
The convergence of serverless computing and artificial intelligence has created a paradigm shift in how AI applications are deployed, scaled, and maintained across modern cloud infrastructure. This revolutionary approach eliminates the complexities of traditional server management while providing unprecedented flexibility, cost efficiency, and global reach for AI-powered applications. As organizations increasingly seek to democratize AI capabilities and reduce operational overhead, serverless AI platforms have emerged as the cornerstone of next-generation intelligent applications.
Discover the latest trends in AI deployment strategies to understand how serverless technologies are reshaping the landscape of artificial intelligence implementation. The marriage of serverless architecture with AI capabilities represents more than just a technological evolution; it embodies a fundamental transformation in how developers conceive, build, and deploy intelligent systems that can scale dynamically based on demand while maintaining cost effectiveness and operational simplicity.
The Serverless AI Revolution
Serverless computing has fundamentally transformed the AI deployment landscape by abstracting away infrastructure management concerns and enabling developers to focus purely on building intelligent applications. This approach eliminates the need for capacity planning, server provisioning, and infrastructure maintenance while providing automatic scaling capabilities that align perfectly with the unpredictable demand patterns typical of AI workloads. The serverless model ensures that computational resources are allocated precisely when needed and scaled down during periods of low activity, resulting in optimal cost efficiency.
The integration of AI capabilities into serverless platforms has opened new possibilities for building sophisticated intelligent applications without the traditional barriers of infrastructure complexity. Developers can now deploy machine learning models, natural language processing systems, computer vision applications, and predictive analytics solutions with minimal operational overhead. This democratization of AI deployment has accelerated innovation cycles and enabled organizations of all sizes to leverage advanced AI capabilities without substantial upfront infrastructure investments.
The serverless AI ecosystem encompasses various specialized platforms and services, each optimized for different use cases and performance requirements. From AWS Lambda’s comprehensive AI service integrations to Vercel Functions’ seamless frontend AI implementations and edge computing solutions that bring intelligence closer to users, the diversity of serverless AI options provides developers with unprecedented flexibility in architecting intelligent applications.
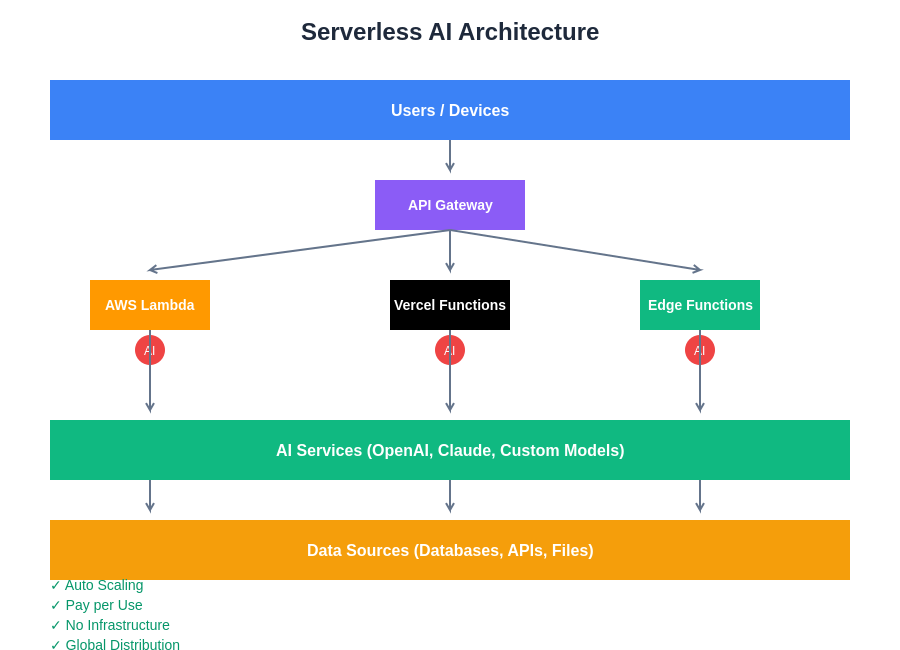
The architectural foundation of serverless AI systems demonstrates the seamless integration between user requests, API gateways, distributed function execution, and AI service orchestration. This layered approach ensures optimal resource utilization while maintaining the flexibility to scale individual components independently based on demand patterns and performance requirements.
