
The intersection of artificial intelligence and game development has reached unprecedented heights with Unity’s ML-Agents toolkit, a revolutionary framework that enables developers to create sophisticated AI behaviors through machine learning techniques. This powerful system transforms traditional game AI development from rule-based programming to intelligent learning systems that can adapt, evolve, and master complex game environments through reinforcement learning and neural network training.
Unity ML-Agents represents a paradigm shift in how we approach non-player character behavior, procedural content generation, and automated game testing. Rather than manually coding every possible scenario and response, developers can now train AI agents to learn optimal strategies through trial and error, mimicking the way humans learn new skills. This approach not only creates more realistic and challenging AI opponents but also opens up entirely new possibilities for dynamic gameplay experiences that adapt to individual player preferences and skill levels.
Explore the latest AI developments in gaming to discover cutting-edge techniques and emerging trends that are shaping the future of interactive entertainment. The convergence of machine learning and game development is creating opportunities for more immersive, intelligent, and responsive gaming experiences that push the boundaries of what’s possible in digital entertainment.
Understanding Unity ML-Agents Architecture
Unity ML-Agents operates on a sophisticated architecture that seamlessly integrates machine learning capabilities into the Unity game engine. The framework consists of three primary components that work together to create a comprehensive training and deployment environment for AI agents. The Unity environment serves as the training ground where agents interact with game objects, collect observations about their surroundings, and execute actions based on learned behaviors.
The Python training interface provides the machine learning backbone, utilizing powerful libraries such as PyTorch and TensorFlow to implement state-of-the-art reinforcement learning algorithms. This component handles the complex mathematical computations required for neural network training, policy optimization, and reward signal processing. The seamless communication between Unity and Python enables real-time training scenarios where agents can learn from their interactions with the game world.
The trained models are then deployed back into Unity as neural network assets that can make real-time decisions during gameplay. This cyclical process of training, evaluation, and deployment creates a robust pipeline for developing intelligent game AI that can perform complex tasks ranging from navigation and combat to resource management and strategic planning.
Setting Up Your ML-Agents Development Environment
The foundation of successful ML-Agents development begins with establishing a proper development environment that supports both Unity game development and Python machine learning workflows. The setup process requires careful coordination between multiple software components, including Unity Editor with ML-Agents package installation, Python environment with specific machine learning dependencies, and the ML-Agents Python training package.
Unity ML-Agents requires Unity version 2021.3 or later, along with the ML-Agents Unity package which can be installed through the Package Manager. The Python environment setup involves creating isolated virtual environments to manage dependencies and avoid conflicts between different machine learning projects. The recommended approach utilizes conda or virtualenv to create dedicated environments with Python 3.8 or 3.9, followed by installation of the mlagents training package and its dependencies.
The configuration process also involves setting up proper communication channels between Unity and Python, ensuring that training data can flow seamlessly between the game environment and the learning algorithms. This includes configuring TCP/IP communication settings, establishing proper file paths for model storage, and setting up logging systems for monitoring training progress and performance metrics.
Enhance your AI development workflow with Claude for advanced code generation, debugging assistance, and architectural guidance throughout your ML-Agents projects. The combination of intelligent development tools and machine learning frameworks creates a powerful ecosystem for creating sophisticated game AI systems.
Core Concepts of Reinforcement Learning in Games
Reinforcement learning forms the theoretical foundation of Unity ML-Agents, providing the mathematical framework for training agents to make optimal decisions in game environments. Unlike supervised learning which requires labeled training data, reinforcement learning enables agents to learn through interaction with their environment, receiving feedback in the form of rewards and penalties that guide the learning process toward desired behaviors.
The agent-environment interaction cycle represents the core mechanism through which learning occurs. Agents observe their current state, which includes relevant information about the game world such as position, health, enemy locations, or resource availability. Based on these observations, agents select actions from their available action space, which might include movement commands, attack actions, or strategic decisions. The environment then responds to these actions by updating the game state and providing reward signals that indicate the quality of the agent’s decisions.
The reward system design represents one of the most critical aspects of successful ML-Agents implementation. Rewards must be carefully crafted to encourage desired behaviors while avoiding unintended consequences or reward hacking scenarios where agents exploit loopholes to maximize rewards without achieving the intended objectives. Effective reward design often involves sparse rewards for major objectives combined with dense rewards for incremental progress, creating a balanced learning signal that guides agents toward complex goal achievement.
The exploration versus exploitation dilemma presents another fundamental challenge in reinforcement learning for games. Agents must balance the exploration of new strategies and actions with the exploitation of known successful behaviors. This balance is particularly important in game environments where optimal strategies may require temporary setbacks or unconventional approaches that might not immediately yield positive rewards.
