The rapid advancement of artificial intelligence and machine learning has created an unprecedented demand for sophisticated data storage and retrieval systems capable of handling high-dimensional vector representations known as embeddings. Vector databases have emerged as the cornerstone technology enabling organizations to harness the full potential of AI embeddings, providing efficient storage, indexing, and similarity-based search capabilities that power everything from recommendation engines to advanced natural language processing applications.
Explore the latest AI infrastructure trends to understand how vector databases are revolutionizing the way we store and query complex data representations in modern AI applications. The evolution from traditional databases to vector-specialized storage systems represents a fundamental shift in how we approach data architecture for AI-driven applications, enabling new possibilities for semantic understanding and intelligent information retrieval.
Understanding Vector Embeddings and Their Significance
Vector embeddings represent one of the most important breakthroughs in modern artificial intelligence, transforming complex data such as text, images, audio, and video into numerical representations that capture semantic meaning and relationships. These high-dimensional vectors, typically containing hundreds or thousands of floating-point numbers, encode the essential characteristics and contextual information of the original data in a format that machine learning algorithms can efficiently process and analyze.
The creation of embeddings involves sophisticated neural networks trained on vast datasets to learn meaningful representations of data. For text, models like OpenAI’s text-embedding-ada-002 or Google’s Universal Sentence Encoder convert words, sentences, or entire documents into dense vectors where semantically similar content occupies nearby positions in the vector space. Similarly, image embeddings capture visual features, patterns, and semantic content, enabling applications to understand and compare visual information at scale.
The significance of embeddings extends beyond mere data representation. They enable machines to understand context, similarity, and relationships in ways that mirror human cognition. When a user searches for “mountain hiking trails,” a system using embeddings can return results about “alpine trekking paths” or “scenic mountain walks” because these concepts occupy similar positions in the embedding space, despite using different words.
The Limitations of Traditional Databases for Vector Data
Traditional relational databases, optimized for structured data and exact matches, face fundamental limitations when dealing with vector embeddings and similarity-based queries. The primary challenge lies in the nature of vector similarity search, which requires computing distances between high-dimensional points rather than performing exact key lookups or range queries that traditional databases excel at handling.
Relational databases struggle with the computational complexity of similarity search across thousands of dimensions. A typical text embedding might contain 1,536 dimensions, and comparing two vectors requires calculating distances such as cosine similarity or Euclidean distance across all dimensions. When performed across millions or billions of vectors, these calculations become computationally prohibitive for systems designed around B-tree indexes and row-based storage optimized for exact matches.
Furthermore, traditional databases lack specialized indexing structures for high-dimensional data. Standard indexes like B-trees become ineffective in high-dimensional spaces due to the curse of dimensionality, where distance metrics lose discriminative power as the number of dimensions increases. This limitation necessitates full table scans for similarity queries, resulting in unacceptable performance for real-time applications requiring sub-second response times.
Discover advanced AI capabilities with Claude to enhance your understanding of vector databases and their integration with modern AI systems. The transition from traditional to vector-optimized storage represents a paradigm shift that enables new categories of intelligent applications previously impossible with conventional database technologies.
Vector Database Architecture and Core Components
Vector databases employ specialized architectures designed specifically for storing, indexing, and querying high-dimensional vector data efficiently. At their core, these systems implement advanced indexing algorithms such as Hierarchical Navigable Small World (HNSW) graphs, Inverted File (IVF) indexes, or Product Quantization (PQ) techniques that enable approximate nearest neighbor search with remarkable speed and accuracy.
The storage layer of vector databases is optimized for dense numerical data, often employing columnar storage formats that maximize memory efficiency and enable vectorized operations. Unlike traditional row-based storage, vector databases organize data to facilitate efficient similarity computations, often storing vectors in formats that enable SIMD (Single Instruction, Multiple Data) operations for parallel processing of vector calculations.
Memory management in vector databases represents a critical architectural consideration, as similarity search performance depends heavily on keeping frequently accessed vectors and index structures in memory. Many vector databases implement sophisticated caching strategies, memory mapping techniques, and tiered storage systems that balance performance with cost-effectiveness for large-scale deployments.