AWS Lambda: The Foundation of Serverless AI
Amazon Web Services Lambda represents the pioneering force in serverless computing and has evolved into a comprehensive platform for deploying AI workloads at scale. Lambda’s event-driven architecture perfectly complements AI applications that require responsive, on-demand processing capabilities. The platform’s integration with AWS’s extensive AI and machine learning services, including SageMaker, Rekognition, Comprehend, and Textract, creates a powerful ecosystem for building sophisticated intelligent applications without infrastructure management complexities.
Lambda’s ability to handle concurrent executions and automatically scale based on incoming requests makes it particularly well-suited for AI workloads that experience variable demand patterns. The platform supports multiple programming languages and runtime environments, enabling developers to deploy AI models built with popular frameworks such as TensorFlow, PyTorch, and Scikit-learn. The integration with AWS’s broader ecosystem allows for seamless data pipeline creation, model training workflows, and real-time inference deployment.
Enhance your serverless AI capabilities with Claude for advanced reasoning and natural language processing tasks that require sophisticated AI assistance. The combination of Lambda’s scalable infrastructure with powerful AI services creates opportunities for building applications that can handle everything from simple image classification tasks to complex multi-modal AI systems that process text, images, and audio simultaneously.
The cost model of AWS Lambda aligns perfectly with AI workload characteristics, charging only for actual compute time consumed during function execution. This pay-per-use pricing structure eliminates the need for maintaining idle server capacity and provides significant cost advantages for AI applications with sporadic or unpredictable usage patterns. The platform’s millisecond billing granularity ensures that organizations pay only for the exact computational resources consumed by their AI processing tasks.
Vercel Functions: Frontend-Optimized AI Deployment
Vercel Functions has emerged as a leading platform for deploying AI capabilities that integrate seamlessly with modern web applications and frontend frameworks. The platform’s emphasis on developer experience and performance optimization makes it particularly attractive for building AI-powered web applications that require low latency and smooth user experiences. Vercel’s integration with popular frontend frameworks such as Next.js, React, and Vue.js enables developers to create full-stack AI applications with minimal configuration overhead.
The platform’s edge-first approach ensures that AI functions are deployed across a global network of edge locations, reducing latency for users regardless of their geographic location. This distributed deployment model is particularly beneficial for AI applications that require real-time responses, such as chatbots, recommendation systems, and interactive AI assistants. Vercel’s automatic deployment pipeline integrates with popular development workflows, enabling continuous deployment of AI functions alongside frontend application updates.
Vercel Functions excels in scenarios where AI capabilities need to be tightly integrated with user interface components and frontend application logic. The platform’s support for streaming responses enables the creation of dynamic AI applications that can provide real-time updates and interactive experiences. This capability is particularly valuable for building conversational AI interfaces, progressive content generation systems, and collaborative AI tools that require immediate user feedback loops.
The platform’s developer-friendly approach includes comprehensive debugging tools, real-time analytics, and performance monitoring capabilities that help developers optimize their AI applications for maximum efficiency. Vercel’s integration with popular AI services and APIs enables developers to quickly incorporate advanced AI capabilities such as natural language processing, image analysis, and content generation without building these capabilities from scratch.
Edge Computing: Bringing AI Closer to Users
Edge computing represents the next evolution in serverless AI deployment, bringing intelligent processing capabilities directly to the network edge where users and devices interact with applications. This approach dramatically reduces latency, improves performance, and enables AI applications to function effectively even in scenarios with limited connectivity or bandwidth constraints. Edge AI deployment is particularly crucial for applications requiring real-time decision making, such as autonomous systems, industrial IoT applications, and interactive media processing.
The distribution of AI capabilities across edge locations creates opportunities for building more responsive and resilient intelligent applications. Edge computing platforms such as Cloudflare Workers, AWS Lambda@Edge, and Vercel Edge Functions enable developers to deploy AI logic that executes closer to end users, resulting in faster response times and improved user experiences. This geographical distribution of processing power also provides natural redundancy and fault tolerance capabilities.
Edge AI deployment introduces unique considerations around model optimization, resource constraints, and data synchronization that differ from traditional cloud-based AI deployments. Edge environments typically have more limited computational resources and storage capacity, requiring careful optimization of AI models and efficient resource utilization strategies. However, these constraints also drive innovation in model compression, quantization, and efficient inference techniques that benefit the broader AI community.