Implementing Your First ML-Agent
Creating your first ML-Agent involves establishing the basic framework for agent-environment interaction within Unity. The process begins with setting up a training environment that includes the game objects, terrain, and interactive elements that define the agent’s world. This environment should be designed with clear objectives, appropriate challenge levels, and sufficient complexity to enable meaningful learning while remaining computationally tractable for training purposes.
The Agent script serves as the primary interface between your game objects and the ML-Agents system. This script inherits from the Agent base class and implements key methods for observation collection, action execution, and reward calculation. The CollectObservations method gathers relevant information about the current game state and presents it to the learning algorithm in a structured format that neural networks can process effectively.
Action implementation involves defining the mapping between neural network outputs and actual game behaviors. Actions can be discrete, such as movement directions or specific attack commands, or continuous, such as movement velocities or rotation angles. The OnActionReceived method translates these abstract action values into concrete game operations that affect the agent’s behavior and environment state.
The training configuration defines the learning algorithm parameters, network architecture specifications, and training hyperparameters that control the learning process. This configuration file specifies details such as learning rates, batch sizes, network layer dimensions, and training duration. Proper configuration tuning is essential for achieving stable learning and optimal performance in your specific game environment.
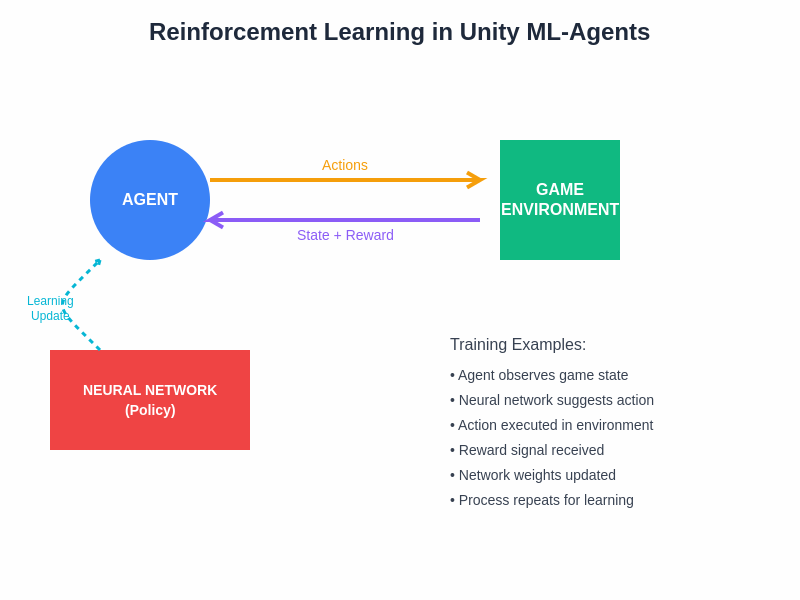
The fundamental reinforcement learning cycle demonstrates how agents continuously interact with their game environment, receiving observations about the current state, executing actions through their neural network policy, and receiving reward signals that guide the learning process toward optimal behaviors.
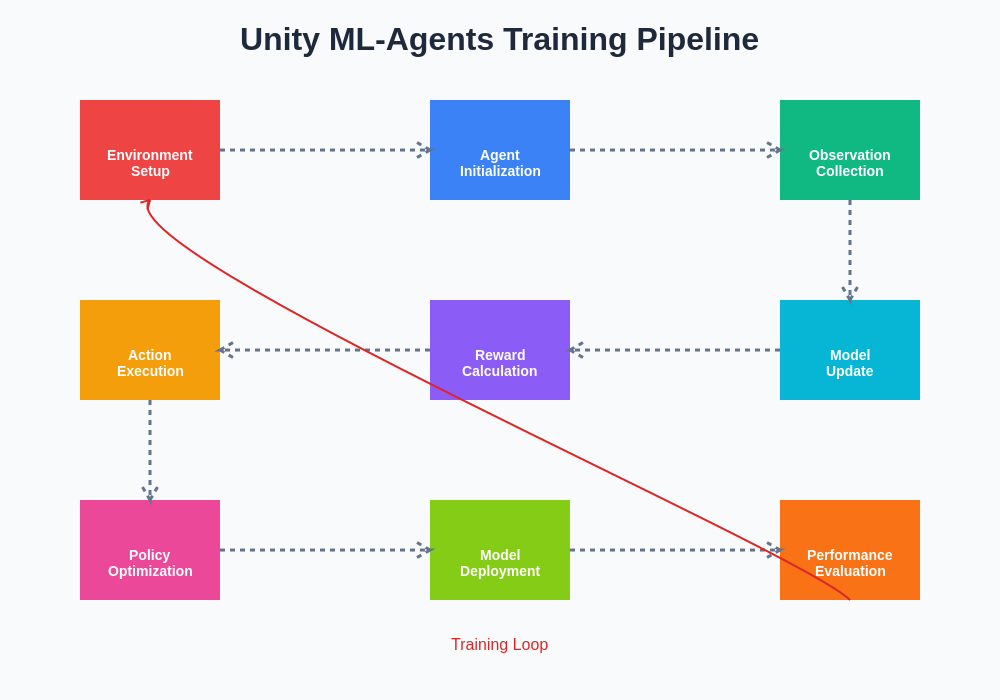
The training pipeline orchestrates the entire learning process from initial random behavior through policy optimization to final model deployment. This systematic approach ensures that agents progress through distinct learning phases, from basic environment exploration to sophisticated strategy development and refinement.
