
The evolution of speech-to-text technology has reached unprecedented levels of sophistication, with artificial intelligence-powered solutions transforming how we interact with audio content across industries. Two prominent platforms have emerged as leaders in this space: OpenAI’s Whisper and AssemblyAI, each offering unique approaches to automatic speech recognition that cater to different use cases and technical requirements. Understanding the nuances between these platforms becomes crucial for developers, businesses, and organizations seeking to implement robust speech-to-text capabilities in their applications and workflows.
Explore the latest AI speech recognition trends to discover cutting-edge developments in voice technology and audio processing that are reshaping communication and accessibility solutions. The choice between Whisper and AssemblyAI involves numerous technical, economic, and strategic considerations that extend far beyond simple accuracy metrics, encompassing factors such as integration complexity, scalability requirements, feature richness, and long-term viability.
Understanding Whisper’s Architecture and Approach
OpenAI’s Whisper represents a revolutionary approach to automatic speech recognition, built upon transformer architecture and trained on an extensive dataset of multilingual audio content. The model’s foundation lies in its ability to handle diverse audio conditions, accents, and languages with remarkable consistency, making it particularly valuable for applications requiring broad linguistic support and robust performance across varying audio quality conditions. Whisper’s open-source nature provides developers with unprecedented flexibility in implementation, allowing for local deployment, custom fine-tuning, and integration into existing infrastructure without external dependencies.
The technical architecture of Whisper emphasizes versatility and reliability, employing a sequence-to-sequence approach that processes audio input through multiple attention layers to generate accurate transcriptions. This design philosophy prioritizes consistent performance across diverse scenarios rather than optimizing for specific use cases, resulting in a solution that performs well across a wide range of applications while maintaining predictable behavior. The model’s training methodology, which incorporates weak supervision techniques and massive-scale data processing, has enabled it to achieve remarkable robustness in handling real-world audio challenges such as background noise, overlapping speech, and non-standard pronunciations.
AssemblyAI’s Specialized Features and Capabilities
AssemblyAI has positioned itself as a comprehensive speech-to-text platform that extends beyond basic transcription to offer sophisticated audio intelligence features. The platform’s strength lies in its specialized capabilities such as speaker diarization, sentiment analysis, content moderation, and entity detection, which transform raw audio transcription into actionable insights for business applications. This feature-rich approach makes AssemblyAI particularly attractive for enterprises and applications requiring advanced audio analysis beyond simple text conversion.
The platform’s API-first design philosophy emphasizes ease of integration and scalability, providing developers with robust infrastructure that handles the complexities of audio processing, storage, and analysis. AssemblyAI’s continuous model improvements and specialized training for different domains have resulted in highly accurate transcription capabilities that excel in specific use cases such as call center analytics, media processing, and conversational AI applications. The platform’s focus on real-time processing capabilities and webhook integrations facilitates seamless integration into existing workflows and systems.
Experience advanced AI capabilities with Claude for comprehensive analysis and decision-making support when evaluating speech-to-text solutions and their integration requirements. The technical sophistication of modern speech recognition platforms requires careful consideration of multiple factors that impact both immediate implementation success and long-term operational effectiveness.
Accuracy and Performance Comparison
The accuracy comparison between Whisper and AssemblyAI reveals nuanced differences that depend heavily on specific use cases, audio conditions, and content types. Whisper’s broad training approach results in consistently good performance across diverse scenarios, with particular strengths in handling accented speech, multilingual content, and challenging audio conditions. The model’s robustness stems from its extensive training on varied audio sources, enabling it to maintain reasonable accuracy even when processing audio that differs significantly from typical training data.
AssemblyAI’s accuracy profile reflects its focus on optimization for specific use cases and continuous refinement based on real-world usage patterns. The platform often achieves superior accuracy in business-focused applications such as meeting transcriptions, customer service recordings, and professional media content where audio quality is generally controlled and speakers follow conventional patterns. The platform’s ability to leverage context and domain-specific knowledge through its advanced features often results in more accurate and useful transcriptions for enterprise applications.