The security implications of edge AI deployment require careful consideration of data privacy, model protection, and secure communication protocols. Edge computing enables sensitive data processing to occur closer to its source, potentially improving privacy and compliance with data protection regulations. However, the distributed nature of edge deployments also creates new security challenges that require comprehensive security strategies and monitoring capabilities.
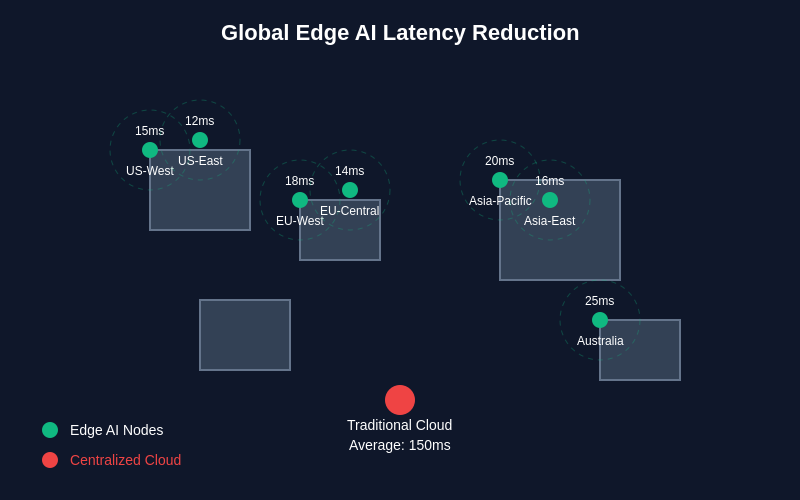
The global distribution of edge AI nodes dramatically reduces latency compared to traditional centralized cloud deployments, with average response times improving from 150ms to as low as 12-25ms depending on geographic proximity. This latency reduction is crucial for real-time AI applications such as autonomous systems, interactive media processing, and responsive user interfaces.
Architecture Patterns for Serverless AI
Successful serverless AI implementations require careful consideration of architecture patterns that optimize for performance, cost, and maintainability. The event-driven nature of serverless platforms aligns well with AI workloads that process discrete requests, batch operations, and real-time data streams. Common architectural patterns include API gateway integration for RESTful AI services, event-driven processing pipelines for data transformation and model inference, and asynchronous processing workflows for computationally intensive AI tasks.
The microservices approach to AI application architecture enables teams to decompose complex intelligent systems into smaller, manageable components that can be developed, deployed, and scaled independently. This modular approach facilitates experimentation with different AI models and algorithms while maintaining system stability and enabling rapid iteration cycles. Each microservice can be optimized for its specific AI workload characteristics and resource requirements.
Data flow architecture becomes particularly important in serverless AI applications, where efficient data movement and transformation can significantly impact performance and cost. Strategies such as data preprocessing at the edge, efficient serialization formats, and streaming data processing help optimize the overall system performance. The integration of serverless AI functions with managed data services such as databases, data warehouses, and message queues creates robust data processing pipelines.
Leverage Perplexity’s research capabilities to stay informed about emerging serverless AI architecture patterns and best practices that are shaping the future of intelligent application development. The continuous evolution of serverless platforms and AI technologies requires ongoing learning and adaptation of architectural approaches to maintain competitive advantages and operational efficiency.
Performance Optimization Strategies
Optimizing performance in serverless AI environments requires understanding the unique characteristics and constraints of serverless platforms while maximizing the efficiency of AI workloads. Cold start latency represents one of the most significant performance challenges in serverless AI deployment, particularly for applications requiring immediate response times. Strategies such as provisioned concurrency, connection pooling, and model caching help mitigate these challenges while maintaining the cost benefits of serverless computing.
Model optimization techniques play a crucial role in serverless AI performance, where computational resources and execution time directly impact costs. Approaches such as model quantization, pruning, and distillation can significantly reduce model size and inference time while maintaining acceptable accuracy levels. The selection of appropriate model architectures and frameworks also influences performance characteristics and resource utilization patterns.