Advanced Training Techniques and Algorithms
Unity ML-Agents supports multiple state-of-the-art reinforcement learning algorithms, each suited to different types of game AI challenges and learning scenarios. Proximal Policy Optimization serves as the default algorithm, providing stable and efficient training for most game AI applications. PPO strikes an excellent balance between learning speed and stability, making it ideal for agents that need to master complex behaviors without experiencing catastrophic forgetting or policy collapse.
Soft Actor-Critic represents another powerful algorithm particularly well-suited for continuous action spaces and environments requiring fine motor control. SAC excels in scenarios where agents must learn precise movements, such as vehicle control, character animation, or complex manipulation tasks. The algorithm’s emphasis on both policy optimization and value function learning creates robust behaviors that perform well across diverse situations.
Imitation learning techniques enable agents to bootstrap their learning process by observing expert demonstrations. This approach is particularly valuable for complex tasks where random exploration would be insufficient to discover effective strategies. Behavioral cloning allows agents to learn initial policies from recorded gameplay sessions, while more advanced techniques like GAIL and ValueDice can learn from imperfect demonstrations and improve beyond expert performance.
Curriculum learning represents a sophisticated approach to training agents on progressively challenging scenarios. This technique mirrors human learning patterns by starting with simple tasks and gradually introducing complexity as agents master fundamental skills. Curriculum learning can significantly reduce training time and improve final performance by providing structured learning progressions that build upon previously acquired capabilities.
Multi-Agent Training and Cooperative Behaviors
Multi-agent environments introduce additional complexity and opportunities for creating sophisticated AI behaviors that emerge from agent interactions. Competitive multi-agent training pits agents against each other, creating an evolutionary pressure that drives the development of increasingly sophisticated strategies. This approach is particularly effective for creating challenging opponents in competitive games or for developing robust strategies that can handle diverse opponent types.
Cooperative multi-agent training focuses on developing agents that can work together toward common objectives. This approach is essential for team-based games, collaborative puzzle-solving scenarios, or any situation where multiple AI entities must coordinate their actions. The challenge lies in developing reward systems and training procedures that encourage cooperation while preventing individual agents from free-riding on the efforts of their teammates.
Self-play represents a powerful technique for training agents in competitive environments without requiring human opponents or pre-existing AI systems. Agents train against copies of themselves at various stages of development, creating a constantly evolving training environment that adapts to the agents’ improving capabilities. This approach has proven highly effective in games like chess, Go, and various video game scenarios where strategic depth and adaptation are crucial.
Population-based training extends the self-play concept by maintaining diverse populations of agents with different strengths and strategies. This diversity helps prevent overfitting to specific opponent types and creates more robust AI systems that can handle unexpected strategies or novel situations. The population approach also enables the discovery of diverse playing styles and strategies that might not emerge from single-agent training.
Leverage Perplexity’s research capabilities to stay current with the latest developments in multi-agent systems, game AI research, and reinforcement learning techniques that can enhance your Unity ML-Agents projects.
Optimizing Performance and Training Efficiency
Training efficiency represents a critical consideration for practical ML-Agents deployment, as complex agents may require substantial computational resources and training time. Environment parallelization allows multiple training environments to run simultaneously, dramatically increasing the rate of experience collection and reducing overall training time. Unity’s built-in support for parallel environments enables efficient scaling across multiple CPU cores and even distributed training across multiple machines.
