
The artificial intelligence landscape is experiencing a profound transformation through the revolutionary concept of synthetic data generation, a groundbreaking approach that addresses one of the most persistent challenges in machine learning development: the acquisition and utilization of high-quality training data without compromising privacy, security, or ethical considerations. This innovative methodology has emerged as a cornerstone technology that enables organizations to train sophisticated AI models while circumventing the traditional constraints associated with real-world data collection, labeling, and distribution.
Explore the latest AI developments and trends to understand how synthetic data generation fits into the broader ecosystem of artificial intelligence innovations that are reshaping industries and research methodologies. The emergence of synthetic data represents more than just a technical solution; it embodies a paradigm shift that democratizes AI development by making high-quality training data accessible to organizations regardless of their data collection capabilities or regulatory constraints.
Understanding the Synthetic Data Revolution
Synthetic data generation represents a sophisticated computational process that creates artificial datasets designed to mirror the statistical properties, patterns, and characteristics of real-world data without containing any actual information from original sources. This process involves advanced algorithms, generative models, and statistical techniques that can produce vast quantities of realistic data samples across various domains, including images, text, numerical data, and complex multi-modal datasets that combine multiple data types in coherent and meaningful ways.
The fundamental principle underlying synthetic data generation lies in the ability of modern machine learning algorithms to learn and reproduce the underlying distributions and relationships present in training data. Through techniques such as generative adversarial networks, variational autoencoders, and diffusion models, these systems can capture the essential characteristics of real data and generate new samples that maintain statistical fidelity while ensuring complete privacy protection and eliminating any risk of data leakage or unauthorized information disclosure.
The Privacy-Performance Paradigm
Traditional AI development has long struggled with the tension between data utility and privacy protection, particularly in sensitive domains such as healthcare, finance, and personal information processing. Synthetic data generation resolves this fundamental conflict by creating datasets that preserve the statistical utility necessary for effective model training while completely eliminating privacy risks associated with real personal information. This breakthrough enables organizations to develop and deploy AI systems in previously inaccessible domains where privacy regulations, ethical concerns, or competitive sensitivities made traditional data sharing impossible.
The privacy advantages of synthetic data extend beyond simple anonymization techniques, which have proven vulnerable to various re-identification attacks and inference methods. By generating entirely artificial samples that contain no traceable connections to real individuals or sensitive information, synthetic data provides mathematically provable privacy guarantees that satisfy even the most stringent regulatory requirements while maintaining the statistical properties necessary for effective machine learning model development.
Discover advanced AI capabilities with Claude for generating and analyzing synthetic datasets that meet specific requirements while maintaining statistical validity and privacy protection. The integration of sophisticated AI systems in synthetic data generation workflows enables more precise control over data characteristics, distribution properties, and quality metrics that determine the effectiveness of generated datasets for specific machine learning applications.
Generative Models and Technical Foundations
The technical infrastructure supporting synthetic data generation relies heavily on advanced generative modeling techniques that have evolved significantly with the advancement of deep learning architectures. Generative Adversarial Networks represent one of the most successful approaches, employing a competitive training framework where two neural networks engage in an adversarial process to produce increasingly realistic synthetic samples that are indistinguishable from real data according to various statistical measures and quality metrics.
Variational Autoencoders provide another powerful approach to synthetic data generation by learning compressed representations of data distributions and enabling controlled generation of new samples through manipulation of latent space variables. These models excel at capturing complex data relationships and enabling fine-grained control over generated sample characteristics, making them particularly valuable for applications requiring specific data properties or conditional generation based on particular attributes or constraints.