The query processing engine in vector databases is fundamentally different from traditional SQL engines, optimized for similarity-based operations rather than exact matches. These systems implement specialized query planners that understand vector operations, distance metrics, and approximate search algorithms, enabling complex queries that combine vector similarity with traditional filtering conditions.
Popular Vector Database Solutions and Their Characteristics
The vector database landscape has rapidly evolved to include numerous specialized solutions, each offering unique advantages for different use cases and deployment scenarios. Pinecone, one of the leading managed vector database services, provides a fully managed platform optimized for production workloads with features like automated scaling, real-time updates, and integrated monitoring. Its serverless architecture eliminates infrastructure management while providing consistent performance for applications ranging from recommendation systems to conversational AI.
Weaviate distinguishes itself through its GraphQL API and semantic search capabilities, offering a unique approach that combines vector search with graph-based data modeling. This hybrid architecture enables complex queries that traverse relationships while performing similarity search, making it particularly valuable for knowledge graphs and content management systems where both semantic understanding and relational data are important.
Chroma focuses on simplicity and developer experience, providing an embedded vector database that can run locally or be deployed as a service. Its Python-first approach and integration with popular machine learning frameworks make it an excellent choice for research, prototyping, and applications where ease of use is paramount. The ability to run Chroma embedded within applications eliminates network latency and simplifies deployment architectures.
Qdrant offers high-performance vector search with advanced filtering capabilities, supporting complex Boolean queries combined with vector similarity search. Its Rust-based implementation provides exceptional performance and memory efficiency, while its comprehensive API supports both REST and gRPC protocols. Qdrant’s payload filtering capabilities enable sophisticated applications that require both semantic search and traditional database-style querying.
Indexing Strategies for High-Dimensional Vector Search
Effective indexing represents the cornerstone of vector database performance, with various algorithms offering different trade-offs between search accuracy, speed, and memory consumption. The Hierarchical Navigable Small World (HNSW) algorithm has emerged as one of the most effective approaches for approximate nearest neighbor search, constructing a multi-layer graph structure that enables logarithmic search complexity while maintaining high recall rates.
HNSW creates a hierarchical structure where higher layers contain fewer nodes but longer connections, enabling rapid navigation to the approximate region of interest. Lower layers provide increasingly fine-grained navigation, ultimately leading to the most similar vectors. This approach combines the best aspects of skip lists and navigable small world graphs, providing excellent performance across diverse vector dimensionalities and dataset sizes.
Inverted File (IVF) indexing represents another crucial approach, particularly effective for large-scale deployments where memory constraints are significant. IVF partitions the vector space into clusters using techniques like k-means clustering, then maintains inverted indexes mapping cluster centroids to the vectors they contain. During search, the system identifies the most relevant clusters and performs detailed comparisons only within those subsets, dramatically reducing computational requirements.
Product Quantization (PQ) techniques enable significant memory compression by decomposing high-dimensional vectors into subvectors and quantizing each subspace independently. This approach reduces memory requirements by orders of magnitude while maintaining reasonable search accuracy, making it particularly valuable for applications with massive vector datasets where memory efficiency is crucial.
