
The convergence of machine learning and embedded systems has reached a pivotal moment with the emergence of TinyML, a revolutionary approach that brings artificial intelligence capabilities directly to microcontrollers and Internet of Things devices. This transformative technology represents a fundamental shift in how we conceive and deploy machine learning applications, moving intelligence from centralized cloud servers to the very edge of our connected world where data is generated and decisions must be made in real-time.
Explore the latest AI developments and trends to understand how TinyML fits into the broader artificial intelligence ecosystem and its impact on future technology implementations. The democratization of machine learning through TinyML has opened unprecedented opportunities for creating intelligent, autonomous devices that can operate independently while consuming minimal power and computational resources.
The Foundation of TinyML Technology
TinyML represents the intersection of embedded systems engineering and machine learning optimization, focusing on implementing neural networks and other ML algorithms on devices with severe constraints in memory, processing power, and energy consumption. Unlike traditional machine learning deployments that rely on powerful servers with gigabytes of RAM and high-performance processors, TinyML operates within the confines of microcontrollers that typically possess kilobytes of memory and operate at frequencies measured in megahertz rather than gigahertz.
The technological breakthrough that enables TinyML lies in advanced model compression techniques, quantization methods, and specialized neural network architectures designed specifically for resource-constrained environments. These innovations have made it possible to deploy sophisticated machine learning models on devices that cost mere dollars while consuming power measured in milliwatts, opening entirely new categories of applications that were previously impossible due to connectivity, latency, or power requirements.
The fundamental principles governing TinyML development revolve around extreme optimization and efficient resource utilization. Every aspect of the machine learning pipeline, from data preprocessing and feature extraction to model inference and result interpretation, must be carefully engineered to operate within tight constraints while maintaining acceptable accuracy and performance levels. This optimization process often requires innovative approaches to algorithm design, memory management, and computational efficiency that push the boundaries of what is possible with limited hardware resources.
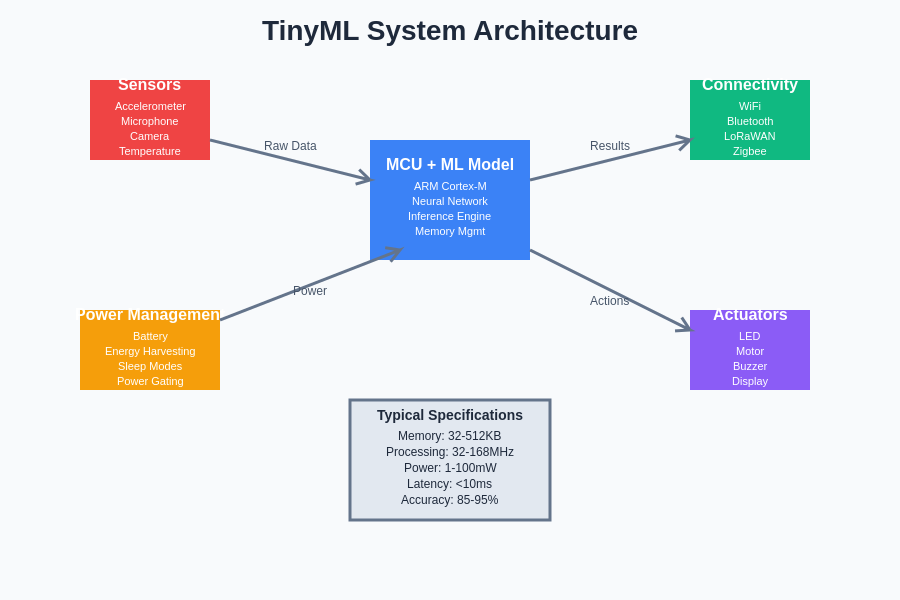
The comprehensive architecture of TinyML systems demonstrates the intricate integration between sensors, processing units, connectivity modules, and power management components that work together to deliver intelligent edge computing capabilities within severely constrained hardware environments.
