
The world of deep learning has been fundamentally shaped by two dominant frameworks that have emerged as the primary tools for researchers, data scientists, and machine learning engineers. TensorFlow, developed by Google, and PyTorch, created by Facebook’s AI Research lab, represent two distinct philosophies in deep learning framework design, each offering unique advantages and catering to different aspects of the machine learning development lifecycle. The choice between these frameworks often determines not only the technical approach to implementing machine learning solutions but also influences project timelines, team productivity, and the overall success of AI initiatives.
Understanding the nuanced differences between TensorFlow and PyTorch has become increasingly critical as organizations invest heavily in artificial intelligence capabilities and seek to maximize their return on machine learning investments. Explore the latest AI framework developments to stay informed about emerging trends and updates that could impact your framework selection decision. The complexity of modern machine learning projects demands careful consideration of framework capabilities, ecosystem support, and long-term viability to ensure successful project outcomes and sustainable development practices.
Historical Context and Development Philosophy
TensorFlow emerged from Google’s internal machine learning infrastructure needs, building upon the lessons learned from their earlier DistBelief system. Released as an open-source project in 2015, TensorFlow was designed with production deployment and scalability as primary concerns, reflecting Google’s need to serve machine learning models at massive scale across their various products and services. This production-first mentality influenced many of TensorFlow’s architectural decisions, including its static computation graph approach and emphasis on optimization for deployment scenarios.
PyTorch, on the other hand, evolved from the Torch library and was officially released by Facebook in 2017 with a fundamentally different philosophy centered around research flexibility and ease of use. The framework was designed to provide an intuitive, Pythonic interface that would feel natural to researchers and developers coming from traditional programming backgrounds. This research-first approach prioritized dynamic computation graphs, immediate execution, and debugging capabilities that would accelerate the research and experimentation process.
The philosophical differences between these frameworks have profound implications for how they handle various aspects of machine learning development, from model definition and training to deployment and production serving. These foundational differences continue to influence the evolution of both frameworks and shape the types of projects and use cases where each excels.
Ease of Use and Learning Curve
The learning curve associated with each framework represents one of the most significant factors in framework selection, particularly for teams new to deep learning or organizations looking to minimize onboarding time for new developers. PyTorch has consistently been praised for its intuitive design and Pythonic approach to deep learning, making it exceptionally accessible to developers with traditional programming backgrounds who are transitioning into machine learning development.
PyTorch’s dynamic computation graph allows developers to write and debug their models using familiar programming paradigms, including standard Python debugging tools, print statements, and interactive development environments. This approach significantly reduces the cognitive overhead associated with learning deep learning concepts while simultaneously managing framework-specific abstractions and limitations.
TensorFlow’s evolution has addressed many early usability concerns, particularly with the introduction of TensorFlow 2.0 and its emphasis on eager execution by default. The modern TensorFlow experience is substantially more user-friendly than its predecessor, incorporating Keras as the high-level API and providing more intuitive model building patterns. However, the framework’s extensive feature set and multiple abstraction levels can still present a steeper learning curve for newcomers to the ecosystem.
Enhance your AI development skills with Claude to accelerate your understanding of complex framework concepts and implementation patterns. The choice between frameworks often comes down to team expertise, project requirements, and the specific machine learning domains being addressed, making it essential to evaluate learning curve implications in the context of your specific organizational needs.
Performance and Scalability Considerations
Performance characteristics differ significantly between TensorFlow and PyTorch, with each framework optimized for different aspects of the machine learning pipeline. TensorFlow’s static graph approach, while initially more complex to work with, provides substantial advantages for production deployment scenarios where model optimization, quantization, and efficient serving are critical requirements. The framework’s compilation and optimization capabilities enable aggressive performance optimizations that can result in significantly faster inference times and reduced memory consumption in production environments.
PyTorch’s dynamic graph approach prioritizes development speed and debugging capabilities, which can come at the cost of runtime performance in certain scenarios. However, recent developments including TorchScript and the introduction of compilation features have substantially narrowed the performance gap between the frameworks. PyTorch’s approach to just-in-time compilation and graph optimization has evolved to provide near-TensorFlow performance levels while maintaining the framework’s signature ease of use and flexibility.
Scalability considerations extend beyond raw performance to include distributed training capabilities, multi-GPU support, and integration with cloud-based training infrastructure. TensorFlow’s mature ecosystem includes robust distributed training solutions, comprehensive support for various hardware accelerators, and seamless integration with Google Cloud Platform services. PyTorch has rapidly evolved its distributed training capabilities and now offers competitive solutions for large-scale training scenarios, though the ecosystem around these capabilities continues to mature.
