
The development of custom voice assistants and AI speakers has emerged as one of the most compelling frontiers in artificial intelligence and consumer technology, offering developers unprecedented opportunities to create personalized, intelligent audio interfaces that can transform how users interact with digital systems. This comprehensive exploration of voice assistant development delves into the intricate technical foundations, practical implementation strategies, and innovative possibilities that define this rapidly evolving field, providing developers with the knowledge and tools necessary to build sophisticated voice-enabled applications from the ground up.
Explore the latest AI development trends to understand how voice technology is shaping the future of human-computer interaction across diverse industries and applications. The convergence of advanced machine learning algorithms, improved speech recognition capabilities, and accessible development frameworks has democratized voice assistant creation, enabling developers to build custom solutions that rival commercial offerings while maintaining complete control over functionality, privacy, and user experience.
Understanding Voice Assistant Architecture
The foundation of any successful voice assistant lies in its carefully orchestrated architecture that seamlessly integrates multiple complex technologies to deliver natural, responsive voice interactions. Modern voice assistants operate through a sophisticated pipeline that begins with audio capture and progresses through speech recognition, natural language understanding, intent processing, response generation, and finally speech synthesis to complete the conversational loop.
The architectural design of voice assistants requires careful consideration of real-time processing requirements, latency optimization, and resource management to ensure responsive user experiences. The system must efficiently handle continuous audio monitoring, trigger word detection, noise cancellation, and acoustic echo cancellation while maintaining low power consumption and minimal computational overhead during idle states.
Understanding the intricate relationships between hardware components, software frameworks, and cloud services forms the cornerstone of effective voice assistant development. The architecture must accommodate various deployment scenarios, from edge computing implementations that prioritize privacy and offline functionality to cloud-based solutions that leverage powerful remote processing capabilities for enhanced accuracy and feature richness.
Speech Recognition and Audio Processing
The speech recognition component serves as the critical gateway between human speech and digital understanding, requiring sophisticated signal processing techniques to accurately convert spoken words into machine-readable text. Modern automatic speech recognition systems employ deep neural networks, particularly recurrent neural networks and transformer architectures, to achieve impressive accuracy rates across diverse accents, speaking styles, and acoustic environments.
Audio preprocessing plays a fundamental role in optimizing speech recognition performance, involving techniques such as noise reduction, voice activity detection, acoustic echo cancellation, and audio normalization. These preprocessing steps are essential for maintaining consistent recognition quality across different microphone configurations, room acoustics, and background noise conditions that users may encounter in real-world deployment scenarios.
The implementation of wake word detection requires specialized always-listening algorithms that can efficiently monitor continuous audio streams while minimizing false positive activations and maintaining reasonable power consumption. This involves training custom models on specific trigger phrases and implementing sophisticated threshold mechanisms that balance sensitivity with specificity to ensure reliable activation behavior.
Discover advanced AI capabilities with Claude for developing sophisticated natural language processing components that power intelligent voice assistant responses and contextual understanding. The integration of multiple AI technologies creates voice assistants that can handle complex queries, maintain conversational context, and provide personalized responses that adapt to individual user preferences and communication styles.
Natural Language Understanding and Processing
The natural language understanding component transforms recognized speech into structured, actionable data that the voice assistant can process to determine user intent and extract relevant parameters. This sophisticated process involves multiple layers of analysis, including syntactic parsing, semantic analysis, entity recognition, and intent classification, all working together to comprehend the meaning and context of user utterances.
Modern natural language processing frameworks leverage transformer-based models and large language models to achieve remarkable understanding capabilities that can handle complex queries, ambiguous phrasing, and contextual references. These systems can maintain conversation history, resolve pronouns and implicit references, and understand nuanced requests that require multi-step reasoning and domain-specific knowledge.