Memory management and resource allocation strategies become particularly important in serverless environments where functions operate within predefined resource constraints. Efficient memory usage, garbage collection optimization, and resource cleanup procedures help ensure consistent performance and prevent resource exhaustion issues. The careful balance between memory allocation and execution speed requires ongoing monitoring and optimization efforts.
Caching strategies at multiple levels of the serverless AI stack can dramatically improve performance and reduce costs. Model caching, result caching, and data preprocessing caching help minimize redundant computations and data retrieval operations. The implementation of intelligent caching policies that consider data freshness requirements, cache invalidation strategies, and storage costs helps optimize overall system performance.
Security and Compliance Considerations
Security in serverless AI environments requires comprehensive strategies that address the unique challenges of distributed, event-driven architectures while protecting sensitive AI models and data. The shared responsibility model of serverless platforms means that while cloud providers handle infrastructure security, application developers remain responsible for securing their AI functions, data processing logic, and integration points. This distributed security model requires careful attention to authentication, authorization, and data encryption throughout the AI processing pipeline.
Model protection and intellectual property security become particularly important considerations in serverless AI deployments where models may be exposed through API endpoints or processing functions. Strategies such as model encryption, secure model serving, and access control mechanisms help protect proprietary AI algorithms and training data from unauthorized access or reverse engineering attempts. The implementation of comprehensive audit logging and monitoring capabilities enables detection and response to potential security threats.
Data privacy and compliance requirements add complexity to serverless AI deployments, particularly when processing personal or sensitive information across multiple geographic regions and jurisdictions. The distributed nature of serverless and edge computing platforms requires careful consideration of data residency requirements, cross-border data transfer regulations, and privacy protection mechanisms. Implementing privacy-preserving AI techniques such as federated learning, differential privacy, and homomorphic encryption helps address these challenges while maintaining AI functionality.
The dynamic scaling characteristics of serverless platforms require security strategies that can adapt to changing load patterns and resource allocations. Traditional security perimeters become less relevant in serverless environments, requiring zero-trust security models that verify every request and transaction. The implementation of comprehensive identity and access management systems, network security controls, and runtime protection mechanisms helps maintain security posture across dynamic serverless AI deployments.
Cost Management and Optimization
Cost optimization in serverless AI environments requires understanding the complex interplay between computational resource usage, data transfer costs, and service integration expenses. The pay-per-use pricing model of serverless platforms provides inherent cost advantages for variable workloads, but also requires careful monitoring and optimization to prevent unexpected cost escalation. Understanding the pricing models of different serverless platforms and AI services enables informed architectural decisions that balance performance requirements with cost constraints.
Resource utilization optimization plays a crucial role in serverless AI cost management, where inefficient resource allocation can quickly lead to significant expenses. Strategies such as right-sizing function memory allocations, optimizing execution time, and minimizing data transfer volumes help reduce operational costs while maintaining performance standards. The implementation of automated resource optimization tools and cost monitoring dashboards enables proactive cost management and budget control.
The selection of appropriate AI services and deployment strategies significantly impacts overall costs in serverless environments. Comparing costs between different AI service providers, evaluating trade-offs between managed services and custom implementations, and optimizing data processing workflows help achieve optimal cost-performance ratios. The consideration of volume discounts, reserved capacity options, and long-term pricing agreements provides additional opportunities for cost optimization.
Implementing comprehensive cost monitoring and alerting systems enables organizations to maintain visibility into serverless AI spending patterns and identify optimization opportunities. The correlation of cost data with performance metrics and business outcomes helps justify AI investments and guide future resource allocation decisions. Regular cost reviews and optimization initiatives ensure that serverless AI deployments remain economically viable as they scale and evolve.

The performance advantages of serverless AI deployments become evident across multiple operational metrics, with significant improvements in deployment speed, scaling capabilities, cost efficiency, and maintenance requirements. Organizations adopting serverless AI architectures consistently achieve up to 70% reduction in infrastructure costs while dramatically improving their ability to scale and maintain AI applications.
Integration with AI Services and APIs
The ecosystem of AI services and APIs available for serverless integration continues to expand, providing developers with powerful capabilities that can be easily incorporated into serverless applications. Major cloud providers offer comprehensive AI service portfolios that include natural language processing, computer vision, speech recognition, and predictive analytics capabilities accessible through simple API calls. The integration of these services with serverless functions enables the rapid development of sophisticated AI applications without requiring deep machine learning expertise.
