The convergence of artificial intelligence and embedded systems has reached a transformative milestone with the advent of STM32 AI capabilities on ARM Cortex processors. This revolutionary integration enables machine learning inference directly on resource-constrained microcontrollers, opening unprecedented opportunities for intelligent edge computing applications. The STM32 ecosystem, powered by ARM Cortex architectures, provides developers with a comprehensive platform for deploying sophisticated neural networks and machine learning models in environments where traditional cloud-based AI solutions are impractical or impossible.
Explore the latest AI development trends to understand how edge computing and embedded AI are reshaping the technology landscape. The ability to perform real-time machine learning inference on microcontrollers represents a paradigm shift that enables autonomous decision-making in IoT devices, industrial sensors, and consumer electronics without requiring constant connectivity to external computing resources.
The Foundation of STM32 AI Architecture
The STM32 AI ecosystem builds upon the robust foundation of ARM Cortex processor architectures, leveraging specialized hardware features and optimized software frameworks to deliver efficient machine learning capabilities. The integration of dedicated neural processing units, enhanced memory architectures, and optimized instruction sets creates an environment where complex AI algorithms can execute within the stringent power and computational constraints typical of embedded applications.
The architecture encompasses multiple layers of optimization, from hardware-accelerated mathematical operations to sophisticated compiler optimizations that maximize the utilization of available processing resources. Modern STM32 microcontrollers incorporate ARM Cortex-M4, Cortex-M7, and Cortex-M33 cores, each offering unique advantages for different types of machine learning workloads. The Cortex-M4 and M7 processors feature digital signal processing extensions that accelerate common neural network operations, while the Cortex-M33 introduces enhanced security features essential for AI applications handling sensitive data.
Neural Network Optimization Strategies
Successful deployment of machine learning models on STM32 platforms requires sophisticated optimization techniques that balance computational efficiency with model accuracy. Quantization represents one of the most critical optimization strategies, where neural network weights and activations are converted from 32-bit floating-point representations to 8-bit or even lower precision integers. This reduction in numerical precision dramatically decreases memory requirements and computational complexity while maintaining acceptable model performance for most embedded applications.
The optimization process extends beyond simple quantization to encompass advanced techniques such as pruning, where redundant neural network connections are systematically removed, and knowledge distillation, where complex models are compressed into smaller, more efficient representations suitable for microcontroller deployment. Layer fusion optimizations combine multiple neural network operations into single computational kernels, reducing memory access overhead and improving overall execution efficiency.
Enhance your AI development with Claude’s advanced capabilities for comprehensive model optimization and deployment guidance. The sophisticated reasoning capabilities of modern AI assistants can significantly accelerate the optimization process by providing insights into model architecture improvements and deployment strategies tailored to specific hardware constraints.
Development Workflow and Toolchain Integration
The STM32 AI development workflow integrates seamlessly with established embedded development environments while introducing specialized tools for machine learning model deployment and optimization. The STM32CubeMX ecosystem provides comprehensive support for AI model integration, offering automated code generation capabilities that streamline the process of incorporating trained neural networks into embedded applications.
The development process typically begins with model training using popular frameworks such as TensorFlow, PyTorch, or Keras, followed by conversion to optimized formats compatible with STM32 hardware. The X-CUBE-AI expansion package serves as the bridge between high-level machine learning frameworks and low-level embedded implementations, providing automatic optimization and code generation capabilities that eliminate much of the complexity traditionally associated with embedded AI deployment.
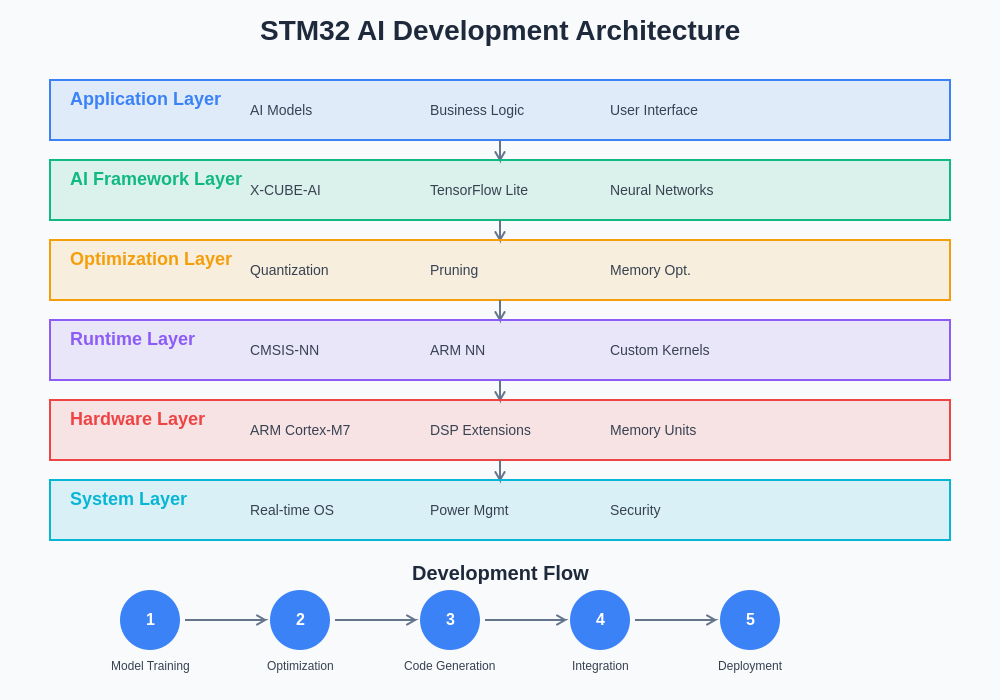
The comprehensive development architecture encompasses every stage from initial model conception through final deployment, ensuring seamless integration between machine learning workflows and embedded system development practices. This systematic approach enables rapid prototyping and iterative refinement of AI-enabled embedded applications.