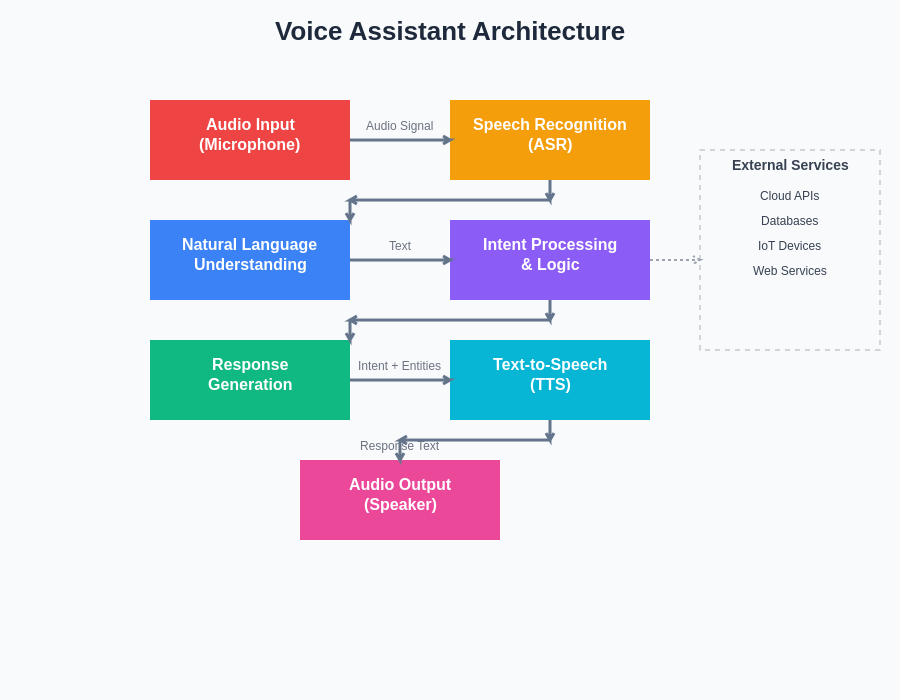
The development of effective natural language understanding requires careful attention to training data quality, model architecture selection, and continuous refinement based on real-world usage patterns. Developers must consider factors such as domain specificity, multilingual support, and the ability to handle out-of-vocabulary words and colloquial expressions that users naturally employ in voice interactions.
Hardware Integration and Device Development
Building custom AI speakers requires comprehensive understanding of hardware selection, integration techniques, and optimization strategies that balance performance, cost, and form factor considerations. The hardware foundation typically includes high-quality microphones with beamforming capabilities, powerful processing units capable of running machine learning models, sufficient memory for model storage and real-time processing, and audio output systems that deliver clear, natural-sounding speech synthesis.
Microphone array design plays a crucial role in achieving optimal audio capture quality, with considerations for directional sensitivity, noise rejection, and far-field voice recognition capabilities. Advanced implementations may incorporate multiple microphones arranged in linear or circular arrays, enabling sophisticated beamforming algorithms that can focus on specific speakers while suppressing background noise and reverberation.
The selection of processing hardware must carefully balance computational requirements with power consumption constraints, particularly for battery-powered or always-on devices. Modern system-on-chip solutions offer dedicated neural processing units and digital signal processors optimized for machine learning workloads, enabling efficient on-device processing while maintaining acceptable battery life and thermal characteristics.
Development Frameworks and Tools
The landscape of voice assistant development has been significantly enhanced by the availability of comprehensive frameworks and development tools that streamline the creation process while providing access to state-of-the-art capabilities. Popular frameworks such as Mozilla DeepSpeech, Google’s Speech-to-Text API, Amazon’s Alexa Voice Service, and open-source alternatives like Rhasspy provide developers with powerful building blocks for creating custom voice applications.
These frameworks typically offer pre-trained models for speech recognition and synthesis, along with development tools for training custom models, testing voice interactions, and deploying applications across various platforms. The choice of framework depends on factors such as accuracy requirements, privacy considerations, offline capabilities, customization needs, and target deployment platforms.
Cloud-based development platforms provide scalable infrastructure for processing voice interactions, training machine learning models, and managing large-scale deployments. These platforms often include comprehensive analytics tools, A/B testing capabilities, and continuous integration pipelines that enable rapid iteration and improvement of voice assistant functionality.