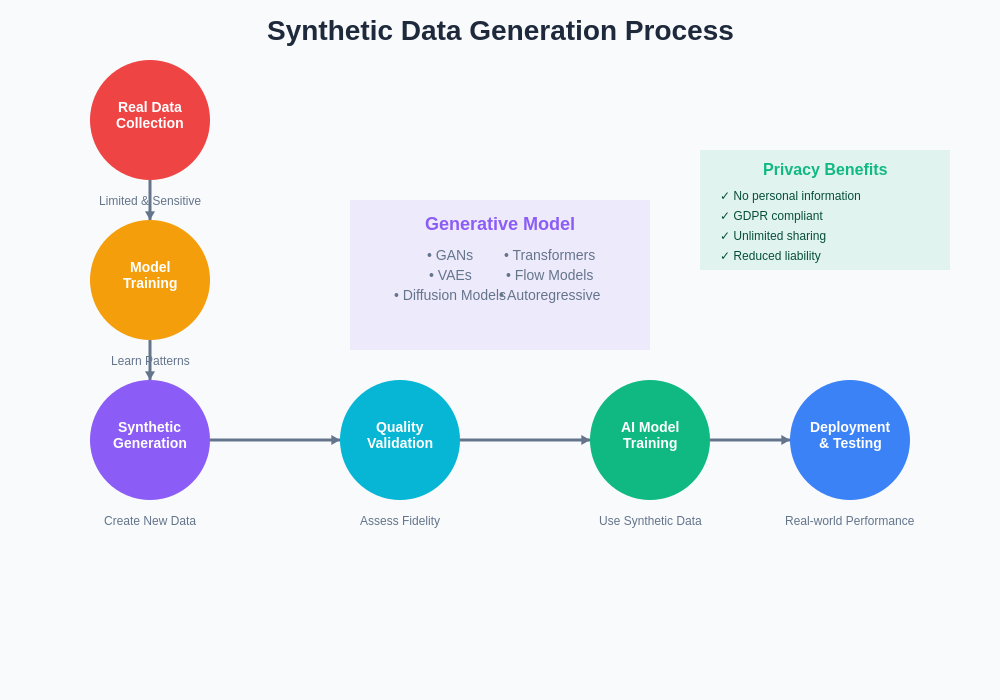
The evolution of diffusion models has introduced yet another paradigm for synthetic data generation, leveraging iterative denoising processes that gradually transform random noise into coherent data samples. These models have demonstrated remarkable capabilities in generating high-quality synthetic data across various domains, particularly excelling in image generation and complex multi-modal scenarios where traditional approaches face significant challenges in maintaining coherence and realistic appearance.
Applications Across Industries
Healthcare represents one of the most compelling application domains for synthetic data generation, where the combination of stringent privacy regulations, ethical considerations, and the critical need for large-scale datasets creates an ideal environment for synthetic data solutions. Medical imaging, electronic health records, genomic data, and clinical trial information can all benefit from synthetic generation techniques that enable research and development activities while maintaining complete patient privacy and regulatory compliance.
Financial services industry has embraced synthetic data generation for fraud detection, risk assessment, and algorithmic trading applications where real transaction data contains sensitive customer information and competitive intelligence. Synthetic financial data enables the development of sophisticated machine learning models for credit scoring, market analysis, and regulatory compliance monitoring without exposing actual customer transactions or proprietary trading strategies to potential security breaches or unauthorized access.
The autonomous vehicle industry relies heavily on synthetic data generation to create diverse training scenarios that would be impossible, dangerous, or prohibitively expensive to collect in real-world conditions. Synthetic driving data, including various weather conditions, traffic patterns, pedestrian behaviors, and edge cases, enables the development of robust autonomous driving systems while avoiding the safety risks and logistical challenges associated with comprehensive real-world data collection across all possible driving scenarios.
Quality Assessment and Validation
Ensuring the quality and utility of synthetic data represents a critical challenge that requires sophisticated evaluation methodologies and validation frameworks. Statistical measures such as distribution matching, correlation preservation, and privacy metrics provide quantitative assessments of synthetic data quality, while downstream task performance serves as the ultimate validation criterion for determining whether synthetic data can effectively replace real data in specific machine learning applications.