Memory Management and Resource Optimization
Effective memory management represents a critical challenge in STM32 AI applications, where limited RAM and flash storage must accommodate both neural network parameters and application code. Advanced memory optimization techniques include dynamic memory allocation strategies that load and unload model segments as needed, enabling deployment of larger neural networks than would otherwise be possible within available memory constraints.
The memory architecture of STM32 devices provides multiple storage options, including internal flash memory, external QSPI flash, and various RAM configurations that can be strategically utilized to optimize model deployment. Techniques such as weight sharing, where multiple neural network layers utilize common parameter sets, and progressive loading, where model components are loaded from external storage as required, enable sophisticated AI applications on resource-constrained platforms.
Real-Time Inference and Performance Optimization
Real-time inference capabilities on STM32 platforms require careful optimization of computational workflows to meet stringent timing requirements while maintaining accuracy standards. The ARM Cortex architecture provides specialized instructions for accelerating common neural network operations, including single instruction multiple data operations that can process multiple neural network activations simultaneously.
Performance optimization extends beyond individual operation acceleration to encompass system-level optimizations such as interrupt management, power state transitions, and peripheral coordination. The integration of dedicated hardware accelerators, such as the Chrom-ART graphics accelerator found in many STM32 devices, can significantly improve the performance of computer vision and image processing applications that form the foundation of many embedded AI systems.
Power Efficiency and Energy Optimization
Power consumption represents a paramount concern in embedded AI applications, particularly those operating from battery power or energy harvesting sources. STM32 AI implementations leverage sophisticated power management techniques that dynamically adjust processor performance based on computational requirements, enabling extended operational lifetime without sacrificing functionality.
The optimization of power consumption involves multiple complementary strategies, including clock gating to disable unused processor components, voltage scaling to reduce power consumption during low-intensity operations, and intelligent scheduling algorithms that minimize the frequency of high-power computational phases. Advanced sleep modes allow STM32 devices to enter ultra-low-power states between inference operations while maintaining rapid wake-up capabilities for time-critical applications.
Discover comprehensive AI research capabilities with Perplexity to explore cutting-edge power optimization techniques and emerging technologies in embedded AI development. The rapidly evolving landscape of embedded AI requires continuous learning and adaptation to leverage the latest optimization strategies and hardware capabilities.
Security Considerations in Embedded AI
Security implementation in STM32 AI applications encompasses multiple layers of protection, from secure boot processes that verify the integrity of neural network models to runtime protection mechanisms that prevent unauthorized access to sensitive AI algorithms. The ARM TrustZone technology available in Cortex-M33 processors provides hardware-enforced security boundaries that protect critical AI models and data from potential threats.
Cryptographic protection of neural network models prevents intellectual property theft and ensures model integrity throughout the deployment lifecycle. Secure key management systems protect encryption keys used for model protection, while secure communication protocols ensure that data transmitted between embedded AI devices and external systems remains confidential and tamper-resistant.
Computer Vision Applications and Optimization
Computer vision represents one of the most computationally demanding applications for embedded AI, requiring sophisticated optimization techniques to achieve real-time performance on STM32 platforms. Specialized algorithms optimized for resource-constrained environments enable applications such as object detection, facial recognition, and gesture recognition to operate effectively within the computational and memory limitations of microcontroller platforms.
The optimization of computer vision algorithms involves techniques such as region of interest processing, where computational resources are focused on relevant portions of input images, and hierarchical processing strategies that use simple algorithms for initial filtering before applying more sophisticated analysis to promising candidates. Hardware-accelerated image processing capabilities available in many STM32 devices significantly improve the performance of vision-based AI applications.