Privacy and Security Considerations
The development of voice assistants raises significant privacy and security considerations that developers must carefully address to protect user data and maintain trust in voice-enabled applications. Voice data contains highly personal information that requires secure handling, encrypted transmission, and responsible storage practices that comply with relevant privacy regulations and user expectations.
Implementing on-device processing capabilities can significantly enhance privacy by reducing the need to transmit sensitive voice data to external servers. This approach requires careful optimization of machine learning models to run efficiently on resource-constrained devices while maintaining acceptable accuracy and response times for common use cases.
Security measures must encompass multiple layers of protection, including secure boot processes, encrypted data storage, authenticated communication channels, and robust access control mechanisms. Developers must also consider potential attack vectors such as voice spoofing, adversarial examples, and unauthorized access attempts that could compromise system integrity or user privacy.
Enhance your development workflow with Perplexity for comprehensive research on emerging security standards and best practices in voice assistant development. The rapidly evolving security landscape requires continuous attention to new threats and mitigation strategies that protect both individual users and the broader ecosystem of voice-enabled devices.
Real-Time Processing and Optimization
Achieving responsive voice interactions requires sophisticated optimization techniques that minimize latency throughout the entire processing pipeline while maintaining high accuracy and reliability. Real-time processing involves careful coordination between audio capture, speech recognition, natural language processing, and response generation to deliver seamless user experiences that feel natural and intuitive.
Latency optimization strategies include efficient model architectures, hardware acceleration, pipeline parallelization, and predictive processing techniques that anticipate user needs and pre-compute likely responses. Advanced implementations may employ streaming recognition algorithms that begin processing partial utterances before users finish speaking, enabling more responsive interactions for common queries and commands.
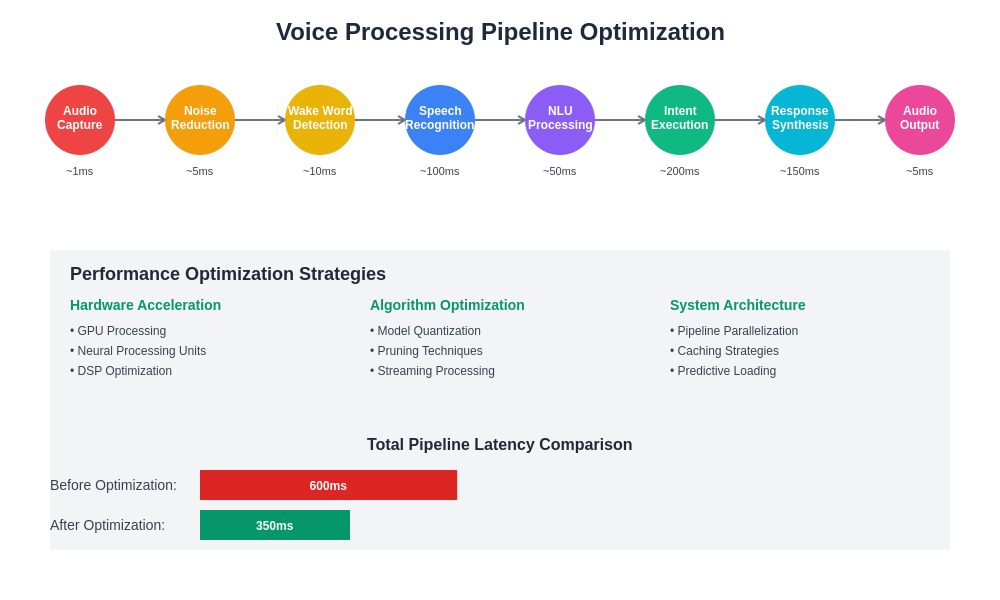
Memory management and computational efficiency become critical factors in real-time voice processing, requiring careful attention to model size, inference speed, and resource utilization patterns. Developers must balance accuracy requirements with performance constraints to deliver optimal user experiences across diverse hardware configurations and deployment scenarios.
Machine Learning Model Training and Customization
Creating effective voice assistants often requires training custom machine learning models tailored to specific domains, user groups, or application requirements. This process involves collecting and preparing training data, selecting appropriate model architectures, implementing training pipelines, and evaluating model performance across diverse test scenarios and user demographics.