The evaluation of synthetic data quality involves multiple dimensions, including fidelity measures that assess how closely synthetic samples match the statistical properties of real data, utility measures that evaluate the performance of models trained on synthetic data when applied to real-world tasks, and privacy measures that quantify the degree of privacy protection provided by the synthetic generation process.
Access comprehensive AI research capabilities with Perplexity to stay current with the latest developments in synthetic data quality assessment methodologies and validation frameworks that ensure generated datasets meet the requirements for specific machine learning applications. The rapid evolution of quality assessment techniques continues to improve the reliability and effectiveness of synthetic data generation across diverse application domains.
Overcoming Data Scarcity Challenges
Many machine learning applications suffer from fundamental data scarcity issues, particularly in specialized domains where real data is rare, expensive to obtain, or subject to significant collection constraints. Synthetic data generation addresses these challenges by enabling the creation of large-scale datasets that augment limited real data samples, providing sufficient training material for developing effective machine learning models in previously data-starved domains.
The ability to generate synthetic data on-demand enables researchers and practitioners to explore various data distribution scenarios, test model robustness across different conditions, and conduct comprehensive ablation studies that would be impossible with limited real datasets. This flexibility in data generation empowers more thorough experimentation and validation of machine learning approaches while reducing dependence on expensive and time-consuming real data collection efforts.
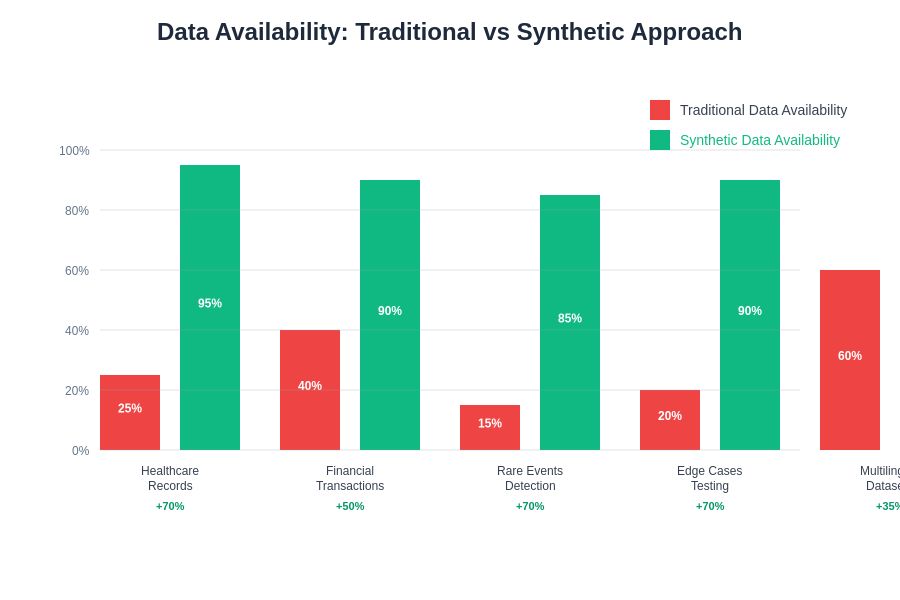
Edge cases and rare events represent particularly challenging aspects of real-world data collection, as these scenarios occur infrequently but often have significant impact on model performance and system reliability. Synthetic data generation enables targeted creation of edge case scenarios and rare event samples, ensuring that machine learning models receive adequate training on critical but uncommon situations that might otherwise be underrepresented in real datasets.
Bias Mitigation and Fairness Enhancement
Real-world datasets often contain various forms of bias that reflect historical inequities, collection limitations, or systematic underrepresentation of certain groups or scenarios. Synthetic data generation provides unique opportunities to address these bias issues by enabling controlled generation of balanced datasets that ensure fair representation across different demographic groups, geographic regions, or other relevant categories that impact model fairness and performance.