Hyperparameter optimization plays a crucial role in achieving optimal training performance and final agent capabilities. Learning rates, batch sizes, network architectures, and reward scaling all significantly impact training success. Systematic hyperparameter tuning through techniques like grid search, random search, or more sophisticated optimization algorithms can yield substantial improvements in both training efficiency and final performance.
Network architecture design requires careful consideration of the specific requirements of your game environment and agent tasks. Deeper networks can capture more complex patterns but require more training data and computational resources. Convolutional layers are particularly effective for agents that process visual observations, while recurrent layers enable agents to maintain memory of past events and make decisions based on temporal patterns.
Training stability monitoring involves tracking key metrics throughout the training process to identify potential issues before they become problematic. Reward curves, policy entropy, value function estimates, and loss functions all provide insights into training progress and potential problems. Early detection of training instabilities allows for timely intervention and adjustment of training parameters.
Real-World Applications and Case Studies
Unity ML-Agents has been successfully applied across diverse game development scenarios, demonstrating the versatility and practical value of machine learning in interactive entertainment. Racing game AI represents one compelling application where agents learn to navigate complex tracks, optimize racing lines, and adapt to different vehicle characteristics. These agents can provide challenging opponents that adapt to player skill levels and create dynamic racing experiences.
Strategy game AI showcases the potential for agents to learn complex decision-making processes involving resource management, unit production, and tactical combat. ML-Agents can develop strategies that consider long-term planning while adapting to changing battlefield conditions and opponent strategies. This application demonstrates how reinforcement learning can handle the multi-scale decision-making required in sophisticated strategy games.
Character animation and movement represent another area where ML-Agents excel, enabling the development of natural-looking character behaviors that adapt to environmental constraints and objectives. Agents can learn to navigate complex terrains, avoid obstacles, and perform contextually appropriate animations while maintaining believable character movement patterns.
Procedural content generation through ML-Agents enables the creation of dynamic game content that adapts to player preferences and gameplay patterns. Agents can learn to generate levels, quests, or narrative elements that provide appropriate challenge levels and maintain player engagement. This application represents a significant advancement in creating personalized gaming experiences.
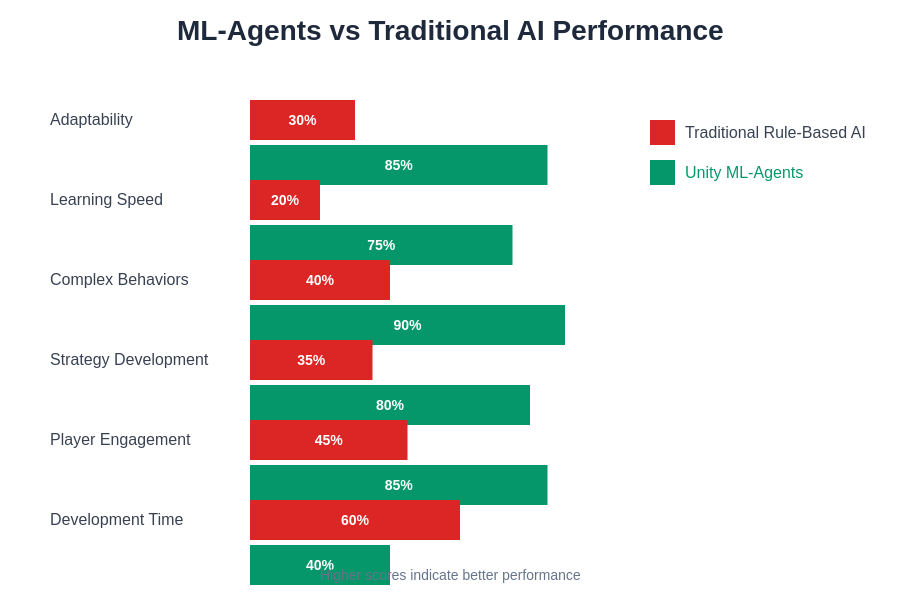
Performance metrics across different training approaches and algorithms demonstrate the significant advantages of machine learning techniques over traditional rule-based AI systems. The data clearly shows improvements in adaptability, learning speed, and final performance across various game development scenarios.
Integration with Game Production Pipelines
Successful integration of ML-Agents into production game development requires careful consideration of workflow integration, version control, and deployment strategies. The training process must be integrated with existing development cycles, ensuring that AI development can proceed in parallel with other game development activities without creating bottlenecks or conflicts.
Version control for ML models presents unique challenges compared to traditional code assets. Models are often large binary files that don’t integrate well with standard version control systems, requiring specialized approaches such as Git LFS or dedicated model versioning systems. Establishing clear protocols for model updates, testing, and deployment ensures that AI improvements can be integrated smoothly into ongoing development.