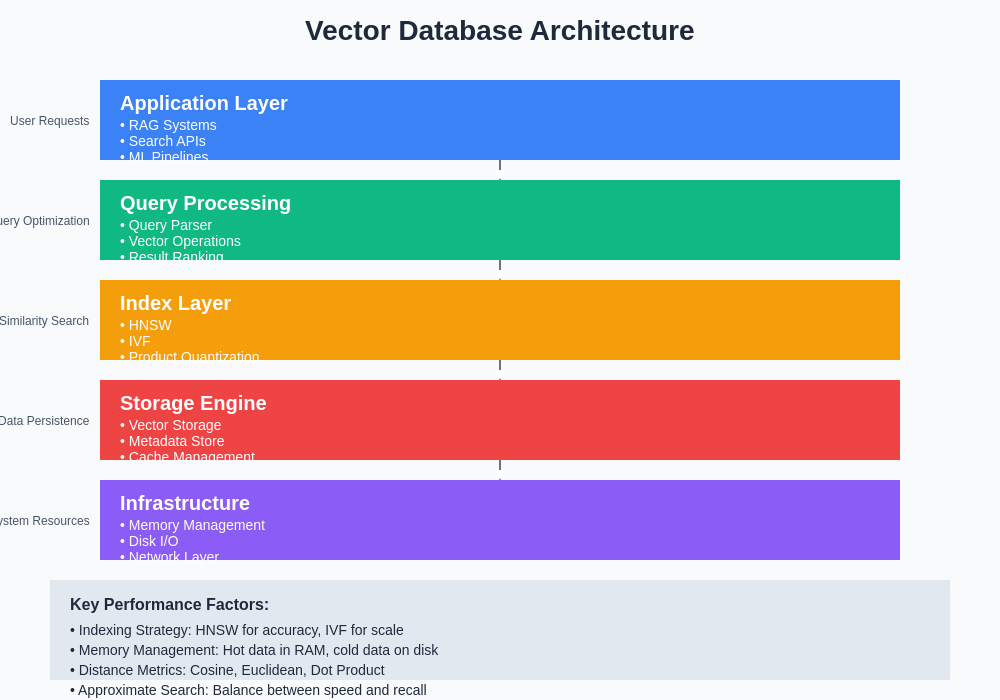
The sophisticated architecture of modern vector databases incorporates multiple indexing strategies, storage optimizations, and query processing techniques to deliver high-performance similarity search capabilities. This multi-layered approach ensures efficient handling of both small-scale applications and enterprise-level deployments with billions of vectors.
Similarity Metrics and Distance Functions
The choice of similarity metric fundamentally impacts vector database performance and search relevance, with different distance functions providing varying perspectives on vector relationships. Cosine similarity, measuring the angle between vectors regardless of their magnitude, proves particularly effective for text embeddings where document length should not influence semantic similarity. This metric normalizes vectors to unit length, focusing purely on directional relationships in the embedding space.
Euclidean distance, calculating the straight-line distance between vector endpoints, works well for embeddings where magnitude carries semantic meaning. Image embeddings often benefit from Euclidean distance calculations, as the absolute values of feature dimensions can represent important visual characteristics. However, Euclidean distance becomes less discriminative in very high-dimensional spaces due to the concentration of measure phenomenon.
Dot product similarity offers computational efficiency advantages while providing meaningful similarity measurements for normalized vectors. Many modern embedding models are designed to work optimally with dot product calculations, enabling faster query processing without sacrificing relevance. The mathematical relationship between dot product and cosine similarity for unit vectors makes this metric particularly attractive for large-scale applications.
Manhattan distance (L1 norm) and other Minkowski distances provide alternative perspectives on vector similarity, sometimes offering better performance for specific types of embeddings. The choice of distance metric should align with the embedding model’s training objectives and the specific requirements of the application, as different metrics can yield significantly different similarity rankings for the same vector pairs.
Enhance your AI research capabilities with Perplexity to explore the latest developments in similarity metrics and their applications in vector databases. Understanding the nuances of different distance functions enables more informed decisions about vector database configuration and optimization strategies.
Building Effective Vector Search Applications
Developing successful applications with vector databases requires careful consideration of embedding model selection, data preprocessing pipelines, and query optimization strategies. The embedding model choice significantly impacts both search quality and computational requirements, with newer models often providing better semantic understanding at the cost of increased dimensionality and processing time.
Data preprocessing plays a crucial role in vector search effectiveness, including text cleaning, chunking strategies for long documents, and normalization techniques that improve embedding quality. For text applications, proper handling of special characters, multiple languages, and domain-specific terminology can dramatically impact search relevance. Image applications require consideration of resolution, color space, and augmentation techniques that align with the embedding model’s training data.
Query optimization involves balancing search accuracy with response time requirements through careful tuning of index parameters, approximate search settings, and result filtering strategies. Many applications benefit from hybrid approaches that combine vector similarity with traditional filtering based on metadata, timestamps, or categorical attributes. This combination enables precise control over search results while maintaining the semantic understanding provided by vector embeddings.