The ability to explicitly control the characteristics and distribution of synthetic data enables practitioners to create more equitable training datasets that promote fairness in machine learning model outcomes. This controlled generation capability allows for the deliberate inclusion of underrepresented groups, balanced representation across sensitive attributes, and the creation of counterfactual scenarios that help models learn more robust and unbiased decision-making patterns.
Algorithmic fairness research has increasingly turned to synthetic data generation as a tool for studying bias propagation, testing fairness interventions, and developing more equitable machine learning systems. The controlled nature of synthetic data enables researchers to isolate specific bias factors, study their impact on model behavior, and develop targeted mitigation strategies that improve fairness without compromising overall model performance.
Cost-Effectiveness and Scalability
Traditional data collection, labeling, and preparation processes represent significant cost centers in machine learning projects, often consuming substantial portions of project budgets and development timelines. Synthetic data generation offers compelling cost advantages by eliminating the need for extensive real data collection efforts, reducing labeling costs through automated generation of ground truth annotations, and enabling rapid scaling of dataset sizes without proportional increases in data acquisition expenses.
The scalability advantages of synthetic data become particularly pronounced in applications requiring large-scale datasets or frequent dataset updates. Once generative models are trained and validated, they can produce virtually unlimited quantities of synthetic data at marginal computational costs, enabling organizations to scale their machine learning initiatives without being constrained by data availability or acquisition budgets.
Resource optimization through synthetic data generation extends beyond direct cost savings to include reduced storage requirements, simplified data management workflows, and elimination of complex data sharing agreements and privacy compliance procedures. These operational efficiencies compound the direct cost benefits and enable more agile and responsive machine learning development processes.
Technical Challenges and Limitations
Despite the significant advantages of synthetic data generation, several technical challenges continue to limit its applicability and effectiveness in certain scenarios. Mode collapse in generative models can result in synthetic datasets that lack sufficient diversity, potentially leading to machine learning models that perform well on synthetic data but fail to generalize effectively to real-world conditions and edge cases not adequately represented in the generated samples.
The fidelity-privacy tradeoff represents another fundamental challenge, as efforts to improve the realism and utility of synthetic data may inadvertently increase privacy risks through potential memorization of training data patterns. Balancing these competing objectives requires careful tuning of generation parameters, privacy-preserving training techniques, and rigorous evaluation of both utility and privacy metrics throughout the development process.

Evaluation and validation of synthetic data quality remains an active area of research, as traditional statistical measures may not adequately capture all aspects of data utility for machine learning applications. The development of more comprehensive evaluation frameworks that assess both statistical fidelity and downstream task performance continues to be a critical need for advancing synthetic data generation methodologies and ensuring their effectiveness in real-world applications.
Regulatory and Compliance Considerations
The regulatory landscape surrounding synthetic data generation continues to evolve as policymakers and regulatory bodies grapple with the implications of artificial data creation for privacy protection, data governance, and consumer rights. While synthetic data offers significant privacy advantages, regulatory frameworks must address questions about data provenance, generation methodologies, and the potential for synthetic data to perpetuate or amplify biases present in original training datasets.
Compliance requirements vary significantly across industries and jurisdictions, with some regulatory frameworks explicitly recognizing synthetic data as a privacy-preserving alternative to real data sharing, while others maintain strict requirements for data handling regardless of whether the data is real or artificially generated. Organizations implementing synthetic data solutions must navigate these complex regulatory environments while ensuring their approaches meet applicable privacy and security requirements.
The establishment of industry standards and best practices for synthetic data generation represents an ongoing effort involving regulatory bodies, industry associations, and academic researchers. These standards aim to provide clear guidance on appropriate generation methodologies, quality assessment procedures, and compliance verification processes that ensure synthetic data solutions meet regulatory requirements while delivering effective machine learning outcomes.
