The convergence of artificial intelligence and embedded systems has reached a pivotal moment with the emergence of Zephyr RTOS as a leading platform for deploying machine learning capabilities on resource-constrained connected devices. This revolutionary real-time operating system has transformed the landscape of edge computing by enabling sophisticated AI inference directly on microcontrollers and IoT devices that were previously considered too limited for such advanced computational tasks. The integration of lightweight machine learning frameworks with Zephyr’s robust real-time capabilities has opened unprecedented opportunities for intelligent edge devices that can process data locally while maintaining the stringent timing requirements essential for embedded applications.
Explore the latest AI developments in embedded systems to understand how edge AI is revolutionizing IoT applications across industries. The marriage of real-time operating systems and machine learning represents a fundamental shift toward distributed intelligence that brings computational capabilities closer to data sources while reducing latency and improving privacy in connected device ecosystems.
Understanding Zephyr RTOS Architecture for AI Workloads
Zephyr RTOS represents a paradigm shift in embedded operating system design, specifically engineered to accommodate the diverse requirements of modern connected devices while providing robust support for machine learning workloads. The architecture of Zephyr has been meticulously crafted to balance real-time performance constraints with the computational demands of AI inference, creating a platform that can efficiently manage both traditional embedded tasks and sophisticated machine learning operations within the same system context.
The modular design philosophy underlying Zephyr RTOS enables developers to selectively include only the components necessary for their specific AI applications, resulting in optimized memory footprints that maximize the available resources for machine learning inference. This architectural approach is particularly crucial for edge AI applications where every kilobyte of memory and every processor cycle must be carefully allocated to achieve optimal performance within the severe resource constraints typical of embedded systems.
The kernel architecture of Zephyr incorporates advanced scheduling mechanisms that can prioritize real-time tasks while ensuring that machine learning inference operations receive adequate computational resources without compromising system responsiveness. This delicate balance is achieved through sophisticated priority inheritance protocols and deadline-aware scheduling algorithms that understand the temporal requirements of both control-critical embedded functions and AI inference pipelines.
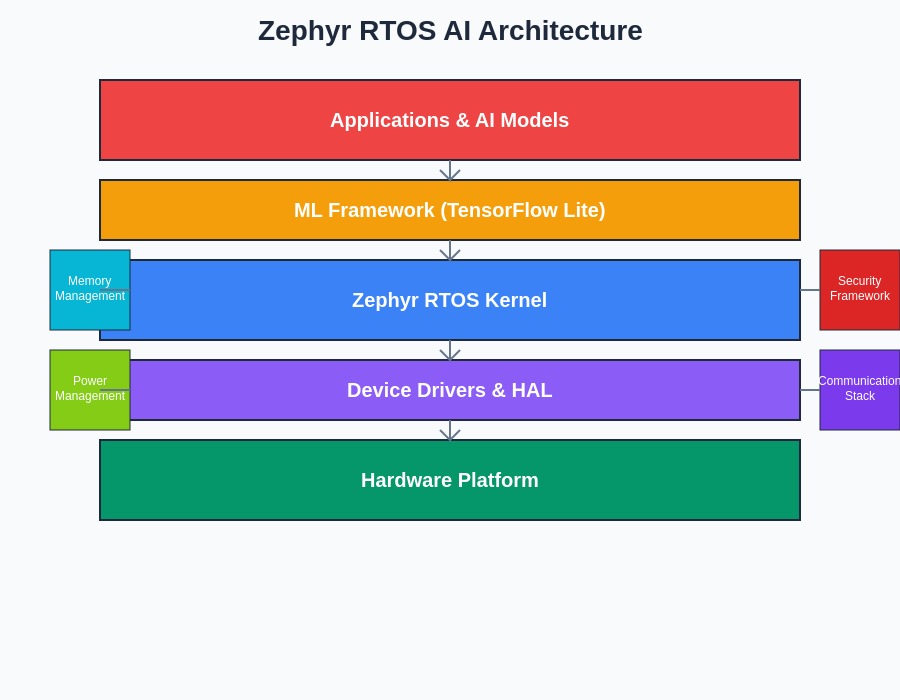
The layered architecture of Zephyr RTOS provides a robust foundation for integrating machine learning capabilities while maintaining strict separation between system components. This architectural approach enables efficient resource management and ensures that AI operations can coexist with traditional embedded functions without compromising real-time performance guarantees.