Result ranking and post-processing represent critical components often overlooked in vector search applications. Raw similarity scores may not align perfectly with user expectations, requiring additional ranking signals, diversity controls, or business logic to produce optimal user experiences. Understanding the relationship between embedding spaces and user intent enables more sophisticated result processing that improves application effectiveness.
Performance Optimization and Scalability Considerations
Achieving optimal performance in vector database applications requires systematic attention to multiple optimization dimensions, including index configuration, memory management, and query patterns. Index parameters such as the number of clusters in IVF indexes or the connectivity degree in HNSW graphs significantly impact both search speed and accuracy, requiring careful tuning based on dataset characteristics and application requirements.
Memory optimization strategies become critical as vector datasets grow, with techniques like memory mapping, tiered storage, and intelligent caching enabling efficient handling of datasets that exceed available RAM. Many vector databases implement sophisticated memory management that keeps hot vectors in memory while transparently accessing cold data from disk, providing a balance between performance and cost-effectiveness.
Query batching and parallel processing can dramatically improve throughput for applications with multiple concurrent similarity searches. Vector databases often support batch query APIs that amortize index traversal costs across multiple searches, while parallel processing capabilities enable efficient utilization of modern multi-core hardware architectures.
Horizontal scaling strategies vary significantly across vector database implementations, with some supporting distributed architectures that shard vectors across multiple nodes while others focus on vertical scaling optimizations. Understanding the scaling characteristics of different vector databases enables appropriate architecture decisions for applications with growing data and query volumes.
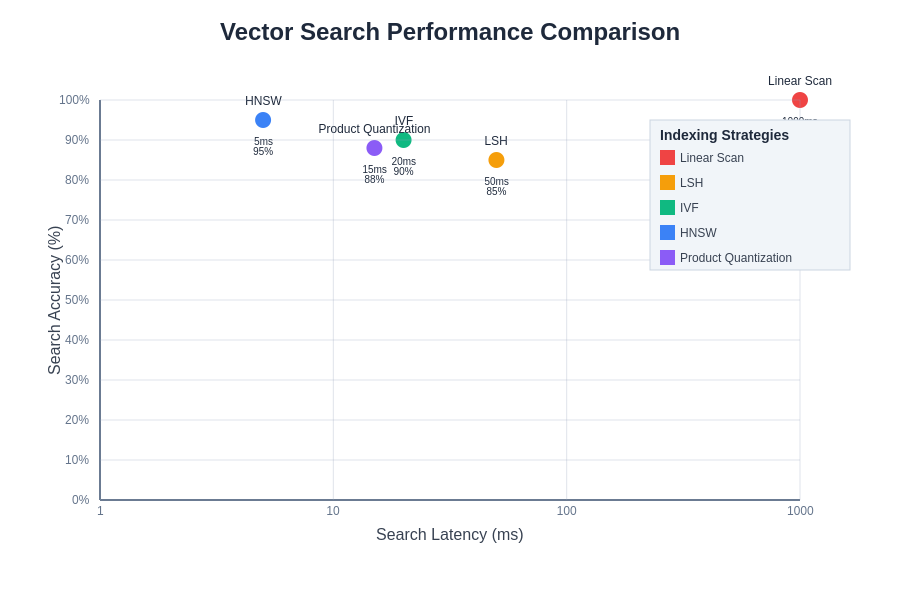
Performance optimization in vector databases involves careful balance between search accuracy, latency, and resource utilization. Different indexing strategies and configuration parameters provide various trade-offs that must be evaluated based on specific application requirements and constraints.
Integration with AI and Machine Learning Workflows
Vector databases have become integral components of modern AI workflows, particularly in retrieval-augmented generation (RAG) systems that combine large language models with external knowledge bases. These systems use vector databases to store document embeddings and retrieve contextually relevant information to augment language model responses, enabling more accurate and up-to-date AI applications.
The integration process typically involves embedding generation pipelines that process new content, update vector indexes, and maintain consistency between the knowledge base and its vector representations. This workflow requires careful orchestration of embedding models, database updates, and cache invalidation to ensure system reliability and data freshness.
Real-time applications present unique challenges for vector database integration, requiring low-latency embedding generation and immediate index updates to support interactive user experiences. Streaming architectures that process new data continuously while maintaining search performance represent an important consideration for applications like real-time recommendation systems or conversational AI platforms.