Performance characteristics differ significantly between the two platforms, with Whisper offering predictable processing times that scale with audio length and model size, while AssemblyAI provides optimized processing pipelines that can achieve faster turnaround times for supported audio formats and lengths. The choice between batch processing and real-time transcription requirements often influences performance considerations, as each platform has been optimized for different usage patterns and scaling scenarios.
Implementation and Integration Considerations
The implementation pathway for Whisper offers multiple deployment options that cater to different technical requirements and organizational constraints. Developers can choose between local deployment for maximum control and privacy, cloud-based implementations for scalability and convenience, or hybrid approaches that balance performance, cost, and security considerations. The open-source nature of Whisper enables extensive customization opportunities, including model fine-tuning, custom preprocessing pipelines, and integration with existing machine learning infrastructure.
AssemblyAI’s implementation approach emphasizes simplicity and rapid deployment through its comprehensive API ecosystem. The platform handles infrastructure complexity behind the scenes, allowing developers to focus on application logic rather than audio processing optimization. This managed approach reduces implementation time and maintenance overhead while providing enterprise-grade reliability and scaling capabilities. The platform’s extensive documentation, SDKs, and integration examples facilitate rapid prototyping and production deployment across various programming languages and frameworks.
Integration complexity varies significantly between the platforms, with Whisper requiring more technical expertise for optimal deployment but offering greater flexibility in implementation approaches. AssemblyAI’s streamlined integration process reduces technical barriers but may limit customization options for organizations with specific requirements or existing infrastructure constraints. The choice between these approaches often depends on team capabilities, project timelines, and long-term maintenance considerations.
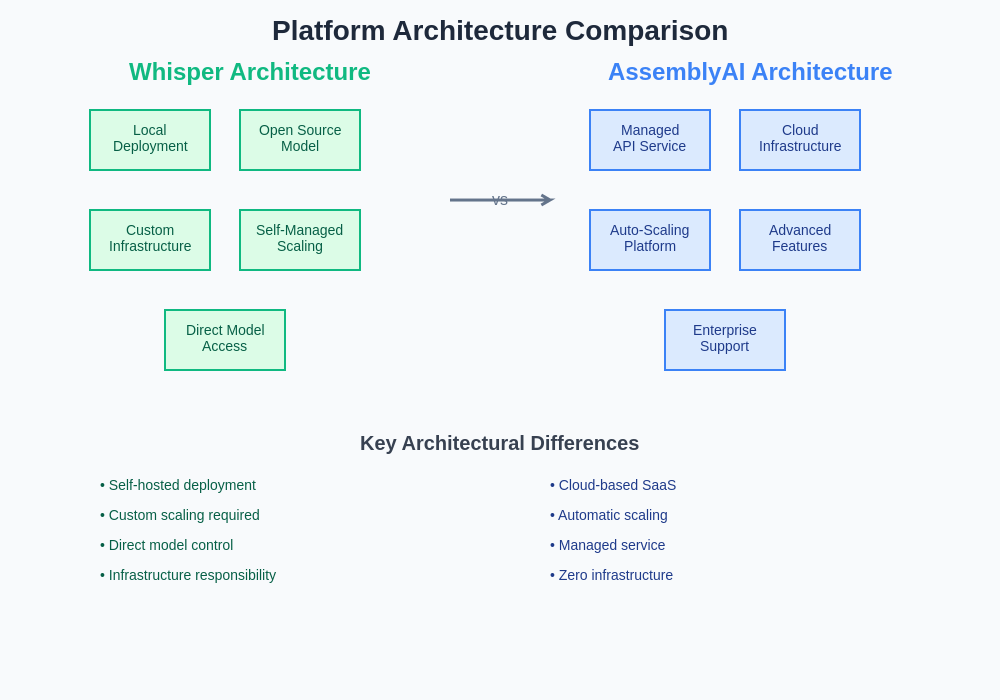
The architectural differences between Whisper and AssemblyAI reflect their distinct design philosophies and target use cases. Whisper’s modular, open-source architecture enables flexible deployment and customization, while AssemblyAI’s managed platform approach provides comprehensive features and simplified integration at the cost of reduced control over underlying infrastructure.