Machine Learning Framework Integration
The integration of machine learning frameworks with Zephyr RTOS has been accomplished through carefully designed abstraction layers that provide standardized interfaces for various AI inference engines while maintaining the real-time guarantees essential for embedded applications. TensorFlow Lite for Microcontrollers has emerged as a primary choice for many Zephyr-based AI implementations, offering optimized neural network inference capabilities specifically designed for resource-constrained environments.
The framework integration process involves sophisticated memory management techniques that enable dynamic allocation of computational resources between traditional embedded tasks and machine learning inference operations. This dynamic resource allocation is implemented through advanced memory pool management systems that can rapidly reconfigure available memory based on the current operational requirements of the system, ensuring optimal utilization of limited resources.
Discover advanced AI capabilities with Claude for developing sophisticated machine learning models that can be efficiently deployed on Zephyr RTOS platforms. The optimization process for deploying machine learning models on Zephyr involves multiple stages of model compression, quantization, and architectural adaptation to ensure that complex neural networks can operate effectively within the constraints of embedded hardware platforms.
TinyML and Edge Inference Optimization
The emergence of TinyML as a specialized discipline within machine learning has been instrumental in enabling AI capabilities on Zephyr RTOS platforms. TinyML focuses specifically on developing machine learning algorithms and models that can operate effectively within the severe resource constraints typical of embedded systems, often requiring models to function with less than 1MB of memory and minimal computational overhead.
Optimization techniques for TinyML deployment on Zephyr include advanced quantization strategies that reduce model precision from 32-bit floating-point to 8-bit or even lower bit-width representations without significantly compromising inference accuracy. These quantization approaches are implemented through sophisticated calibration processes that analyze the statistical properties of model weights and activations to determine optimal quantization parameters for each layer of the neural network.
Model pruning represents another critical optimization technique that removes redundant or minimally contributing parameters from neural networks, significantly reducing memory requirements and computational complexity while maintaining acceptable levels of inference accuracy. The pruning process involves iterative analysis of parameter importance and careful removal of weights that contribute minimally to overall model performance, resulting in sparse network architectures that are ideally suited for embedded deployment.

The performance advantages of Zephyr RTOS for TinyML applications are substantial across all critical metrics including inference latency, memory usage, power consumption, and real-time compliance. These improvements enable the deployment of sophisticated AI capabilities on resource-constrained devices that were previously unable to support machine learning workloads.
Real-Time Performance Considerations
The deployment of machine learning capabilities on real-time systems presents unique challenges that require careful consideration of temporal constraints and deterministic behavior requirements. Zephyr RTOS addresses these challenges through sophisticated scheduling mechanisms that can guarantee worst-case execution times for critical system functions while accommodating the variable execution times typical of machine learning inference operations.
Real-time AI inference on Zephyr platforms requires careful analysis of inference pipeline latency and the implementation of deadline-aware scheduling strategies that ensure machine learning operations do not interfere with time-critical system functions. This analysis involves detailed profiling of inference execution times across various input scenarios to establish reliable worst-case bounds that can be used for real-time scheduling decisions.
The integration of AI inference with real-time constraints often necessitates the implementation of approximate computing techniques that trade off inference accuracy for improved temporal predictability. These techniques include early termination strategies for iterative algorithms, adaptive precision control that adjusts computational complexity based on available time budgets, and hierarchical inference approaches that provide progressively refined results as computational resources become available.
Memory Management and Resource Optimization
Efficient memory management represents one of the most critical aspects of deploying machine learning capabilities on Zephyr RTOS platforms. The severely constrained memory resources typical of embedded systems require sophisticated allocation strategies that can dynamically balance the memory requirements of neural network models, intermediate computation buffers, and traditional embedded system functions.
Zephyr implements advanced memory pool management systems that enable efficient allocation and deallocation of memory resources for machine learning operations while maintaining the deterministic behavior required for real-time applications. These memory management systems incorporate techniques such as memory pooling, buffer recycling, and intelligent garbage collection that minimize memory fragmentation and ensure predictable memory allocation behavior.
The optimization of memory usage for AI inference involves careful analysis of model architecture and the implementation of memory-efficient computation strategies such as in-place operations, weight sharing, and dynamic allocation of intermediate computation buffers. These techniques enable the deployment of sophisticated neural network models on platforms with extremely limited memory resources while maintaining acceptable levels of inference performance.
Enhance your research capabilities with Perplexity to explore advanced memory optimization techniques for embedded machine learning applications. The development of memory-efficient AI algorithms requires deep understanding of both neural network architectures and embedded system constraints, necessitating interdisciplinary expertise that spans machine learning, computer architecture, and real-time systems design.