Microcontroller Platforms and Hardware Enablers
The hardware landscape for TinyML has evolved rapidly, with numerous microcontroller platforms emerging as viable hosts for machine learning workloads. Popular platforms such as Arduino Nano 33 BLE Sense, ESP32, STM32 series, and specialized chips like the Nordic nRF52840 provide the computational foundation necessary for TinyML implementations. These platforms typically feature ARM Cortex-M processors, integrated sensors, wireless connectivity options, and memory configurations optimized for embedded applications.
The selection of appropriate hardware platforms for TinyML applications requires careful consideration of multiple factors including computational requirements, power consumption constraints, sensor integration needs, and connectivity options. Modern microcontrollers designed for TinyML applications often include hardware accelerators for common machine learning operations, specialized memory architectures for efficient data access, and low-power modes that enable extended battery operation in remote deployments.
Discover advanced AI tools and platforms with Claude that can assist in developing and optimizing TinyML applications for various microcontroller platforms and use cases. The integration between development tools and target hardware has become increasingly seamless, enabling developers to prototype, train, and deploy machine learning models with unprecedented efficiency and reliability.
Model Optimization and Compression Techniques
The deployment of machine learning models on microcontrollers necessitates sophisticated optimization and compression techniques that can dramatically reduce model size and computational requirements while preserving essential functionality. Quantization represents one of the most effective approaches, converting floating-point model parameters to lower-precision representations such as 8-bit or even 1-bit integers, resulting in significant reductions in memory usage and computational complexity.
Pruning techniques selectively remove less important neural network connections and parameters, creating sparse models that maintain accuracy while requiring fewer computational resources. Knowledge distillation enables the creation of smaller student models that learn from larger teacher models, capturing essential behavioral patterns in more compact representations suitable for microcontroller deployment. These optimization techniques often work synergistically, with combinations of quantization, pruning, and distillation achieving remarkable compression ratios while maintaining acceptable performance levels.
Advanced compression techniques such as weight sharing, Huffman encoding, and architectural optimization through neural architecture search have further pushed the boundaries of what is achievable on resource-constrained devices. The development of specialized frameworks and tools for TinyML model optimization has made these advanced techniques accessible to developers without deep expertise in neural network compression, democratizing the deployment of machine learning on embedded systems.
Real-World Applications and Use Cases
TinyML applications span an impressive range of domains, from industrial monitoring and predictive maintenance to consumer electronics and environmental sensing. Smart agriculture implementations use TinyML-enabled sensors to monitor soil conditions, detect plant diseases, and optimize irrigation systems without requiring constant connectivity to cloud services. Industrial IoT applications leverage TinyML for real-time anomaly detection in machinery, enabling predictive maintenance strategies that prevent costly equipment failures.
Healthcare applications represent a particularly promising area for TinyML deployment, with wearable devices capable of continuous health monitoring, early warning systems for medical emergencies, and personalized health insights generated directly on the device. The privacy advantages of on-device processing make TinyML particularly attractive for healthcare applications where sensitive personal data must be protected while still enabling sophisticated analysis and decision-making capabilities.
Environmental monitoring applications utilize networks of TinyML-enabled sensors to track air quality, detect pollution events, monitor wildlife behavior, and assess climate conditions in remote locations. The ability to deploy intelligent sensors that can operate autonomously for months or years on battery power has revolutionized environmental research and monitoring capabilities, enabling data collection in previously inaccessible locations and situations.