Pricing Models and Cost Analysis
The economic considerations for implementing speech-to-text solutions involve multiple factors beyond simple per-minute pricing, including infrastructure costs, development resources, and ongoing maintenance requirements. Whisper’s open-source model presents unique cost advantages for organizations with sufficient technical expertise and infrastructure capacity, as the primary costs involve computational resources and development time rather than per-usage fees. This model can result in significant cost savings for high-volume applications or organizations with existing machine learning infrastructure.
AssemblyAI’s pricing structure follows a traditional SaaS model with tiered pricing based on usage volume and feature requirements. This approach provides predictable costs and eliminates infrastructure management overhead, making it particularly attractive for organizations seeking to minimize technical complexity and focus on application development. The platform’s pricing includes access to advanced features and ongoing model improvements, which can provide substantial value for applications requiring sophisticated audio analysis capabilities.
Long-term cost considerations extend beyond immediate transcription expenses to include factors such as scaling costs, feature development, and maintenance requirements. Organizations using Whisper must account for ongoing infrastructure costs, model updates, and technical maintenance, while AssemblyAI users benefit from included platform maintenance but face potential vendor dependency and pricing escalation risks. The total cost of ownership analysis should consider these factors alongside immediate pricing differences.
Language Support and Multilingual Capabilities
Whisper’s multilingual capabilities represent one of its most significant advantages, with support for over 90 languages and robust performance across diverse linguistic contexts. The model’s training methodology has enabled it to handle code-switching, accented speech, and regional language variations with remarkable effectiveness. This broad language support makes Whisper particularly valuable for global applications, multilingual content processing, and accessibility solutions that serve diverse user populations.
AssemblyAI’s language support focuses primarily on English with high-quality performance, though the platform has been expanding its multilingual capabilities through targeted model development and partnerships. The platform’s strength lies in its deep understanding of English language nuances, including industry-specific terminology, colloquialisms, and contextual understanding that enhances transcription accuracy for English-language content. Recent platform updates have introduced support for additional languages, though coverage remains more limited compared to Whisper’s comprehensive multilingual approach.
The choice between platforms often depends heavily on language requirements, with Whisper being the clear choice for multilingual applications while AssemblyAI may provide superior performance for English-focused use cases. Organizations serving global markets or processing diverse language content typically find Whisper’s broad language support essential, while English-centric applications may benefit from AssemblyAI’s specialized English-language optimization and advanced features.
Enhance your research capabilities with Perplexity to stay informed about evolving language support and international speech recognition developments that impact global application deployment strategies. The rapid evolution of multilingual speech recognition capabilities continues to reshape possibilities for international communication and accessibility solutions.
Advanced Features and Audio Intelligence
The feature ecosystem surrounding each platform reveals fundamental differences in their value propositions and target markets. Whisper’s feature set focuses primarily on core transcription capabilities with excellent multilingual support, timestamp accuracy, and robust handling of challenging audio conditions. The platform’s strength lies in its foundational transcription quality and flexibility for custom implementation rather than providing extensive built-in audio analysis features.
AssemblyAI’s comprehensive feature suite extends far beyond basic transcription to include speaker diarization, sentiment analysis, content moderation, topic detection, and entity recognition. These advanced capabilities transform raw audio transcription into structured, actionable insights that can drive business intelligence, content analysis, and automated decision-making processes. The platform’s continuous development of new features and integration capabilities positions it as a comprehensive audio intelligence solution rather than simply a transcription service.
Feature richness considerations must be balanced against implementation complexity and specific use case requirements. Applications requiring basic transcription functionality may find Whisper’s streamlined approach more appropriate, while those needing sophisticated audio analysis capabilities often benefit significantly from AssemblyAI’s comprehensive feature set. The decision should align with both current requirements and anticipated future needs as applications evolve and expand their audio processing capabilities.