Third-party AI service integration opens additional possibilities for specialized capabilities and competitive pricing options. Services such as OpenAI’s GPT models, Anthropic’s Claude, Google’s AI services, and specialized AI APIs for niche applications provide developers with diverse options for incorporating advanced AI capabilities. The evaluation of service reliability, performance characteristics, and pricing models helps guide integration decisions that align with application requirements and budget constraints.
The orchestration of multiple AI services within serverless architectures enables the creation of complex AI workflows that combine different capabilities and processing stages. Workflow orchestration tools and patterns help manage the complexity of multi-service AI applications while maintaining reliability and performance standards. The implementation of error handling, retry logic, and fallback mechanisms ensures robust operation in distributed AI processing environments.
API design and management considerations become increasingly important as serverless AI applications integrate with multiple external services and provide AI capabilities to other systems. The implementation of comprehensive API documentation, versioning strategies, and rate limiting mechanisms helps ensure sustainable and maintainable AI service integrations. Security considerations such as API key management, request authentication, and data encryption require careful attention throughout the integration process.
Monitoring and Observability
Comprehensive monitoring and observability strategies are essential for maintaining reliable and performant serverless AI applications in production environments. The distributed nature of serverless architectures and the complexity of AI processing workflows require sophisticated monitoring approaches that provide visibility into system behavior, performance characteristics, and potential issues. The implementation of end-to-end observability enables teams to understand application behavior and optimize performance across the entire AI processing pipeline.
Performance monitoring for serverless AI applications requires tracking metrics specific to both serverless execution characteristics and AI processing performance. Key metrics include function execution time, cold start frequency, memory utilization, model inference latency, and accuracy metrics. The correlation of these metrics with business outcomes and user experience indicators provides insights into overall application effectiveness and areas for improvement.
Error handling and debugging in serverless AI environments present unique challenges due to the ephemeral nature of function executions and the complexity of AI processing logic. Comprehensive logging strategies, distributed tracing implementations, and error aggregation tools help identify and resolve issues quickly. The implementation of automated alerting and incident response procedures ensures rapid detection and resolution of critical issues that could impact user experience or system reliability.
The analysis of monitoring data and performance trends enables proactive optimization and capacity planning for serverless AI applications. Understanding usage patterns, performance bottlenecks, and scaling characteristics helps guide architectural improvements and resource allocation decisions. The implementation of automated performance optimization tools and recommendations systems can help maintain optimal performance as applications evolve and scale.
Future Trends and Innovations
The future of serverless AI promises continued innovation in areas such as specialized AI hardware integration, improved cold start performance, and enhanced developer tooling. The emergence of AI-optimized processor architectures and their integration into serverless platforms will enable more efficient and cost-effective AI workload execution. Advances in container technology and function initialization techniques continue to reduce cold start latency, making serverless platforms more suitable for latency-sensitive AI applications.
The evolution of edge computing capabilities will enable more sophisticated AI processing at network edges, bringing intelligent capabilities closer to users and devices. The development of distributed AI frameworks and federated learning approaches will enable collaborative AI processing across edge and cloud environments while maintaining privacy and security requirements. These advances will create new opportunities for building responsive and scalable AI applications that operate efficiently across diverse computing environments.
The integration of serverless platforms with emerging AI technologies such as large language models, multimodal AI systems, and autonomous agents will create new possibilities for building intelligent applications. The development of specialized serverless AI frameworks and tools will simplify the deployment and management of complex AI workloads while maintaining the benefits of serverless architecture. These innovations will continue to democratize access to advanced AI capabilities and enable broader adoption of intelligent applications across industries.
The convergence of serverless computing, edge technologies, and artificial intelligence represents a transformative force that will reshape how intelligent applications are conceived, developed, and deployed. Organizations that embrace these technologies and develop expertise in serverless AI architecture will be well-positioned to capitalize on the opportunities presented by this technological convergence while building more efficient, scalable, and cost-effective AI solutions.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The technologies and strategies discussed are based on current industry understanding and may evolve rapidly as serverless and AI technologies continue to advance. Readers should conduct thorough research and consider their specific requirements, constraints, and objectives when implementing serverless AI solutions. The effectiveness and suitability of different approaches may vary depending on use cases, technical requirements, and organizational factors.