Ecosystem and Community Support
The ecosystem surrounding each framework represents a critical factor in long-term project success, encompassing everything from third-party library availability to community support and educational resources. TensorFlow benefits from Google’s extensive investment in the ecosystem, including TensorFlow Extended (TFX) for production machine learning pipelines, TensorFlow Lite for mobile deployment, TensorFlow.js for web-based machine learning, and TensorFlow Serving for model deployment at scale.
PyTorch’s ecosystem has grown rapidly, driven by strong adoption in the research community and increasing enterprise interest. The framework benefits from Facebook’s investment in production tools like TorchServe for model serving, PyTorch Lightning for research organization, and extensive integration with popular data science tools and libraries. The research community’s preference for PyTorch has resulted in rapid implementation of cutting-edge techniques and algorithms, often appearing in PyTorch before being ported to other frameworks.
The community aspects of framework selection cannot be understated, as they directly impact the availability of tutorials, troubleshooting resources, and pre-trained models. TensorFlow’s longer market presence has resulted in extensive documentation, comprehensive tutorials, and a vast collection of pre-trained models through TensorFlow Hub. PyTorch’s growing popularity has generated substantial community-driven content, though the ecosystem is still catching up to TensorFlow’s breadth in certain areas.
Model Development and Prototyping
The model development experience differs substantially between frameworks, influencing how quickly teams can iterate on ideas and experiment with different architectural approaches. PyTorch’s dynamic graph approach provides immediate feedback during model development, allowing developers to inspect intermediate results, modify network architectures on the fly, and use standard Python debugging techniques throughout the development process.
This flexibility proves particularly valuable during the research and prototyping phases where rapid experimentation and architectural modifications are common. PyTorch’s approach enables natural integration with existing Python workflows and data processing pipelines, reducing the friction associated with moving between data preprocessing, model development, and evaluation phases.
TensorFlow’s approach to model development has evolved significantly with version 2.0, incorporating eager execution by default and providing more intuitive model building patterns through the Keras API. The framework now supports both dynamic and static graph approaches, allowing developers to choose the most appropriate paradigm for their specific use case while maintaining compatibility with TensorFlow’s extensive production deployment capabilities.
Leverage advanced AI research tools with Perplexity to stay current with the latest developments in deep learning architectures and implementation techniques across both frameworks. The choice between frameworks for prototyping often depends on team preferences, existing workflows, and the specific types of models being developed.
Production Deployment and MLOps
Production deployment represents one of the most critical differentiators between TensorFlow and PyTorch, with significant implications for model serving, monitoring, and lifecycle management. TensorFlow’s production-first design philosophy has resulted in mature, battle-tested deployment solutions that have been proven at massive scale across Google’s various products and services.
TensorFlow Serving provides robust model serving capabilities with features like model versioning, A/B testing, and automatic batching that are essential for production machine learning systems. The framework’s integration with TensorFlow Extended (TFX) enables comprehensive MLOps pipelines that handle everything from data validation and model training to deployment and monitoring in production environments.
PyTorch’s production deployment story has evolved rapidly, with TorchServe providing model serving capabilities and growing integration with popular MLOps platforms and cloud services. The framework’s dynamic nature, while advantageous for development, historically presented challenges for production deployment that required additional tooling and optimization steps to achieve TensorFlow-level performance and reliability.
Modern PyTorch deployment approaches leverage TorchScript for model compilation and optimization, enabling production-ready deployments that can compete with TensorFlow in many scenarios. However, the ecosystem around PyTorch production deployment continues to mature, and organizations with heavy production requirements may still find TensorFlow’s established toolchain more comprehensive.
Research and Innovation Adoption
The research community’s framework preferences significantly influence the availability of cutting-edge techniques and the speed at which new developments become accessible to practitioners. PyTorch has become the dominant framework in academic research, with the majority of recent breakthrough papers providing PyTorch implementations as their primary or only framework option.
This research preference has resulted in PyTorch implementations of state-of-the-art techniques becoming available more quickly, often directly from the original researchers. The framework’s design philosophy aligns well with the experimental nature of research, providing the flexibility needed to implement novel architectures and training procedures without framework limitations constraining creativity.
TensorFlow’s research adoption has remained strong, particularly in areas where Google Research is active, but the broader academic community has shown a clear preference for PyTorch’s development experience. This trend has implications for organizations looking to implement the latest research findings, as PyTorch implementations are often available sooner and may be more directly usable.
