
The relentless pursuit of computational efficiency in machine learning has driven developers to push the boundaries of GPU performance optimization, leading to a fascinating evolution in kernel development paradigms. At the heart of this transformation lies a compelling comparison between two distinct approaches: NVIDIA’s mature CUDA ecosystem and the emerging Triton framework developed by OpenAI. This technological rivalry represents more than just competing programming models; it embodies fundamentally different philosophies about how developers should interact with GPU hardware to achieve optimal performance in machine learning workloads.
Explore the latest developments in AI and GPU computing to understand how these technologies are shaping the future of high-performance machine learning applications. The choice between Triton and CUDA has become increasingly critical as machine learning models grow in complexity and computational requirements, demanding sophisticated optimization strategies that can extract maximum performance from modern GPU architectures while maintaining developer productivity and code maintainability.
Understanding the GPU Kernel Optimization Landscape
The world of GPU kernel optimization has traditionally been dominated by CUDA, NVIDIA’s comprehensive parallel computing platform that has served as the foundation for accelerated computing across numerous domains. CUDA’s extensive ecosystem includes libraries, development tools, and a mature programming model that has enabled developers to harness GPU parallelism for over a decade. However, the complexity of CUDA kernel development, particularly for machine learning applications, has created barriers that limit accessibility and increase development time for many practitioners.
The emergence of Triton represents a paradigm shift toward higher-level abstraction without sacrificing performance. Developed specifically with machine learning workloads in mind, Triton aims to democratize GPU kernel development by providing a Python-based domain-specific language that automatically handles many low-level optimization details. This approach promises to make GPU kernel optimization more accessible while maintaining the performance characteristics essential for modern machine learning applications.
The fundamental distinction between these approaches lies in their design philosophy: CUDA offers maximum control and flexibility at the cost of complexity, while Triton prioritizes ease of use and rapid development while attempting to match CUDA’s performance through intelligent compiler optimizations. Understanding this trade-off is crucial for making informed decisions about which approach best suits specific machine learning optimization requirements.
CUDA: The Established Foundation
CUDA has established itself as the gold standard for GPU computing through years of continuous development and refinement. The platform provides developers with direct access to GPU hardware features, enabling precise control over memory management, thread synchronization, and execution patterns. This level of control has made CUDA the preferred choice for performance-critical applications where every microsecond of execution time matters and where developers are willing to invest significant effort in optimization.
The strength of CUDA lies in its comprehensive ecosystem that extends far beyond kernel development. Libraries such as cuBLAS, cuDNN, and cuSPARSE provide highly optimized implementations of common mathematical operations, while development tools like Nsight Systems and Nsight Compute offer sophisticated profiling and debugging capabilities. This mature ecosystem has enabled countless breakthroughs in machine learning, scientific computing, and high-performance applications across diverse industries.
However, CUDA’s power comes with inherent complexity that can be overwhelming for developers who are not specialists in GPU programming. Writing efficient CUDA kernels requires deep understanding of GPU architecture, memory hierarchies, and parallel programming patterns. The learning curve is steep, and even experienced developers can spend considerable time optimizing kernels to achieve peak performance. This complexity has created a barrier that limits the number of developers who can effectively leverage GPU acceleration for their machine learning workloads.
Discover advanced AI development tools like Claude that can assist with complex GPU programming tasks and optimization strategies. The integration of AI-powered development assistance has become increasingly valuable for navigating the complexities of GPU kernel optimization and accelerating the development process.
Triton: The Modern Alternative
Triton emerged from OpenAI’s research efforts as a response to the accessibility challenges inherent in CUDA development. The framework introduces a Python-based domain-specific language that allows developers to write GPU kernels using familiar syntax while the Triton compiler automatically handles low-level optimizations. This approach significantly reduces the barrier to entry for GPU kernel development while attempting to maintain performance parity with hand-optimized CUDA code.
The core innovation of Triton lies in its ability to automatically generate efficient GPU code from high-level descriptions of computational patterns. The framework handles complex optimization tasks such as memory coalescing, shared memory utilization, and thread block configuration without requiring explicit developer intervention. This automation enables machine learning researchers and developers to focus on algorithmic innovation rather than GPU programming intricacies.