Real-Time Processing and Streaming Capabilities
Real-time speech recognition requirements present distinct challenges and opportunities for both platforms, with different strengths and limitations that impact their suitability for various applications. Whisper’s real-time capabilities depend heavily on implementation approach and computational resources, with the ability to achieve low-latency processing through optimized deployment configurations and appropriate model size selection. The platform’s flexibility enables custom optimization for specific real-time requirements, though this typically requires significant technical expertise and infrastructure investment.
AssemblyAI’s real-time transcription capabilities are built into the platform’s core offering, providing optimized streaming recognition with minimal latency and robust handling of network conditions and audio quality variations. The platform’s managed infrastructure approach ensures consistent performance and reliability for real-time applications without requiring extensive optimization effort from development teams. This managed approach to real-time processing can significantly reduce implementation complexity while providing enterprise-grade reliability.
The choice between platforms for real-time applications often depends on technical requirements, development resources, and performance expectations. Applications requiring maximum customization and control over real-time processing may benefit from Whisper’s flexibility, while those prioritizing rapid implementation and reliable performance often find AssemblyAI’s managed real-time capabilities more suitable for production deployment.
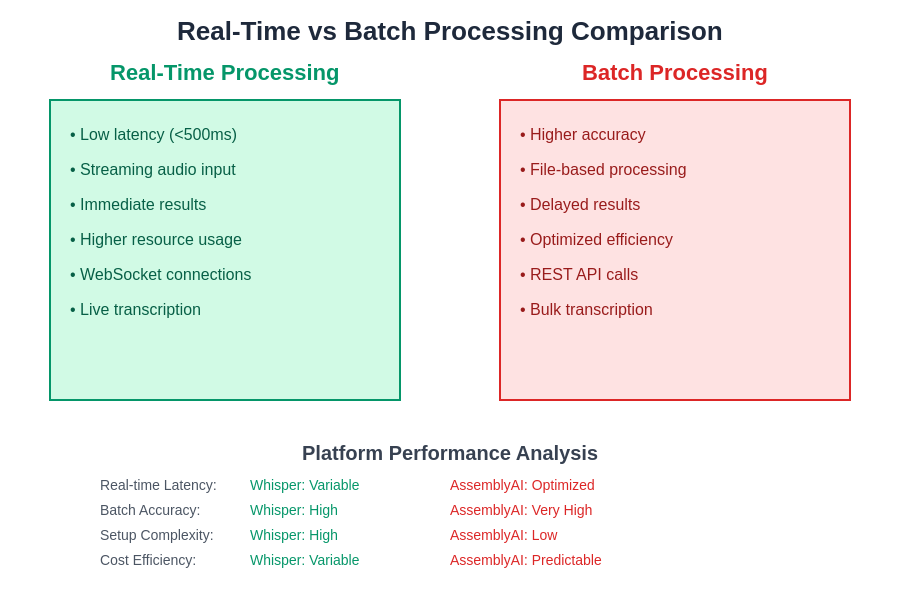
The processing architecture comparison highlights how each platform handles different types of audio processing workflows. Understanding these differences is crucial for selecting the appropriate platform based on specific application requirements and performance expectations.
Security and Privacy Considerations
Data security and privacy requirements play increasingly critical roles in platform selection decisions, particularly for applications handling sensitive audio content or operating in regulated industries. Whisper’s open-source nature and local deployment capabilities provide maximum control over data handling and security implementation, enabling organizations to maintain complete custody of audio data and transcription results. This approach is particularly valuable for applications handling confidential information, personal data, or content subject to strict regulatory compliance requirements.
AssemblyAI implements comprehensive security measures including encryption in transit and at rest, access controls, and compliance certifications that meet enterprise security requirements. The platform’s managed approach to security reduces implementation complexity while providing professional-grade protection for audio data and transcription results. However, this managed approach requires trust in the platform’s security implementation and may not be suitable for organizations with strict data sovereignty requirements.