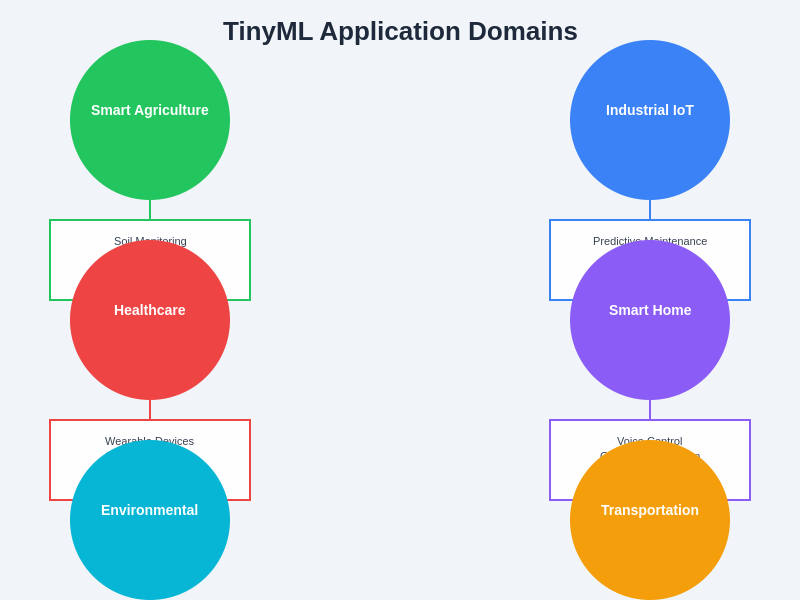
The diverse application landscape for TinyML technology spans multiple industries and use cases, from smart agriculture and industrial monitoring to healthcare and environmental sensing, demonstrating the versatility and broad applicability of machine learning at the edge of connected systems.
Development Frameworks and Tools
The TinyML development ecosystem has matured significantly with the emergence of specialized frameworks and tools designed specifically for embedded machine learning applications. TensorFlow Lite for Microcontrollers provides a comprehensive platform for deploying TensorFlow models on microcontrollers, offering optimized runtime libraries and development tools tailored for resource-constrained environments. Edge Impulse has emerged as a popular cloud-based platform that simplifies the entire TinyML development pipeline from data collection and model training to deployment and monitoring.
Arduino and other microcontroller development environments have integrated TinyML libraries and examples, making machine learning accessible to the broader embedded systems community. These development tools often include automated model optimization features, hardware-specific compilation options, and debugging capabilities that streamline the development process while ensuring optimal performance on target devices.
The integration of machine learning model development with traditional embedded systems development workflows has been facilitated by tools that bridge the gap between data science and embedded programming. These tools enable seamless transitions from model prototyping in familiar environments like Python and Jupyter notebooks to optimized implementations running on microcontrollers with minimal manual intervention.
Power Efficiency and Battery Life Optimization
Power consumption represents one of the most critical considerations in TinyML applications, particularly for battery-powered devices that must operate for extended periods without maintenance. The energy efficiency of TinyML implementations depends on careful optimization of both hardware utilization and algorithmic efficiency, with successful deployments often achieving power consumption levels measured in microwatts during inference operations.
Dynamic power management techniques enable TinyML devices to minimize energy consumption by selectively activating computational resources only when needed, utilizing sleep modes during inactive periods, and optimizing sensor sampling rates based on environmental conditions and application requirements. The design of energy-efficient TinyML systems often involves trade-offs between model accuracy, inference frequency, and power consumption that must be carefully balanced based on specific application requirements.
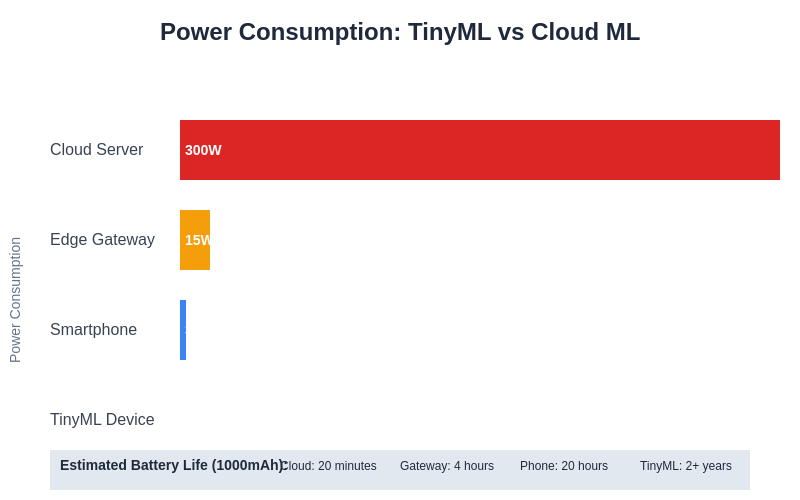
The dramatic power efficiency advantages of TinyML devices become evident when compared to traditional cloud-based machine learning deployments, with TinyML implementations consuming several orders of magnitude less power while enabling extended battery operation and sustainable deployment in remote locations.