Power Efficiency and Energy Management
Power consumption represents a critical constraint for many connected devices that rely on battery power or energy harvesting systems. The deployment of machine learning capabilities on these devices requires careful consideration of energy efficiency and the implementation of sophisticated power management strategies that can extend operational lifetime while maintaining AI functionality.
Zephyr RTOS incorporates advanced power management frameworks that can dynamically adjust system performance based on available energy resources and operational requirements. These frameworks include support for multiple power states, dynamic frequency scaling, and intelligent task scheduling that minimizes energy consumption while meeting performance requirements for both traditional embedded functions and machine learning inference.
Energy-efficient AI inference on Zephyr platforms involves the implementation of specialized neural network architectures that minimize computational complexity and memory access patterns that consume significant energy. These architectures include depthwise separable convolutions, efficient attention mechanisms, and specialized activation functions that reduce the overall energy footprint of machine learning operations.
The development of energy-aware machine learning algorithms requires sophisticated modeling of energy consumption across different computational operations and the implementation of adaptive algorithms that can adjust their computational complexity based on available energy budgets. This approach enables the creation of AI systems that can operate effectively across a wide range of energy availability scenarios while maintaining acceptable levels of inference performance.
Sensor Integration and Data Processing
The integration of various sensor modalities with Zephyr RTOS AI systems requires sophisticated data processing pipelines that can efficiently convert raw sensor data into formats suitable for machine learning inference. This integration involves the implementation of specialized device drivers, signal processing algorithms, and data fusion techniques that can operate within the resource constraints of embedded systems.
Sensor data preprocessing for AI applications often involves computationally intensive operations such as filtering, feature extraction, and normalization that must be implemented efficiently to avoid overwhelming the limited computational resources of embedded platforms. Zephyr provides optimized libraries and frameworks for common signal processing operations that enable efficient implementation of these preprocessing pipelines.
The temporal aspects of sensor data processing require careful consideration of sampling rates, buffering strategies, and synchronization mechanisms that ensure consistent data quality for machine learning inference. Zephyr’s real-time capabilities enable precise control over sensor sampling timing and the implementation of sophisticated buffering strategies that minimize latency while ensuring data integrity.
Multi-sensor fusion represents an advanced capability that combines data from multiple sensor modalities to improve the accuracy and robustness of AI inference systems. The implementation of sensor fusion on Zephyr platforms requires sophisticated algorithms that can efficiently combine heterogeneous data sources while managing the computational complexity and memory requirements associated with multi-modal data processing.
Security and Privacy in Edge AI
The deployment of machine learning capabilities on connected devices introduces significant security and privacy considerations that must be addressed through comprehensive security frameworks integrated with Zephyr RTOS. These security requirements include protection of machine learning models from unauthorized access, ensuring the integrity of inference results, and implementing privacy-preserving techniques that protect sensitive data processed by AI systems.
Zephyr incorporates robust security frameworks that provide hardware-based security features, secure boot mechanisms, and encrypted communication protocols that protect AI systems from various attack vectors. These security features are particularly important for edge AI applications that process sensitive data or make critical decisions based on machine learning inference results.
Privacy-preserving machine learning techniques such as federated learning and differential privacy can be implemented on Zephyr platforms to enable AI capabilities while protecting user privacy. These techniques require sophisticated algorithms that can train machine learning models without exposing sensitive training data, enabling the development of intelligent systems that respect user privacy while providing valuable AI-powered functionality.
The implementation of secure AI inference on Zephyr platforms involves the use of trusted execution environments, secure key management systems, and encrypted model storage that protect machine learning models and inference data from unauthorized access. These security measures are essential for applications that involve sensitive data or critical decision-making processes that could be compromised by malicious attacks.
Communication Protocols and Connectivity
Modern connected devices require sophisticated communication capabilities that enable seamless integration with cloud services, other edge devices, and centralized management systems. Zephyr RTOS provides comprehensive support for various communication protocols including Wi-Fi, Bluetooth, LoRaWAN, and cellular connectivity that enable AI-powered devices to participate in larger IoT ecosystems.
The integration of machine learning capabilities with communication protocols requires careful consideration of bandwidth limitations, latency requirements, and energy consumption associated with data transmission. Zephyr implements optimized communication stacks that can efficiently manage network resources while supporting both real-time communication requirements and AI-related data transfer needs.
