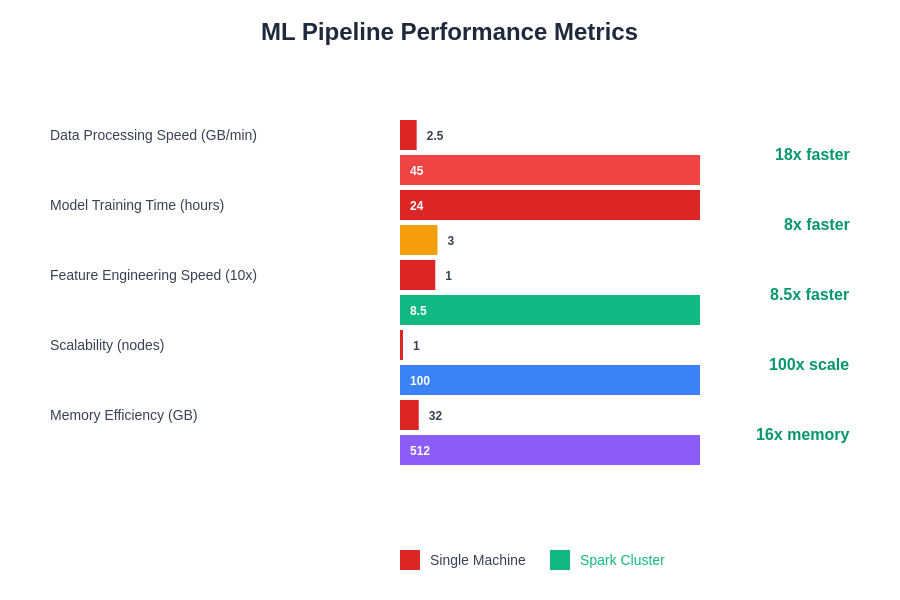
The performance characteristics of machine learning pipelines vary significantly across different deployment scenarios and workload patterns, requiring careful optimization of resource allocation, caching strategies, and computation parallelization approaches. Understanding these performance trade-offs is essential for designing systems that can meet production requirements while maintaining cost-effectiveness and operational efficiency.
The development of effective model serving architectures requires deep understanding of the specific performance characteristics and resource requirements of different machine learning algorithms, enabling the design of optimized serving infrastructure that can handle varying load patterns while maintaining consistent response times and high availability. Considerations such as model serialization formats, caching strategies, load balancing algorithms, and auto-scaling policies must be carefully evaluated and implemented to ensure robust production performance under diverse operational conditions.
Stream Processing and Real-Time Analytics
The integration of real-time stream processing capabilities with machine learning pipelines represents one of the most powerful applications of the Scala-Spark ecosystem, enabling the development of systems that can process continuous data streams while applying sophisticated analytical models to generate immediate insights and automated responses. Spark Structured Streaming’s unified programming model allows developers to write streaming applications using the same DataFrame and Dataset APIs used for batch processing, significantly reducing the complexity associated with maintaining separate code bases for different processing paradigms.
The implementation of real-time machine learning systems requires careful consideration of factors such as event-time processing, watermarking strategies, state management, and fault recovery mechanisms that are essential for maintaining data consistency and processing reliability in distributed streaming environments. Advanced streaming applications often incorporate complex windowing operations, temporal joins, and stateful computations that must be optimized for both performance and correctness while handling out-of-order events, late-arriving data, and system failures gracefully.
The scalability advantages of Spark’s streaming engine become particularly evident when dealing with high-velocity data streams requiring sophisticated analytical processing, such as fraud detection systems analyzing millions of transactions per minute, recommendation engines processing user interaction streams in real-time, or anomaly detection systems monitoring sensor data from IoT devices across global deployments. These applications demand not only high throughput and low latency but also the ability to maintain complex analytical state across extended time periods while adapting to evolving data patterns and business requirements.