Triton’s design philosophy emphasizes rapid prototyping and experimentation, making it particularly well-suited for research environments where quick iteration and exploration of different approaches are essential. The framework’s integration with PyTorch has made it especially popular among deep learning practitioners who can seamlessly incorporate custom kernels into their existing workflows without mastering traditional GPU programming paradigms.
Performance Characteristics and Benchmarking
The performance comparison between Triton and CUDA reveals nuanced trade-offs that depend heavily on specific use cases and implementation details. In many scenarios, well-written Triton kernels can achieve performance within 5-15% of highly optimized CUDA implementations, which represents a remarkable achievement considering the significant reduction in development complexity. However, this performance gap can become more pronounced in specialized scenarios that require fine-grained control over GPU resources or unconventional memory access patterns.
CUDA’s performance advantages are most evident in scenarios that benefit from manual optimization of memory access patterns, custom synchronization strategies, or hardware-specific features that are not automatically exploited by Triton’s compiler. Experienced CUDA developers can often achieve superior performance by leveraging deep knowledge of GPU architecture and implementing optimizations that are difficult to automate. These advantages are particularly noticeable in applications with irregular memory access patterns or complex control flow that challenges automatic optimization approaches.
Triton’s strength lies in achieving consistently good performance across a wide range of common machine learning operations without requiring specialized expertise. The framework’s compiler can automatically apply many optimization techniques that would require significant manual effort in CUDA, resulting in faster development cycles and more maintainable code. For many machine learning workloads, this combination of good performance and development efficiency represents an optimal balance.
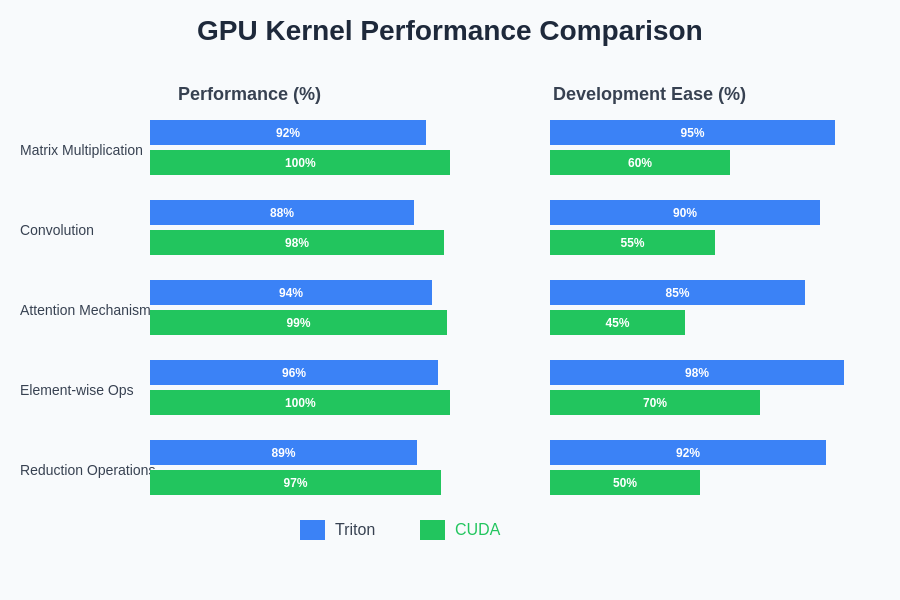
The performance characteristics of different kernel optimization approaches reveal distinct advantages depending on specific computational patterns and optimization requirements. Understanding these performance profiles is essential for making informed decisions about technology selection for machine learning workloads.
Development Experience and Productivity
The developer experience represents one of the most significant differentiating factors between Triton and CUDA. Traditional CUDA development requires mastery of C++ programming, GPU architecture concepts, and parallel programming patterns that can take months or years to fully understand. The debugging process can be particularly challenging, as GPU-specific issues often manifest in subtle ways that are difficult to diagnose without specialized tools and expertise.
Triton dramatically simplifies the development experience by providing a Python-based interface that leverages familiar programming concepts and idioms. Developers can write, test, and debug GPU kernels using standard Python development tools and workflows, significantly reducing the learning curve and development time. The framework’s integration with existing Python ecosystems means that developers can seamlessly incorporate GPU acceleration into their machine learning pipelines without context switching between different programming environments.