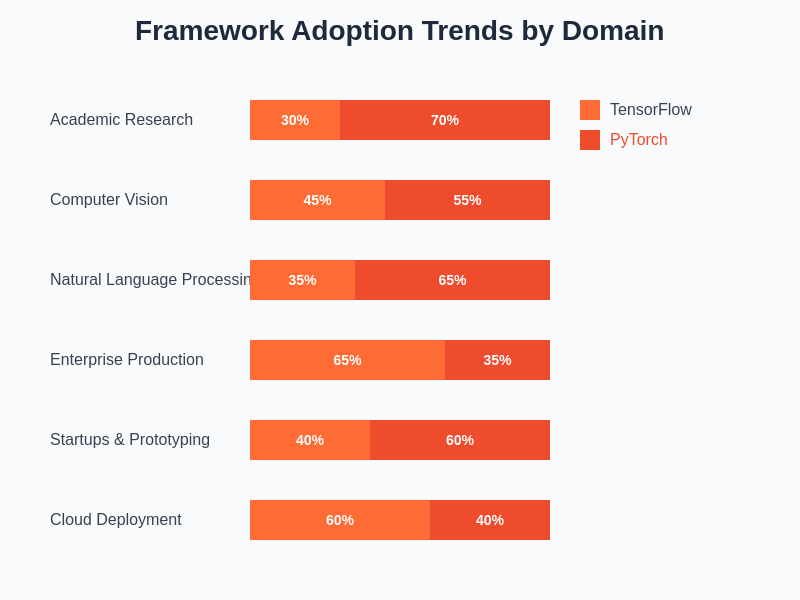
The shifting landscape of framework adoption reflects the different priorities and use cases that drive framework selection in various contexts. Research institutions gravitate toward PyTorch’s flexibility and ease of use, while enterprise organizations often prioritize TensorFlow’s production capabilities and comprehensive ecosystem support.
Industry Applications and Use Cases
Different industries and application domains have shown preferences for specific frameworks based on their particular requirements and constraints. Computer vision applications have seen strong adoption of both frameworks, with PyTorch gaining significant traction in research and development phases while TensorFlow maintains strength in production computer vision systems requiring high throughput and optimization.
Natural language processing has witnessed particularly strong PyTorch adoption, driven by the research community’s preference for the framework and the availability of cutting-edge transformer implementations. Libraries like Hugging Face Transformers have made PyTorch the de facto standard for many NLP applications, though TensorFlow implementations are also widely available and used in production systems.
Enterprise applications requiring extensive integration with existing infrastructure, strict performance requirements, and comprehensive deployment tooling often favor TensorFlow’s mature ecosystem. The framework’s long-standing presence in production environments has resulted in extensive integration options and proven scalability across diverse deployment scenarios.

The distribution of framework usage across different application domains reflects the unique strengths and evolutionary paths of each framework. Understanding these patterns can inform framework selection decisions based on specific project requirements and industry contexts.
Performance Benchmarking and Optimization
Objective performance comparisons between TensorFlow and PyTorch reveal nuanced differences that depend heavily on specific use cases, model architectures, and deployment scenarios. Training performance comparisons show PyTorch and TensorFlow achieving similar results in most scenarios, with variations often attributable to implementation differences rather than fundamental framework limitations.
Inference performance presents more significant variations, with TensorFlow’s static graph optimizations and mature deployment tooling often providing advantages in production serving scenarios. However, PyTorch’s TorchScript compilation and recent optimization improvements have substantially closed this gap, particularly for newer model architectures and deployment patterns.
Memory efficiency represents another critical performance dimension where framework differences can have significant practical implications. TensorFlow’s static graph approach can enable more aggressive memory optimization, while PyTorch’s dynamic graphs may require additional memory for gradient computation and intermediate result storage.
Hardware acceleration support differs between frameworks, with both providing comprehensive GPU support but varying in their optimization for specific accelerator types and deployment scenarios. TensorFlow’s longer development history has resulted in mature optimization for various hardware platforms, while PyTorch’s rapidly evolving hardware support continues to expand and improve.
Framework Migration and Interoperability
Organizations evaluating framework choices must consider the long-term implications of their decisions, including potential migration paths and interoperability requirements. Converting models between TensorFlow and PyTorch requires significant effort due to fundamental architectural differences, making initial framework selection a critical long-term decision.
Model conversion tools and libraries have emerged to facilitate framework migration, though the process remains complex and often requires manual verification and optimization. ONNX (Open Neural Network Exchange) provides a standardized format for model representation that can facilitate framework interoperability, though support and compatibility vary across different model types and architectures.
The cost and complexity of framework migration often make it prohibitive for established projects, emphasizing the importance of careful initial framework selection based on comprehensive evaluation of project requirements, team capabilities, and long-term organizational needs.