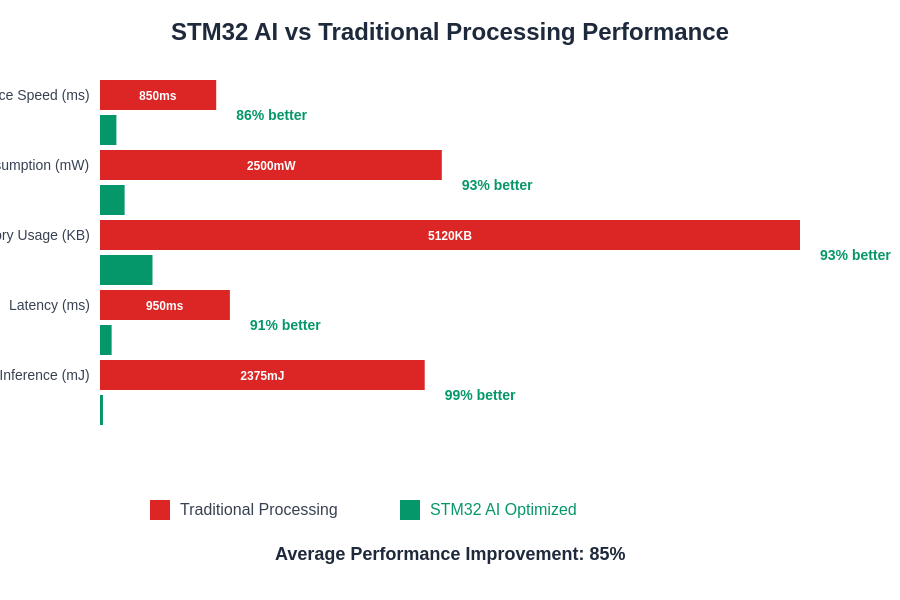
The substantial performance improvements achieved through STM32 AI optimization techniques demonstrate the viability of sophisticated machine learning applications on embedded platforms. These enhancements enable real-time processing capabilities that were previously achievable only on much more powerful computing platforms.
Audio Processing and Speech Recognition
Audio processing applications on STM32 platforms leverage specialized hardware features such as digital microphone interfaces and audio processing units to implement sophisticated speech recognition and audio analysis capabilities. The optimization of audio processing algorithms requires careful consideration of sampling rates, buffer management, and real-time processing constraints to ensure reliable operation in demanding environments.
Advanced signal processing techniques such as feature extraction, noise reduction, and acoustic modeling are implemented using optimized algorithms that maximize the utilization of available processing resources. The integration of hardware-accelerated fast Fourier transform operations significantly improves the performance of frequency-domain audio processing applications commonly used in speech recognition and audio classification systems.
Sensor Fusion and Predictive Analytics
The combination of multiple sensor inputs through sophisticated fusion algorithms enables STM32 AI systems to achieve robust and reliable operation in complex environments. Predictive analytics capabilities allow embedded systems to anticipate future conditions and adjust behavior accordingly, enabling proactive rather than reactive responses to changing environmental conditions.
Sensor fusion implementations on STM32 platforms utilize Kalman filters, particle filters, and other advanced estimation techniques to combine information from accelerometers, gyroscopes, magnetometers, and other sensors into coherent state estimates. Machine learning algorithms trained on historical sensor data can identify patterns and trends that enable predictive maintenance, anomaly detection, and intelligent resource management in embedded applications.
Industrial IoT and Edge Computing Integration
The integration of STM32 AI capabilities into Industrial Internet of Things applications enables sophisticated edge computing scenarios where intelligent decision-making occurs directly at the point of data collection. This distributed intelligence approach reduces latency, improves reliability, and decreases bandwidth requirements compared to traditional cloud-centric AI architectures.
Edge computing implementations leverage the real-time processing capabilities of STM32 platforms to implement sophisticated control algorithms, quality assurance systems, and predictive maintenance capabilities that operate independently of external connectivity. The combination of local AI processing with selective cloud communication creates hybrid architectures that optimize performance, reliability, and cost-effectiveness for industrial applications.
Development Best Practices and Debugging Techniques
Effective development of STM32 AI applications requires specialized debugging and validation techniques that account for the unique challenges of embedded machine learning systems. Traditional debugging approaches must be adapted to handle the complexity of neural network inference while operating within the constraints of resource-limited embedded platforms.
Profiling tools specifically designed for embedded AI applications provide detailed insights into computational bottlenecks, memory usage patterns, and power consumption characteristics that enable systematic optimization of deployed models. Validation frameworks ensure that optimized models maintain acceptable accuracy levels while meeting performance and resource constraints required for successful deployment.