The productivity gains from Triton are particularly pronounced for iterative development and experimentation. Researchers can rapidly prototype different kernel implementations, test performance characteristics, and refine algorithms without the overhead of traditional CUDA development cycles. This agility has made Triton especially popular in research environments where time-to-insight is more critical than absolute peak performance.
Enhance your research capabilities with Perplexity for comprehensive information gathering and analysis of GPU optimization techniques and emerging technologies. The combination of advanced AI tools with modern development frameworks creates unprecedented opportunities for innovation in high-performance machine learning applications.
Memory Management and Optimization Strategies
Memory management represents a critical aspect of GPU kernel optimization where the philosophical differences between Triton and CUDA become most apparent. CUDA provides explicit control over all aspects of memory allocation, transfer, and access patterns, enabling developers to implement sophisticated optimization strategies tailored to specific use cases. This granular control allows for techniques such as custom memory pooling, asynchronous transfers, and fine-tuned coalescing patterns that can significantly impact performance.
Triton abstracts many memory management details behind its compiler, automatically handling common optimization patterns such as memory coalescing and shared memory utilization. While this automation reduces complexity and development time, it can sometimes result in suboptimal memory usage patterns for specialized applications. However, Triton’s automatic optimizations are generally effective for common machine learning operations and can achieve performance that rivals manually optimized CUDA implementations.
The trade-off between explicit control and automatic optimization becomes particularly relevant in applications with complex memory access patterns or tight memory constraints. CUDA’s explicit memory management enables developers to implement custom strategies that may be essential for achieving optimal performance in specific scenarios, while Triton’s automated approach provides consistently good results across a broader range of applications without requiring specialized expertise.
Integration with Machine Learning Frameworks
The integration capabilities of GPU kernel optimization frameworks with popular machine learning libraries significantly impact their practical utility and adoption. CUDA’s mature ecosystem provides seamless integration with virtually all major machine learning frameworks, including TensorFlow, PyTorch, JAX, and numerous specialized libraries. This broad compatibility has made CUDA the default choice for performance-critical machine learning applications across diverse domains.
Triton’s integration landscape is more focused but strategically important, with particularly strong support for PyTorch through direct integration in the framework’s ecosystem. This integration enables PyTorch users to write custom Triton kernels that can be seamlessly incorporated into existing models and training pipelines. The ability to define custom operations in Triton and use them as native PyTorch functions has opened new possibilities for research and experimentation in neural network architectures.
The framework integration capabilities also extend to deployment considerations, where CUDA’s established ecosystem provides mature solutions for production deployment across diverse hardware configurations. Triton’s newer ecosystem is rapidly evolving, with increasing support for deployment scenarios, but may require additional consideration for production use cases where stability and broad hardware support are critical requirements.
Hardware Compatibility and Future-Proofing
Hardware compatibility represents another crucial dimension in the comparison between Triton and CUDA for machine learning workloads. CUDA’s extensive hardware support spans multiple generations of NVIDIA GPUs, from older architectures to the latest cutting-edge designs. This broad compatibility ensures that CUDA applications can run across diverse hardware configurations, making it an attractive choice for applications that need to support varied deployment environments.
Triton’s hardware support is more focused, primarily targeting modern NVIDIA GPU architectures where its compiler optimizations are most effective. While this focused approach enables better optimization for supported hardware, it may limit deployment flexibility in environments with diverse or legacy hardware requirements. However, Triton’s compiler-based approach positions it well for future hardware developments, as new optimizations can potentially be added without requiring changes to user code.
The future-proofing considerations extend beyond hardware compatibility to include the evolution of GPU computing paradigms and machine learning requirements. CUDA’s established position and NVIDIA’s continued investment provide confidence in long-term support and evolution, while Triton’s modern design and active development suggest strong potential for adapting to emerging machine learning trends and requirements.