Privacy considerations extend beyond technical security measures to include data retention policies, usage analytics, and potential model training implications. Organizations must carefully evaluate how each platform handles audio data, whether content is used for model improvement, and what controls are available for data lifecycle management. These considerations often prove decisive for applications in healthcare, legal, financial, and other sensitive domains where data handling requirements are strictly regulated.
Use Case Suitability and Recommendations
The optimal platform choice depends heavily on specific use case requirements, technical constraints, and organizational priorities that extend beyond simple feature comparisons. Whisper excels in scenarios requiring multilingual support, local deployment, custom implementation, or applications where open-source flexibility provides strategic advantages. These use cases include global applications, accessibility solutions, research projects, and organizations with existing machine learning infrastructure and expertise.
AssemblyAI’s strengths align with business-focused applications requiring comprehensive audio intelligence, rapid implementation, and ongoing platform support. The platform particularly excels in customer service analytics, media processing, meeting transcription, and enterprise applications where advanced features and managed infrastructure provide significant value. Organizations prioritizing time-to-market, feature richness, and reduced technical complexity often find AssemblyAI’s comprehensive approach more suitable for their requirements.
Hybrid approaches that leverage both platforms for different aspects of audio processing represent an increasingly viable strategy for organizations with diverse requirements. This approach might involve using Whisper for multilingual content processing while leveraging AssemblyAI for English-language business intelligence applications, providing optimized solutions for different use case categories within the same organization.
Development Experience and Documentation
The developer experience differs significantly between platforms, reflecting their distinct approaches to platform design and user support. Whisper’s open-source nature provides extensive community resources, research papers, and implementation examples that enable deep understanding and customization. However, this approach requires more technical expertise and investment in understanding the underlying technology for optimal implementation.
AssemblyAI prioritizes developer experience through comprehensive documentation, intuitive APIs, extensive SDKs, and responsive support channels. The platform’s focus on ease of use and rapid integration enables developers to achieve functional implementations quickly while providing advanced configuration options for complex requirements. This approach reduces barriers to entry and accelerates development timelines for most applications.
Community support and ecosystem development present different advantages for each platform. Whisper benefits from a vibrant open-source community contributing improvements, extensions, and implementation guidance, while AssemblyAI provides professional support channels and regular platform updates that ensure consistent performance and feature evolution. The choice between community-driven and commercially-supported development often influences long-term platform viability and support expectations.
Performance Optimization and Scaling Strategies
Optimization strategies for speech-to-text implementations vary significantly between platforms, requiring different approaches to achieve optimal performance and cost-effectiveness. Whisper optimization focuses on model selection, computational resource allocation, and custom preprocessing pipelines that can be tailored to specific audio characteristics and performance requirements. This flexibility enables highly optimized implementations but requires significant technical expertise and ongoing optimization effort.
AssemblyAI’s managed optimization approach handles performance tuning automatically while providing configuration options for specific use case requirements. The platform’s infrastructure optimization and automatic scaling capabilities reduce management overhead while ensuring consistent performance across varying load conditions. This managed approach simplifies scaling considerations but may limit optimization opportunities for specialized requirements.
Scaling considerations encompass both technical performance and economic efficiency as usage volumes increase. Whisper’s scaling economics depend heavily on infrastructure costs and optimization effectiveness, potentially offering significant cost advantages at high volumes with appropriate technical implementation. AssemblyAI’s scaling approach provides predictable performance and costs but may become expensive at very high volumes compared to optimized self-hosted solutions.