Deployment Strategies and Production Considerations
The transition from development prototypes to production-ready STM32 AI systems requires careful consideration of manufacturing, testing, and maintenance requirements that ensure reliable long-term operation. Automated testing frameworks validate both functional correctness and performance characteristics across production variations and environmental conditions.
Field update mechanisms enable remote deployment of improved AI models and bug fixes without requiring physical access to deployed devices. Over-the-air update capabilities must be balanced with security requirements and resource constraints to ensure reliable operation while maintaining protection against potential threats.
Future Directions and Emerging Technologies
The continued evolution of STM32 AI capabilities promises even more sophisticated embedded intelligence applications as processor architectures, development tools, and optimization techniques continue advancing. Emerging technologies such as neuromorphic computing, quantum-inspired algorithms, and advanced neural architecture search techniques will further expand the capabilities of embedded AI systems.
The integration of 5G connectivity, advanced sensors, and distributed computing architectures will enable new classes of embedded AI applications that leverage the strengths of both local processing and cloud-based resources. The democratization of AI development through improved tools and frameworks will enable broader adoption of embedded intelligence across diverse application domains.
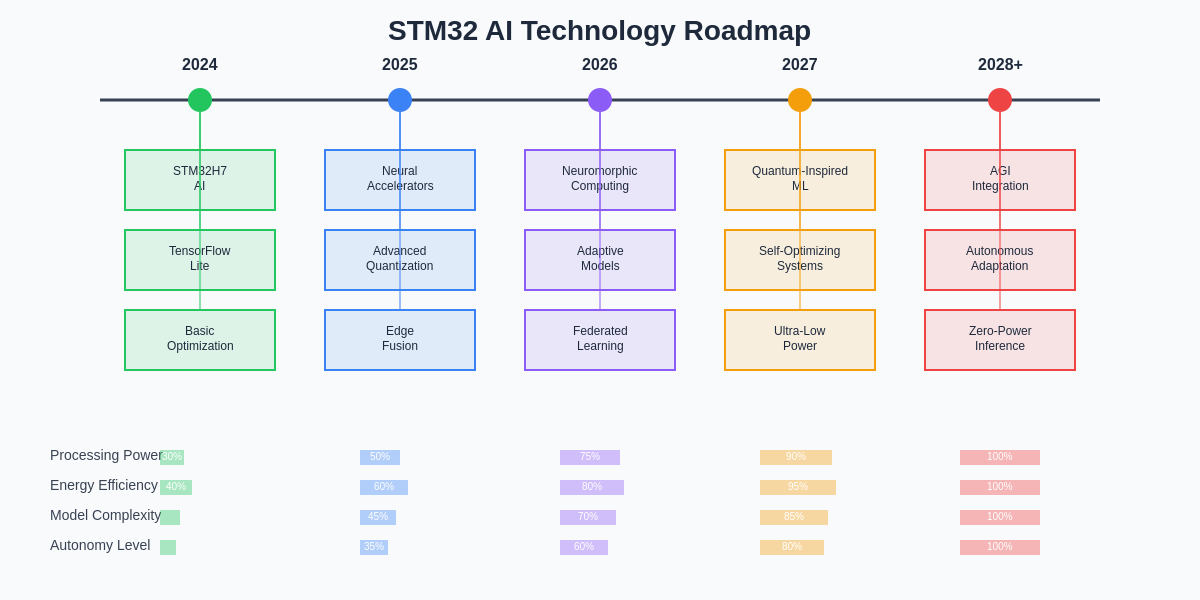
The technological roadmap for STM32 AI development showcases the continuous evolution of capabilities that will enable increasingly sophisticated embedded intelligence applications. These advancements promise to unlock new possibilities for autonomous systems, intelligent sensors, and responsive embedded devices across numerous industries and applications.
Conclusion and Implementation Guidance
The successful implementation of STM32 AI systems requires a comprehensive understanding of both machine learning principles and embedded system constraints, combined with systematic application of optimization techniques and best practices. The convergence of these disciplines creates opportunities for innovative applications that leverage the unique advantages of edge-based artificial intelligence while addressing the practical requirements of real-world deployment scenarios.
The continued advancement of STM32 AI capabilities, supported by evolving development tools and optimization techniques, promises to expand the boundaries of what is achievable with embedded intelligence. Developers who master these technologies will be well-positioned to create the next generation of intelligent embedded systems that seamlessly integrate sophisticated AI capabilities with the reliability, efficiency, and cost-effectiveness required for successful commercial deployment.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on current understanding of STM32 AI technologies and embedded machine learning development practices. Readers should conduct their own research and consider their specific requirements when implementing embedded AI solutions. The effectiveness of optimization techniques may vary depending on specific use cases, hardware configurations, and application requirements. Always consult official STMicroelectronics documentation and ARM technical resources for authoritative implementation guidance.