Data collection for voice assistant training presents unique challenges related to audio quality, speaker diversity, environmental conditions, and annotation accuracy. Successful training datasets must represent the full range of expected usage scenarios, including various accents, speaking styles, background noise levels, and microphone configurations that users may encounter in real-world deployments.
The training process requires significant computational resources and expertise in machine learning techniques, particularly for developing custom speech recognition models, natural language understanding components, and text-to-speech systems. Transfer learning and fine-tuning approaches can significantly reduce training requirements by leveraging pre-trained models and adapting them to specific use cases and domains.
Integration with Smart Home and IoT Ecosystems
Modern voice assistants increasingly serve as central control hubs for smart home devices and Internet of Things ecosystems, requiring sophisticated integration capabilities that enable seamless interaction with diverse connected devices and services. This integration involves implementing standardized communication protocols, managing device discovery and pairing processes, and providing intuitive voice commands for controlling complex multi-device scenarios.
The development of smart home integration requires understanding of various communication standards such as WiFi, Bluetooth, Zigbee, Z-Wave, and emerging protocols like Matter that aim to improve interoperability across different manufacturers and device types. Voice assistants must be capable of translating natural language commands into appropriate device-specific instructions while handling error conditions and providing meaningful feedback to users.
Advanced smart home integration scenarios involve creating complex automation routines, managing device groups and scenes, and providing contextual awareness that considers factors such as time of day, user location, and environmental conditions. These capabilities require sophisticated state management, rule engines, and machine learning algorithms that can adapt to user preferences and usage patterns over time.
Multi-Modal Interfaces and Visual Integration
Contemporary voice assistant development increasingly incorporates visual elements and multi-modal interfaces that combine voice interactions with touchscreens, LED indicators, and augmented reality displays. These hybrid interfaces leverage the strengths of different interaction modalities to create more engaging and effective user experiences that can accommodate diverse user preferences and accessibility requirements.
Visual integration enables voice assistants to display complementary information, provide graphical feedback, and support complex interactions that benefit from visual representation. This includes displaying search results, showing device status information, providing step-by-step instructions, and enabling touch-based refinement of voice commands when precision is required.
The design of multi-modal interfaces requires careful consideration of interaction flows, attention management, and accessibility principles that ensure consistent experiences across different modes of interaction. Developers must create cohesive design languages that seamlessly blend voice and visual elements while maintaining the natural, conversational feel that makes voice assistants appealing to users.
Testing and Quality Assurance Strategies
Comprehensive testing of voice assistants requires specialized methodologies that address the unique challenges of voice-based interactions, including variations in speech patterns, acoustic environments, and user expectations. Effective testing strategies encompass unit testing of individual components, integration testing of complete voice processing pipelines, and user acceptance testing with diverse speaker populations and real-world usage scenarios.
Automated testing frameworks for voice assistants must simulate various audio conditions, speaker characteristics, and interaction patterns to ensure consistent performance across expected usage scenarios. This includes testing with different microphone configurations, background noise levels, speaker distances, and acoustic environments that users may encounter in typical deployment settings.