Future Directions and Emerging Trends
The future of synthetic data generation is being shaped by rapid advances in generative modeling techniques, including the development of more sophisticated architectures that can handle increasingly complex data types and multi-modal scenarios. Foundation models and large language models are beginning to play significant roles in synthetic data generation, enabling more controllable and high-quality generation processes that can incorporate domain-specific knowledge and constraints.
Federated synthetic data generation represents an emerging paradigm that enables collaborative model training across multiple organizations without requiring direct data sharing. This approach combines the privacy benefits of synthetic data with the collaborative advantages of federated learning, enabling the development of more robust and generalizable machine learning models while maintaining strict data privacy and competitive confidentiality requirements.
The integration of synthetic data generation with automated machine learning and neural architecture search promises to further streamline the machine learning development process by automatically optimizing both data generation parameters and model architectures for specific tasks and performance requirements. This convergence of automated optimization techniques has the potential to democratize access to high-quality machine learning solutions across organizations with varying levels of technical expertise.
Real-World Success Stories and Case Studies
Healthcare organizations have successfully implemented synthetic data generation for medical research, drug discovery, and clinical decision support systems, demonstrating significant improvements in research capabilities while maintaining complete patient privacy. These implementations have enabled breakthrough discoveries in rare disease research, accelerated clinical trial design, and improved diagnostic accuracy through access to larger and more diverse training datasets than would be possible with real patient data alone.
Financial institutions have deployed synthetic data solutions for fraud detection, credit risk assessment, and regulatory stress testing, achieving performance levels comparable to real data while eliminating privacy concerns and enabling more comprehensive model validation across diverse market conditions. These implementations have demonstrated the viability of synthetic data for critical business applications where model accuracy and regulatory compliance are paramount concerns.
Technology companies have leveraged synthetic data generation for computer vision applications, natural language processing systems, and recommendation algorithms, enabling the development of more robust and generalizable AI systems while reducing dependence on user data collection and minimizing privacy risks. These successful deployments have established synthetic data as a viable alternative to traditional data collection approaches across a wide range of commercial applications.
Implementation Best Practices and Guidelines
Successful implementation of synthetic data generation requires careful attention to data quality assessment, validation procedures, and ongoing monitoring of model performance across both synthetic and real data scenarios. Organizations should establish clear quality metrics, validation protocols, and performance benchmarks that ensure synthetic data meets the requirements for specific machine learning applications while maintaining appropriate privacy and security protections.
The selection of appropriate generative modeling techniques should be based on careful analysis of data characteristics, application requirements, and available computational resources. Different generative approaches excel in different scenarios, and optimal selection requires understanding the strengths and limitations of various methodologies in the context of specific use cases and performance requirements.
Stakeholder engagement and change management represent critical success factors for synthetic data implementation, as the adoption of artificial data generation requires buy-in from data scientists, domain experts, regulatory teams, and business stakeholders who may have concerns about data quality, model performance, or compliance implications. Clear communication about benefits, limitations, and validation procedures helps build confidence in synthetic data solutions and ensures successful adoption across organizations.
The evolution of synthetic data generation represents a transformative development in artificial intelligence and machine learning that addresses fundamental challenges in data availability, privacy protection, and development cost-effectiveness. As these technologies continue to mature and regulatory frameworks evolve to accommodate synthetic data solutions, organizations across industries will increasingly rely on artificial data generation to unlock new capabilities, accelerate innovation, and develop more robust and equitable AI systems that benefit society while respecting individual privacy and competitive confidentiality requirements.
Disclaimer
This article is for informational purposes only and does not constitute professional advice regarding data privacy, regulatory compliance, or machine learning implementation strategies. The views expressed are based on current understanding of synthetic data technologies and their applications across various industries. Readers should conduct thorough research, consult with appropriate experts, and consider their specific regulatory and technical requirements when implementing synthetic data generation solutions. The effectiveness and suitability of synthetic data approaches may vary significantly depending on specific use cases, data characteristics, and application requirements.