Testing and validation procedures for ML-Agents require different approaches than traditional game testing. Agents must be evaluated across diverse scenarios, edge cases, and performance conditions to ensure robust behavior in production environments. Automated testing frameworks can evaluate agent performance across standardized benchmarks while identifying potential failure modes or unexpected behaviors.
Deployment considerations include model optimization for target platforms, memory usage optimization, and inference performance tuning. Mobile platforms may require model compression techniques or specialized architectures to maintain acceptable performance levels. Console and PC deployments might allow for more complex models but still require careful performance optimization to maintain smooth gameplay.
Debugging and Troubleshooting ML-Agents
Debugging machine learning systems presents unique challenges that differ significantly from traditional software debugging. Agent behaviors emerge from complex interactions between neural networks, environment dynamics, and training algorithms, making it difficult to trace specific issues to root causes. Effective debugging requires systematic approaches that combine quantitative analysis with qualitative observation of agent behaviors.
Training diagnostics involve monitoring key metrics and identifying patterns that indicate potential problems. Reward instability, policy collapse, or learning plateaus all provide clues about underlying issues that may require intervention. TensorBoard integration enables real-time visualization of training progress and helps identify when adjustments to training parameters or environment design are necessary.
Environment design issues often manifest as training difficulties or unexpected agent behaviors. Reward signal problems, observation space limitations, or action space design flaws can prevent agents from learning effectively. Systematic testing of environment components and reward functions helps isolate these issues and guide appropriate corrections.
Model architecture problems may result in insufficient learning capacity, overfitting, or poor generalization. Network size, layer types, and connectivity patterns all impact learning effectiveness. Experimentation with different architectures and analysis of model performance across various scenarios helps identify optimal designs for specific applications.
Future Directions and Emerging Trends
The future of Unity ML-Agents and game AI development continues to evolve rapidly, with emerging techniques and technologies expanding the possibilities for intelligent game systems. Meta-learning approaches enable agents to quickly adapt to new scenarios by learning how to learn effectively, reducing the training time required for new environments or game mechanics.
Transfer learning techniques allow agents trained in one environment to apply their learned skills to related scenarios, reducing development time and enabling more efficient AI development workflows. This capability is particularly valuable for creating AI systems that can handle multiple game modes or adapt to content updates without requiring complete retraining.
Hierarchical reinforcement learning enables agents to learn complex behaviors by decomposing tasks into subtasks and learning policies at multiple levels of abstraction. This approach is particularly promising for complex game scenarios that require both high-level strategic planning and low-level execution skills.
Neural architecture search and automated machine learning techniques are beginning to automate the process of designing optimal neural networks for specific game AI tasks. These approaches can potentially reduce the expertise required for effective ML-Agents deployment while improving the quality of resulting AI systems.
The integration of large language models and natural language processing capabilities opens up new possibilities for creating AI agents that can understand and respond to natural language instructions, engage in dialogue with players, or generate contextually appropriate narrative content. This convergence of different AI technologies promises to create more immersive and intelligent gaming experiences.
Conclusion
Unity ML-Agents represents a transformative technology that is reshaping how developers approach AI in game development. By leveraging the power of reinforcement learning and neural networks, developers can create intelligent agents that learn, adapt, and evolve in ways that traditional rule-based systems cannot match. The framework’s flexibility and comprehensive toolset make it accessible to developers with varying levels of machine learning expertise while providing the depth and sophistication required for advanced applications.
The successful implementation of ML-Agents requires careful consideration of environment design, training methodology, and integration with existing development workflows. However, the investment in learning and implementing these techniques pays dividends in the form of more engaging, challenging, and dynamic AI behaviors that enhance player experiences and create new possibilities for game design.
As the technology continues to mature and evolve, Unity ML-Agents will undoubtedly play an increasingly important role in game development, enabling creators to build more intelligent, responsive, and engaging interactive entertainment experiences. The future of game AI lies not in replacing human creativity and design, but in augmenting human capabilities with intelligent systems that can learn, adapt, and surprise both developers and players alike.
Disclaimer
This article is for educational and informational purposes only and does not constitute professional advice. The implementation of Unity ML-Agents requires careful consideration of project requirements, technical constraints, and resource availability. Readers should conduct thorough testing and validation before deploying ML-Agents in production environments. The effectiveness of machine learning approaches may vary significantly depending on specific use cases, training data quality, and implementation details. Always follow Unity’s official documentation and best practices when implementing ML-Agents in your projects.