Advanced Optimization Techniques
The optimization of Spark machine learning pipelines requires comprehensive understanding of both algorithmic characteristics and infrastructure capabilities, enabling the implementation of sophisticated optimization strategies that can significantly improve performance, reduce resource consumption, and enhance overall system reliability. Techniques such as adaptive query execution, dynamic partition pruning, and intelligent caching strategies can dramatically improve pipeline performance while reducing computational costs and memory requirements across diverse workload patterns and dataset characteristics.
The implementation of advanced optimization techniques often involves deep customization of Spark configurations, algorithm parameters, and infrastructure settings that must be carefully tuned based on specific use case requirements and operational constraints. Performance optimization strategies may include custom partitioning schemes, specialized serialization formats, optimized data structures, and algorithm-specific acceleration techniques that can provide substantial performance improvements while maintaining compatibility with existing pipeline architectures and deployment procedures.
Memory management optimization represents a particularly critical aspect of large-scale machine learning pipeline development, requiring careful analysis of data access patterns, memory allocation strategies, and garbage collection behaviors that can significantly impact overall system performance and stability. Advanced techniques such as off-heap storage, memory-mapped files, and columnar storage formats can provide substantial performance improvements while reducing memory pressure and improving overall system reliability under diverse operational conditions.
Integration with Modern Data Architecture
The integration of Scala-Spark machine learning pipelines with modern data architecture components such as data lakes, cloud storage systems, and containerized deployment platforms requires careful consideration of factors such as data governance, security, compliance, and operational monitoring that are essential for enterprise-grade analytical solutions. Modern data architectures often incorporate multiple storage layers, processing engines, and analytical tools that must be seamlessly integrated while maintaining performance, reliability, and security standards across the entire data processing lifecycle.
Cloud-native deployment strategies for Spark applications involve sophisticated orchestration frameworks, auto-scaling mechanisms, and resource optimization techniques that can significantly improve operational efficiency while reducing infrastructure costs and management overhead. The implementation of cloud-native architectures often requires integration with various managed services, monitoring platforms, and security frameworks that must be carefully coordinated to ensure optimal performance and compliance with organizational policies and regulatory requirements.
The evolution toward microservices-based architectures and containerized deployments has created new opportunities for improving the modularity, scalability, and maintainability of machine learning pipelines while introducing additional complexity related to service discovery, inter-service communication, and distributed debugging that must be carefully managed through appropriate tooling and operational procedures.
Future Trends and Technological Evolution
The continued evolution of the big data and machine learning landscape is driving significant innovations in areas such as automated machine learning, federated learning, and edge computing that are reshaping how large-scale analytical systems are designed, implemented, and operated. Emerging technologies such as quantum computing, neuromorphic processors, and advanced GPU architectures promise to unlock new levels of computational capability that will enable even more sophisticated analytical applications while potentially requiring fundamental changes to existing algorithmic approaches and system architectures.
The integration of artificial intelligence and machine learning capabilities into the data processing infrastructure itself represents a particularly promising area of development, with intelligent systems capable of automatically optimizing resource allocation, predicting system failures, and adapting processing strategies based on workload characteristics and performance requirements. These self-optimizing systems have the potential to significantly reduce operational overhead while improving system reliability and performance across diverse deployment scenarios and use cases.
The democratization of advanced analytical capabilities through improved tooling, automated pipeline generation, and intelligent system optimization is likely to accelerate the adoption of sophisticated machine learning solutions across industries and organizational functions that have traditionally lacked the technical expertise or resources necessary to implement large-scale analytical systems. This democratization trend is supported by continued improvements in system usability, operational simplicity, and integration capabilities that reduce the barriers to entry for organizations seeking to leverage advanced analytical capabilities for competitive advantage.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on current understanding of big data technologies and machine learning practices. Readers should conduct their own research and consider their specific requirements when implementing Scala and Spark-based solutions. The effectiveness of techniques described may vary depending on specific use cases, data characteristics, and infrastructure constraints. Performance results may vary based on hardware specifications, dataset sizes, and implementation details.