Model serving architectures often co-locate embedding generation with vector search to minimize latency and maximize throughput. This approach requires careful consideration of resource allocation, model caching strategies, and horizontal scaling patterns that can accommodate both embedding generation and similarity search workloads effectively.
Security and Privacy Considerations
Vector databases handling sensitive information require comprehensive security measures that protect both the stored embeddings and the original data they represent. While vectors themselves may appear as abstract numerical arrays, they can potentially be reverse-engineered to reveal information about the original content, necessitating careful attention to access controls and data protection strategies.
Encryption at rest and in transit represents a fundamental security requirement for vector databases containing sensitive information. However, encryption can complicate similarity search operations, as encrypted vectors cannot be directly compared for similarity. Some advanced vector databases implement searchable encryption techniques that enable similarity queries over encrypted data while maintaining privacy protections.
Access control mechanisms must account for the unique characteristics of vector search, where traditional row-level security models may not apply directly. Vector databases often implement filtering mechanisms that restrict search results based on user permissions, metadata attributes, or other security contexts while maintaining search performance.
Data anonymization and differential privacy techniques offer additional protection layers for sensitive vector data. These approaches introduce controlled noise or remove identifying information while preserving the statistical properties necessary for effective similarity search, enabling privacy-preserving applications in sensitive domains like healthcare or finance.
Use Cases and Industry Applications
Vector databases enable a diverse range of applications across industries, with recommendation systems representing one of the most widespread use cases. E-commerce platforms use vector databases to store product embeddings that capture features, descriptions, and user interaction patterns, enabling sophisticated recommendation algorithms that understand product similarity and user preferences beyond traditional collaborative filtering approaches.
Content discovery and search applications leverage vector databases to enable semantic search capabilities that understand user intent rather than relying solely on keyword matching. News organizations, knowledge management systems, and digital libraries use vector search to help users find relevant content even when their queries use different terminology than the stored documents, dramatically improving search effectiveness and user satisfaction.
Customer support and chatbot applications use vector databases to implement intelligent knowledge base search, enabling AI assistants to find relevant information from vast documentation repositories. This approach allows support systems to provide accurate, contextual responses by retrieving the most relevant information based on semantic similarity rather than exact keyword matches.
Fraud detection and security applications employ vector databases to store behavioral embeddings that capture user patterns, transaction characteristics, and network activities. These systems can identify anomalous behavior by finding outliers in the vector space or detecting similarities to known fraudulent patterns, enabling more sophisticated threat detection than traditional rule-based approaches.
Future Trends and Technological Evolution
The vector database landscape continues evolving rapidly, with emerging trends pointing toward more sophisticated indexing algorithms, improved integration with AI frameworks, and specialized optimizations for different types of embeddings. Approximate nearest neighbor search algorithms are becoming more accurate and efficient, with new approaches like learned indexes that adapt to data distributions providing better performance than traditional static indexing methods.
Multi-modal embeddings that combine text, image, and audio information in unified vector representations are driving demand for vector databases optimized for diverse embedding types. These applications require sophisticated indexing strategies that can handle varying dimensionalities and distance metrics while maintaining consistent performance across different modalities.
Edge computing applications are creating demand for lightweight vector database implementations that can run efficiently on resource-constrained devices. This trend requires new approaches to index compression, memory optimization, and distributed query processing that enable vector search capabilities in mobile applications and IoT environments.
The integration of vector databases with streaming data processing systems is enabling real-time applications that can update embeddings and search indexes continuously as new data arrives. This capability supports applications like live recommendation systems, real-time content moderation, and dynamic knowledge bases that evolve constantly based on user interactions and content updates.