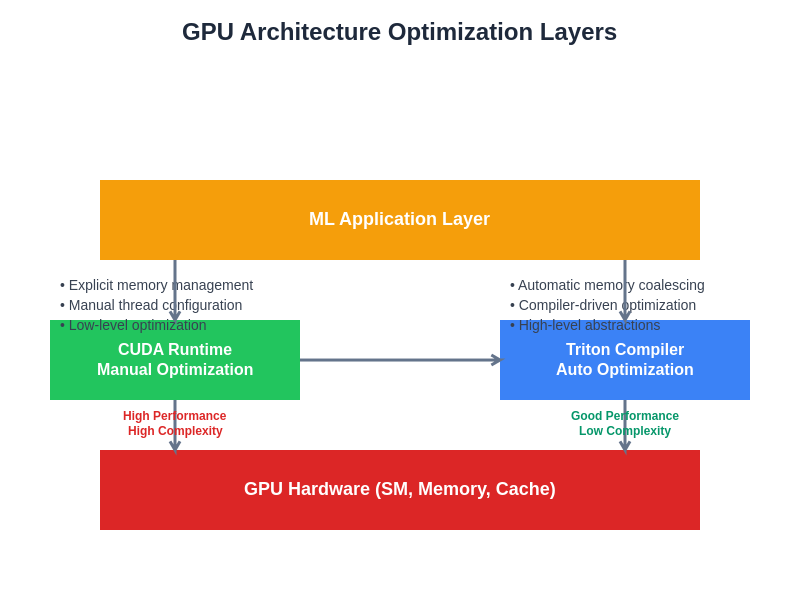
Understanding how different optimization frameworks interact with GPU hardware architectures is essential for making informed decisions about performance optimization strategies and long-term technology adoption.
Use Case Analysis and Decision Framework
The selection between Triton and CUDA for specific machine learning applications requires careful consideration of multiple factors including performance requirements, development resources, timeline constraints, and long-term maintenance considerations. Applications that demand absolute peak performance and have access to specialized GPU programming expertise may find CUDA’s explicit control and mature ecosystem advantageous despite the increased development complexity.
Research-oriented applications and rapid prototyping scenarios often benefit from Triton’s simplified development model and quick iteration capabilities. The framework’s ability to achieve good performance with minimal optimization effort makes it particularly attractive for exploratory work where development speed is more important than maximum performance. Additionally, applications with straightforward computational patterns that align well with Triton’s optimization capabilities can achieve excellent results without the complexity of CUDA development.
Production applications require consideration of additional factors including deployment complexity, maintenance requirements, and team expertise. CUDA’s mature ecosystem and broad hardware support may be essential for applications with stringent reliability and compatibility requirements, while Triton’s simplified maintenance model may be preferable for teams with limited GPU programming expertise.
Performance Optimization Techniques
The optimization strategies available in each framework reflect their fundamental design philosophies and target use cases. CUDA optimization typically involves manual tuning of numerous parameters including thread block sizes, memory access patterns, register usage, and synchronization strategies. Expert CUDA developers can achieve remarkable performance improvements through techniques such as custom memory hierarchies, advanced synchronization primitives, and architecture-specific optimizations.
Triton optimization focuses more on algorithmic design and high-level optimization strategies, with the compiler handling many low-level details automatically. Developers can influence performance through choices such as tiling strategies, memory access patterns, and computational order, while the compiler automatically applies appropriate low-level optimizations. This approach enables good performance with significantly less manual tuning effort.
The effectiveness of optimization strategies in each framework depends heavily on the specific characteristics of the computational workload and the expertise of the development team. Applications with regular computational patterns and standard memory access behaviors often achieve excellent results with Triton’s automatic optimizations, while irregular or specialized workloads may require CUDA’s manual optimization capabilities to achieve optimal performance.
Community and Ecosystem Considerations
The community and ecosystem surrounding each framework significantly impact their practical utility and long-term viability. CUDA benefits from over a decade of community development, extensive documentation, numerous educational resources, and a vast collection of optimized libraries and tools. This mature ecosystem provides solutions for virtually any GPU computing challenge and ensures that developers can find assistance and resources for their projects.
Triton’s ecosystem is newer but growing rapidly, particularly within the machine learning research community. The framework benefits from active development by OpenAI and increasing adoption by researchers and practitioners who value its accessibility and integration with modern machine learning workflows. The growing collection of Triton kernels and examples provides valuable resources for developers looking to leverage the framework for their applications.