Explore comprehensive AI research tools with Perplexity to stay updated on the latest advances in power-efficient machine learning algorithms and hardware optimizations for embedded systems. The ongoing research in ultra-low-power machine learning continues to push the boundaries of what is possible with battery-powered intelligent devices, enabling new applications and deployment scenarios previously considered impractical.
Security and Privacy Considerations
TinyML implementations offer inherent security and privacy advantages by processing data locally on devices rather than transmitting sensitive information to cloud servers. This edge-based approach reduces exposure to network-based attacks, eliminates concerns about data transmission privacy, and enables operation in environments with limited or unreliable connectivity. However, TinyML systems also face unique security challenges related to physical device access, firmware protection, and model intellectual property protection.
The implementation of security measures in TinyML systems must balance protection requirements with the severe resource constraints inherent in microcontroller platforms. Lightweight encryption schemes, secure boot processes, and hardware-based security features are often employed to protect both data and model parameters while maintaining the efficiency advantages that make TinyML deployment feasible.
Model extraction and reverse engineering represent emerging security concerns in TinyML deployments, where attackers might attempt to extract valuable machine learning models from deployed devices. Defense mechanisms such as model obfuscation, differential privacy techniques, and hardware-based protection schemes are being developed to address these threats while preserving the functional advantages of edge-based machine learning.
Performance Optimization and Benchmarking
The performance characteristics of TinyML implementations require specialized evaluation methodologies that consider not only traditional machine learning metrics such as accuracy and precision but also embedded systems considerations including inference latency, energy consumption, memory utilization, and real-time performance constraints. Benchmarking TinyML systems often involves comprehensive testing across diverse operating conditions, temperature ranges, and power supply variations that reflect real-world deployment scenarios.
Optimization of TinyML performance typically involves iterative refinement of model architectures, implementation techniques, and hardware configurations to achieve optimal trade-offs between accuracy and efficiency. Profiling tools and performance analysis frameworks specifically designed for embedded systems enable developers to identify bottlenecks, optimize critical code paths, and validate performance requirements before deployment.
The establishment of standardized benchmarks and evaluation methodologies for TinyML systems has become increasingly important as the field matures and commercial applications proliferate. These benchmarks help ensure consistent performance comparisons across different platforms, enable fair evaluation of optimization techniques, and provide guidance for selecting appropriate solutions for specific application requirements.
Integration with IoT Ecosystems
TinyML devices rarely operate in isolation but instead function as intelligent nodes within broader Internet of Things ecosystems that may include cloud services, edge gateways, and other connected devices. The integration of TinyML capabilities with existing IoT infrastructure requires careful consideration of communication protocols, data synchronization strategies, and system-wide coordination mechanisms that leverage the unique capabilities of edge-based intelligence.
The hybrid architectures that combine TinyML edge processing with cloud-based analytics and coordination services offer compelling advantages including reduced bandwidth requirements, improved system resilience, and enhanced privacy protection. These architectures enable sophisticated applications that leverage the strengths of both edge and cloud computing while mitigating the limitations of each approach through intelligent task distribution and resource allocation strategies.