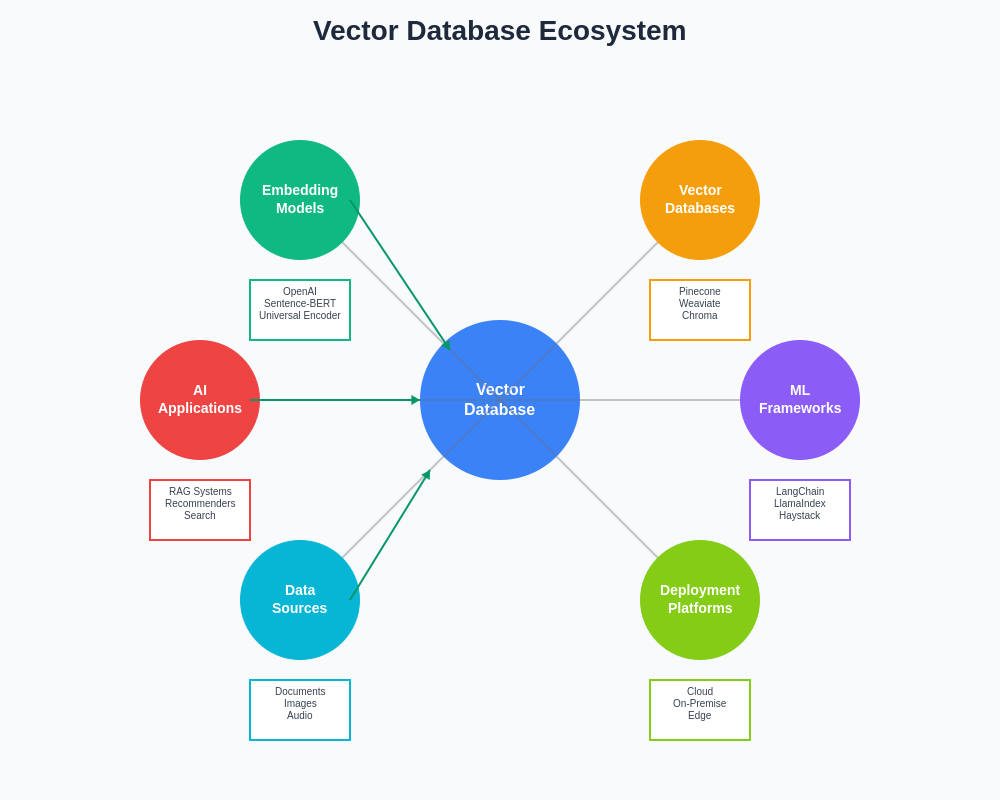
The expanding ecosystem of vector databases, embedding models, and AI applications creates a rich landscape of possibilities for intelligent data processing and retrieval. This interconnected environment enables increasingly sophisticated applications that bridge the gap between human understanding and machine processing capabilities.
Best Practices and Implementation Guidelines
Successful vector database implementations require careful planning of data modeling strategies that align with application requirements and usage patterns. Choosing appropriate embedding dimensions involves balancing semantic richness with computational efficiency, as higher-dimensional embeddings provide more nuanced representations but require more storage and processing resources.
Data pipeline design should account for embedding consistency, version management, and incremental updates that maintain search quality while accommodating evolving content. Implementing robust monitoring and observability systems enables early detection of performance degradation, index corruption, or embedding drift that could impact application effectiveness.
Testing strategies for vector search applications differ significantly from traditional database testing, requiring evaluation of search relevance, recall rates, and user satisfaction metrics rather than just functional correctness. A/B testing frameworks that can measure the impact of different embedding models, indexing strategies, and similarity metrics provide valuable insights for optimization decisions.
Capacity planning for vector databases requires understanding of memory requirements, query patterns, and growth projections that account for both data volume increases and dimensionality changes as embedding models evolve. This planning should consider the total cost of ownership including compute resources, storage costs, and operational overhead for maintaining high-performance vector search systems.
The future of vector databases lies in their continued evolution as foundational infrastructure for AI applications, enabling increasingly sophisticated semantic understanding and intelligent information retrieval capabilities. As embedding models become more powerful and applications more complex, vector databases will play an increasingly critical role in bridging the gap between human knowledge and machine understanding, powering the next generation of intelligent applications that can understand, reason about, and act upon complex information in ways that mirror human cognitive capabilities.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on current understanding of vector database technologies and their applications in AI systems. Readers should conduct their own research and consider their specific requirements when implementing vector database solutions. The performance characteristics and capabilities of different vector databases may vary significantly based on use case, data characteristics, and deployment configurations.