The choice between frameworks often depends on the availability of existing solutions and community support for specific use cases. CUDA’s extensive ecosystem means that many common optimization patterns have already been implemented and optimized by the community, while Triton’s newer ecosystem may require more custom development but offers opportunities to contribute to an emerging and rapidly evolving platform.

The breadth and maturity of development ecosystems significantly impact the practical adoption and long-term success of GPU optimization frameworks. Understanding these ecosystem characteristics is crucial for strategic technology selection and planning.
Future Directions and Emerging Trends
The evolution of GPU kernel optimization frameworks continues to be driven by changing requirements in machine learning and advances in hardware technology. Emerging trends such as sparsity-aware computing, mixed-precision arithmetic, and novel neural network architectures create new optimization challenges that both CUDA and Triton must address to remain relevant and effective.
CUDA’s future development focuses on supporting new hardware features, improving development tools, and maintaining compatibility across diverse computing environments. NVIDIA’s continued investment in the CUDA ecosystem suggests ongoing evolution and adaptation to emerging computing paradigms, while maintaining the platform’s core strengths in performance and flexibility.
Triton’s future development emphasizes expanding automatic optimization capabilities, broadening hardware support, and improving integration with machine learning frameworks. The framework’s compiler-based approach provides opportunities for incorporating new optimization techniques and supporting emerging computational patterns without requiring changes to user code.
The convergence of these approaches suggests a future where developers have access to tools that combine CUDA’s performance capabilities with Triton’s ease of use, potentially through hybrid approaches or improved automation in traditional GPU programming frameworks. This evolution promises to make high-performance GPU computing more accessible while maintaining the performance characteristics essential for cutting-edge machine learning applications.
Practical Implementation Strategies
Successful implementation of GPU kernel optimization requires careful planning and consideration of project-specific requirements and constraints. Organizations should evaluate their team’s expertise, development timelines, performance requirements, and long-term maintenance capabilities when selecting optimization frameworks and implementation strategies.
For teams with strong GPU programming expertise and applications requiring maximum performance, CUDA may provide the best path forward despite its complexity. The investment in CUDA expertise can pay dividends through superior performance and access to the mature ecosystem of tools and libraries. However, organizations should consider the long-term sustainability of maintaining specialized GPU programming expertise.
Teams focused on rapid development and research applications may find Triton’s simplified development model more suitable for their needs. The framework’s ability to achieve good performance with minimal optimization effort can accelerate development cycles and enable more experimental approaches to algorithm development. Organizations should consider Triton’s growing ecosystem and integration capabilities when evaluating its suitability for their applications.
The optimal approach for many organizations may involve a hybrid strategy that leverages both frameworks based on specific use case requirements. Critical performance bottlenecks might warrant CUDA optimization, while less performance-sensitive operations could benefit from Triton’s development efficiency. This balanced approach can optimize both performance and development productivity across diverse application requirements.
Conclusion and Strategic Recommendations
The comparison between Triton and CUDA for GPU kernel optimization in machine learning workloads reveals complementary strengths that serve different aspects of the development landscape. CUDA’s mature ecosystem, comprehensive hardware support, and maximum performance potential make it essential for applications requiring peak performance and broad compatibility. Triton’s accessibility, rapid development capabilities, and intelligent automation make it valuable for research applications and teams seeking to leverage GPU acceleration without extensive specialization.
The future of GPU kernel optimization likely involves continued evolution of both approaches, with CUDA maintaining its position as the performance standard while Triton and similar frameworks expand access to GPU acceleration for broader developer communities. Organizations should evaluate their specific requirements, team capabilities, and long-term objectives when selecting optimization strategies, potentially leveraging both frameworks to optimize different aspects of their machine learning workloads.
The rapid pace of innovation in machine learning and GPU computing suggests that flexibility and adaptability will be crucial for long-term success. Teams that develop expertise in both traditional and modern optimization approaches will be best positioned to leverage emerging opportunities and address evolving performance requirements in the dynamic landscape of high-performance machine learning applications.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The performance characteristics and capabilities described may vary depending on specific hardware configurations, software versions, and implementation details. Readers should conduct thorough testing and evaluation based on their specific requirements and use cases. The rapidly evolving nature of GPU computing technologies means that capabilities and best practices may change over time, requiring ongoing evaluation and adaptation of optimization strategies.