Communication protocols and data formats optimized for TinyML applications must balance the need for efficient information exchange with the constraints of low-power wireless connectivity options commonly used in embedded systems. Standards and protocols specifically designed for TinyML ecosystems are emerging to facilitate interoperability and enable seamless integration with existing IoT infrastructure and cloud services.
Challenges and Limitations
Despite the remarkable progress in TinyML technology, significant challenges and limitations continue to constrain the scope and effectiveness of embedded machine learning applications. Memory constraints remain a fundamental limitation, with many sophisticated machine learning models requiring more storage and working memory than is available on typical microcontroller platforms. The trade-offs between model complexity and hardware constraints often result in reduced accuracy or limited functionality compared to cloud-based implementations.
Model updating and maintenance in deployed TinyML systems present unique challenges, particularly for devices deployed in remote or inaccessible locations where physical access for updates is impractical. Over-the-air update mechanisms must be carefully designed to work within the constraints of low-power wireless connectivity while ensuring system security and reliability during update processes.
The debugging and validation of TinyML systems require specialized tools and methodologies that can operate within the constraints of embedded systems while providing sufficient visibility into model behavior and system performance. Traditional machine learning development and debugging approaches often cannot be directly applied to TinyML systems due to resource constraints and real-time operational requirements.
Future Trends and Technological Evolution
The future evolution of TinyML technology is being shaped by advances in multiple complementary areas including neural network architecture research, semiconductor technology improvements, and specialized hardware accelerators designed specifically for embedded machine learning workloads. Emerging neural network architectures such as transformer variants optimized for edge deployment and novel training techniques that produce more efficient models are expanding the capabilities of TinyML systems.
Hardware trends including the integration of dedicated neural processing units into microcontroller designs, advances in memory technology that provide higher density and lower power consumption, and improvements in sensor integration are creating new possibilities for TinyML applications. The convergence of these hardware advances with algorithmic improvements is enabling increasingly sophisticated machine learning capabilities on progressively smaller and more energy-efficient platforms.
The standardization and commercialization of TinyML technologies are accelerating the adoption and deployment of embedded machine learning solutions across numerous industries and applications. The development of specialized development tools, comprehensive software frameworks, and commercial support infrastructure is reducing the barriers to TinyML adoption and enabling broader participation in the embedded machine learning ecosystem.
Industry Applications and Commercial Deployment
Commercial deployment of TinyML technology has accelerated across diverse industries, with applications ranging from smart manufacturing and industrial automation to consumer electronics and automotive systems. Manufacturing applications leverage TinyML for quality control, predictive maintenance, and process optimization, enabling real-time decision-making that improves efficiency and reduces operational costs while maintaining high quality standards.
Consumer electronics applications increasingly incorporate TinyML capabilities for features such as voice recognition, gesture control, health monitoring, and personalized user experiences that operate entirely on-device without requiring cloud connectivity. The integration of TinyML into everyday consumer products is creating new categories of intelligent devices that can adapt to user behavior and preferences while protecting privacy through on-device processing.
Automotive applications represent a rapidly growing segment for TinyML deployment, with implementations including driver monitoring systems, predictive maintenance for vehicle components, and intelligent sensor fusion for advanced driver assistance systems. The reliability and real-time performance requirements of automotive applications are driving advances in TinyML robustness and deterministic behavior that benefit the broader embedded machine learning ecosystem.
The commercial success and widespread adoption of TinyML technology demonstrate the maturation of embedded machine learning from research curiosity to practical solution for real-world challenges. The ongoing expansion of TinyML applications across industries continues to drive innovation and investment in the underlying technologies, creating a positive feedback loop that accelerates further development and adoption of intelligent edge computing solutions.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The information presented reflects current understanding of TinyML technologies and their applications in embedded systems. Readers should conduct their own research and consider their specific technical requirements, constraints, and use cases when evaluating TinyML solutions. The effectiveness and suitability of TinyML implementations may vary significantly depending on hardware platforms, application requirements, and deployment conditions. Performance characteristics and capabilities described may not be achievable in all scenarios or with all hardware configurations.