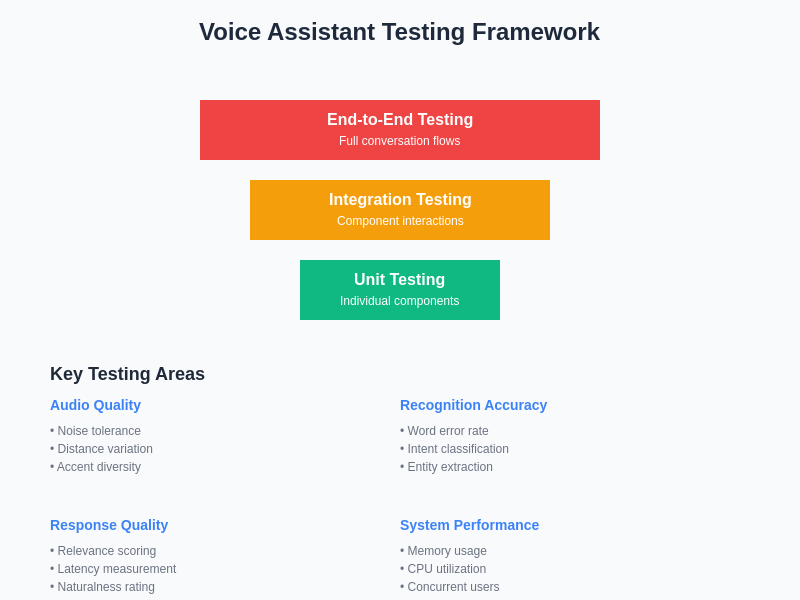
Quality assurance processes must also address subjective aspects of voice interactions, including naturalness of synthesized speech, appropriateness of responses, and overall user satisfaction with conversational experiences. This requires developing evaluation metrics that capture both objective performance measures and subjective quality assessments that reflect real user experiences and expectations.
Performance Monitoring and Analytics
Successful voice assistant deployments require robust monitoring and analytics systems that provide insights into usage patterns, performance metrics, and user satisfaction levels. These systems enable developers to identify optimization opportunities, detect performance issues, and guide future development priorities based on real-world usage data and user feedback.
Performance monitoring encompasses various metrics including recognition accuracy rates, response latency, error frequencies, and user engagement patterns that provide comprehensive visibility into system behavior and user experiences. Advanced analytics platforms can correlate performance metrics with environmental factors, hardware configurations, and user demographics to identify patterns and optimization opportunities.
User analytics and behavioral insights help developers understand how voice assistants are actually used in practice, revealing common interaction patterns, frequent error scenarios, and opportunities for improving user experiences. This data-driven approach enables continuous refinement of voice interfaces and the development of new features that address real user needs and preferences.
Future Directions and Emerging Technologies
The future of voice assistant development is being shaped by advancing technologies in artificial intelligence, edge computing, and human-computer interaction that promise to deliver more natural, capable, and personalized voice experiences. Emerging trends include improved emotional intelligence in voice interactions, more sophisticated contextual understanding, and the integration of voice assistants with augmented and virtual reality environments.
Advances in neural speech synthesis are enabling more natural, expressive, and personalized voice generation that can adapt to different contexts, emotions, and user preferences. These technologies are moving beyond simple text-to-speech conversion toward dynamic voice generation that can convey subtle emotional nuances and maintain consistent personality characteristics across interactions.
The integration of large language models and advanced reasoning capabilities is expanding the scope of tasks that voice assistants can handle effectively, moving from simple command execution toward more complex problem-solving, creative tasks, and multi-step reasoning scenarios that require sophisticated understanding and planning capabilities.
Implementation Best Practices and Deployment Strategies
Successful voice assistant development requires adherence to established best practices that ensure reliable, scalable, and maintainable implementations. These practices encompass architectural design principles, code organization strategies, documentation standards, and deployment methodologies that facilitate long-term success and team collaboration.
Modular architecture design enables flexible development and maintenance by separating concerns into distinct components that can be independently developed, tested, and updated. This approach facilitates code reuse, simplifies debugging, and enables teams to work efficiently on different aspects of the voice assistant without creating conflicts or dependencies.
Deployment strategies must consider factors such as scalability requirements, geographic distribution, update mechanisms, and rollback procedures that ensure reliable service delivery and minimize disruption to users. Modern deployment approaches often leverage containerization, microservices architectures, and continuous integration pipelines that enable rapid iteration and reliable service delivery.
The evolution of voice assistant technology continues to accelerate, driven by advances in artificial intelligence, improved hardware capabilities, and growing user adoption across diverse applications and industries. Developers who master the fundamental principles and emerging techniques of voice assistant development will be well-positioned to create innovative solutions that transform how users interact with technology and access information in increasingly natural and intuitive ways.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on current understanding of voice assistant technologies and development practices. Readers should conduct their own research and consider their specific requirements when implementing voice assistant solutions. The effectiveness and suitability of different approaches may vary depending on specific use cases, technical requirements, and deployment constraints.