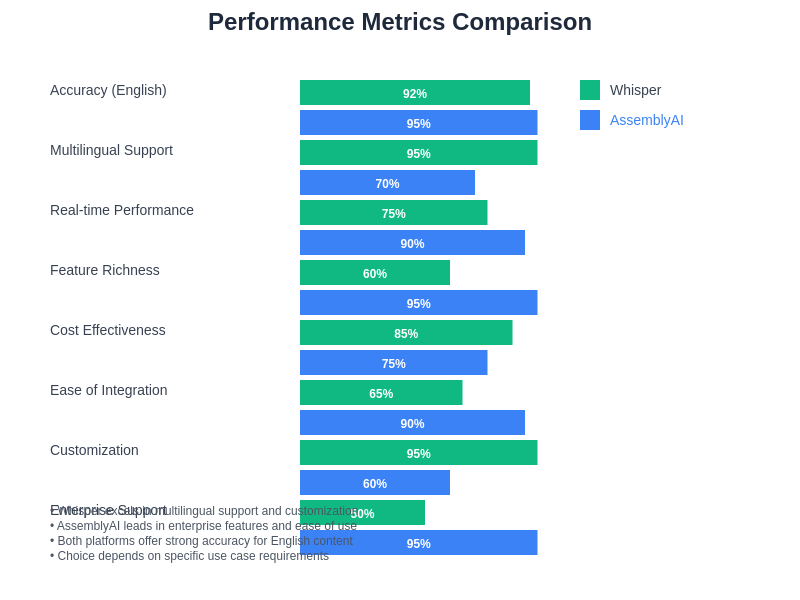
The comprehensive performance analysis demonstrates how each platform excels in different areas and use case scenarios. Understanding these performance characteristics enables informed decision-making based on specific application requirements and constraints.
Future Roadmap and Technology Evolution
The future development trajectories of both platforms reflect their distinct strategic priorities and market positioning, with implications for long-term technology adoption decisions. Whisper’s evolution benefits from OpenAI’s continued research investment and the open-source community’s contributions, focusing on improved accuracy, expanded language support, and enhanced model efficiency. The platform’s research-driven development approach ensures continued advancement in core speech recognition capabilities.
AssemblyAI’s roadmap emphasizes expanding audio intelligence capabilities, improving real-time processing performance, and developing specialized features for vertical markets. The platform’s commercial focus drives feature development based on customer needs and market opportunities, resulting in practical enhancements that address real-world business requirements. This approach ensures continued relevance for business applications while expanding platform capabilities.
Technology trend considerations include emerging standards for speech recognition, integration with other AI capabilities, and evolving privacy regulations that may impact platform selection and implementation strategies. Organizations must consider how each platform’s development approach aligns with their long-term technology strategy and anticipated requirement evolution. The choice between research-driven open-source development and commercially-focused platform evolution often influences long-term strategic alignment and investment protection.
The convergence of speech recognition with other AI capabilities such as natural language understanding, translation, and content analysis presents opportunities for enhanced application functionality that may influence platform selection decisions. Understanding how each platform approaches these integration opportunities provides insight into future capability development and strategic positioning within the broader AI ecosystem.
Conclusion and Strategic Recommendations
The decision between Whisper and AssemblyAI ultimately depends on a comprehensive evaluation of technical requirements, organizational capabilities, and strategic priorities that extend beyond simple feature comparisons. Whisper’s open-source flexibility and multilingual capabilities make it ideal for organizations with technical expertise seeking maximum control and customization, while AssemblyAI’s comprehensive features and managed approach provide excellent value for business-focused applications prioritizing rapid implementation and advanced audio intelligence.
Successful platform selection requires careful consideration of both immediate requirements and long-term strategic objectives, including scalability needs, feature evolution expectations, and organizational capacity for technical implementation and maintenance. The most effective approach often involves pilot implementations that evaluate real-world performance with actual audio content and use case requirements rather than relying solely on theoretical comparisons.
The rapidly evolving landscape of speech recognition technology ensures that platform capabilities will continue advancing, making it essential to consider not only current features but also development trajectories and strategic alignment with organizational goals. Whether choosing Whisper’s flexible open-source approach or AssemblyAI’s comprehensive managed platform, success depends on thoughtful implementation that leverages each platform’s unique strengths while addressing specific application requirements and constraints.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The comparison is based on publicly available information and general industry knowledge. Readers should conduct their own evaluation and testing to determine the most suitable speech-to-text solution for their specific requirements. Performance characteristics, pricing, and features may vary based on specific use cases and implementation details. Organizations should consider their specific technical, security, and business requirements when selecting speech-to-text platforms.