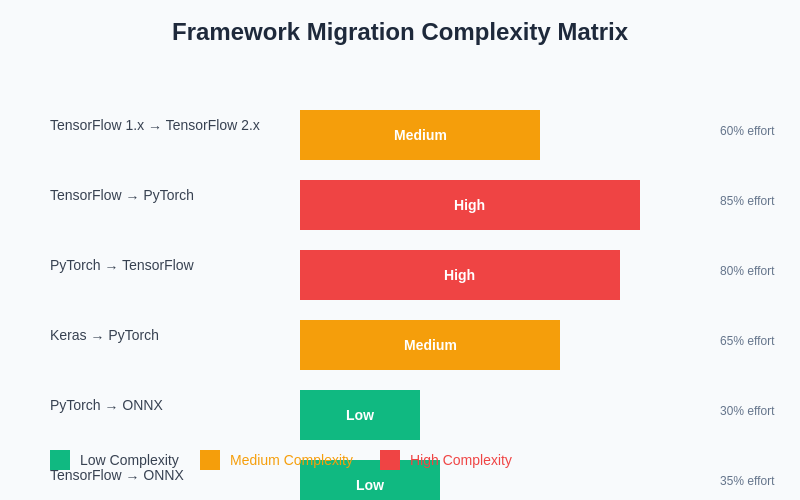
The complexity of migrating between frameworks varies significantly based on model architecture, deployment requirements, and ecosystem dependencies. Understanding these migration challenges can inform initial framework selection and long-term strategic planning for machine learning initiatives.
Future Outlook and Strategic Considerations
The competitive landscape between TensorFlow and PyTorch continues to evolve rapidly, with both frameworks incorporating features and capabilities inspired by their competition. TensorFlow’s move toward eager execution and improved usability directly addresses PyTorch’s traditional advantages, while PyTorch’s focus on production deployment capabilities responds to TensorFlow’s historical strengths.
Recent developments suggest continued convergence between the frameworks in terms of core capabilities, with differentiation increasingly focused on ecosystem features, specific use case optimizations, and integration capabilities. This convergence reduces the risk associated with framework selection while enabling organizations to focus on their specific requirements rather than fundamental framework limitations.
The machine learning landscape’s rapid evolution introduces new considerations including emerging hardware platforms, novel training paradigms, and evolving deployment patterns that will influence framework development priorities. Organizations must consider not only current framework capabilities but also the strategic direction and investment priorities of the frameworks’ maintainers.
Long-term strategic considerations include vendor relationships, open-source sustainability, and community ecosystem health, all of which can significantly impact the long-term viability and success of machine learning initiatives built on these frameworks.
Making the Right Choice for Your Organization
Framework selection should be driven by a comprehensive evaluation of organizational needs, project requirements, and team capabilities rather than abstract performance comparisons or popularity metrics. Organizations with strong research components or rapid prototyping requirements may find PyTorch’s development experience and research community support more aligned with their needs.
Enterprises with extensive production deployment requirements, complex infrastructure integration needs, or stringent performance requirements may benefit from TensorFlow’s mature production ecosystem and proven scalability. However, the gap between frameworks continues to narrow, making specific project requirements and team expertise increasingly important factors in the decision process.
Team expertise and existing infrastructure represent practical considerations that can significantly influence framework selection effectiveness. Organizations with existing PyTorch expertise may achieve better results by leveraging that knowledge rather than switching to TensorFlow for theoretical advantages that may not materialize in their specific context.
The decision should also consider the broader organizational machine learning strategy, including plans for model deployment, monitoring, and lifecycle management. Framework selection impacts not only immediate development productivity but also long-term maintenance costs, scalability potential, and integration capabilities with existing systems and workflows.
Conclusion
The choice between TensorFlow and PyTorch reflects a decision between two mature, capable frameworks that have evolved to address different aspects of the machine learning development lifecycle. PyTorch’s strength in research, prototyping, and development experience makes it an excellent choice for organizations prioritizing innovation, rapid experimentation, and ease of use. TensorFlow’s comprehensive production ecosystem, deployment capabilities, and proven scalability make it well-suited for enterprise applications requiring robust production deployment and extensive ecosystem integration.
Modern machine learning projects benefit from either framework choice, as both have evolved to address their historical limitations while maintaining their core strengths. The decision should be based on specific organizational needs, team capabilities, and project requirements rather than attempting to identify a universally superior option.
Success with either framework depends more on effective implementation, appropriate architecture choices, and comprehensive understanding of the chosen framework’s capabilities and limitations than on the framework selection itself. Organizations focusing on building strong machine learning capabilities and expertise will find success with either TensorFlow or PyTorch when the choice is aligned with their specific context and requirements.
Disclaimer
This article provides general information about TensorFlow and PyTorch frameworks for educational purposes. Framework capabilities, performance characteristics, and ecosystem features evolve rapidly, and readers should verify current framework status and capabilities before making decisions. The effectiveness of either framework depends on specific use cases, implementation quality, and organizational context. Performance comparisons may vary based on hardware, model architecture, and optimization techniques employed.