Edge AI systems often require hybrid architectures that combine local inference capabilities with cloud-based model training and updating mechanisms. Zephyr provides frameworks for implementing these hybrid architectures through efficient model synchronization protocols, incremental update mechanisms, and intelligent caching strategies that minimize communication overhead while ensuring that edge devices have access to the latest machine learning models.
The implementation of mesh networking capabilities on Zephyr platforms enables the creation of distributed AI systems where multiple edge devices can collaborate to perform complex machine learning tasks. These mesh networks require sophisticated coordination protocols that can efficiently distribute computational tasks while managing communication overhead and ensuring reliable data transmission across the network.
Development Tools and Debugging
The development of AI applications for Zephyr RTOS requires specialized tools and debugging capabilities that can effectively manage the complexity of combining real-time embedded systems with machine learning functionality. Zephyr provides comprehensive development environments that include simulators, debuggers, and profiling tools specifically designed for AI application development.
Model deployment and optimization tools enable developers to efficiently convert machine learning models trained in popular frameworks into formats optimized for Zephyr platforms. These tools include automated quantization pipelines, model compression utilities, and performance analysis frameworks that help developers optimize their AI implementations for specific hardware platforms and application requirements.
Debugging AI applications on embedded platforms presents unique challenges due to the limited visibility into system state and the complex interactions between real-time tasks and machine learning inference operations. Zephyr provides specialized debugging tools that can monitor AI inference performance, analyze memory usage patterns, and identify potential real-time constraint violations that could affect system reliability.
Performance profiling tools for Zephyr AI applications enable detailed analysis of computational bottlenecks, memory access patterns, and energy consumption characteristics that are essential for optimizing AI implementations. These tools provide developers with detailed insights into system behavior that enable informed optimization decisions and help identify opportunities for improving overall system performance.
Industry Applications and Use Cases
The deployment of Zephyr RTOS AI systems spans diverse industry sectors including industrial automation, healthcare monitoring, smart agriculture, and environmental sensing. Each application domain presents unique requirements and constraints that require specialized optimization strategies and careful consideration of performance, reliability, and security requirements.
Industrial automation applications leverage Zephyr AI capabilities for predictive maintenance, quality control, and process optimization that require real-time decision-making based on machine learning inference. These applications often involve harsh environmental conditions and strict reliability requirements that demand robust AI implementations capable of operating continuously under challenging conditions.
Healthcare monitoring systems utilize Zephyr RTOS AI for continuous patient monitoring, early warning systems, and personalized treatment recommendations that require both high accuracy and strict privacy protection. These applications involve processing sensitive medical data and making critical decisions that directly impact patient health, necessitating comprehensive validation and regulatory compliance procedures.
Smart agriculture implementations deploy Zephyr AI systems for crop monitoring, precision irrigation, and pest detection that require long-term autonomous operation with minimal maintenance. These systems often operate in remote locations with limited connectivity and power resources, requiring sophisticated energy management and communication optimization strategies.
Environmental sensing applications utilize Zephyr RTOS AI for air quality monitoring, climate analysis, and pollution detection that require high-precision measurements and reliable data collection over extended periods. These implementations often involve large-scale deployments with hundreds or thousands of interconnected devices that require coordinated operation and efficient data management strategies.
Future Developments and Emerging Trends
The future evolution of Zephyr RTOS AI capabilities will likely focus on enhanced integration with emerging machine learning paradigms such as neuromorphic computing, quantum-inspired algorithms, and bio-inspired neural networks that could provide significant advantages for edge AI applications. These emerging approaches promise to deliver improved energy efficiency, enhanced learning capabilities, and novel computational paradigms that could revolutionize embedded AI systems.
Advances in hardware accelerators specifically designed for edge AI applications will enable more sophisticated machine learning capabilities on Zephyr platforms while maintaining the power efficiency and real-time performance characteristics essential for embedded applications. These hardware developments include specialized neural processing units, in-memory computing architectures, and adaptive computing platforms that can dynamically reconfigure based on application requirements.
The integration of Zephyr RTOS with emerging communication technologies such as 5G, satellite connectivity, and advanced mesh networking protocols will enable new classes of AI applications that can leverage both edge intelligence and cloud resources more effectively. These communication advances will facilitate the development of more sophisticated hybrid AI architectures that can adapt to changing connectivity conditions and resource availability.
The continued development of automated machine learning tools and model optimization techniques will further democratize AI development for Zephyr platforms, enabling developers with limited machine learning expertise to create sophisticated AI-powered embedded systems. These tools will incorporate advanced automation capabilities that can optimize models for specific hardware platforms and application requirements with minimal manual intervention.
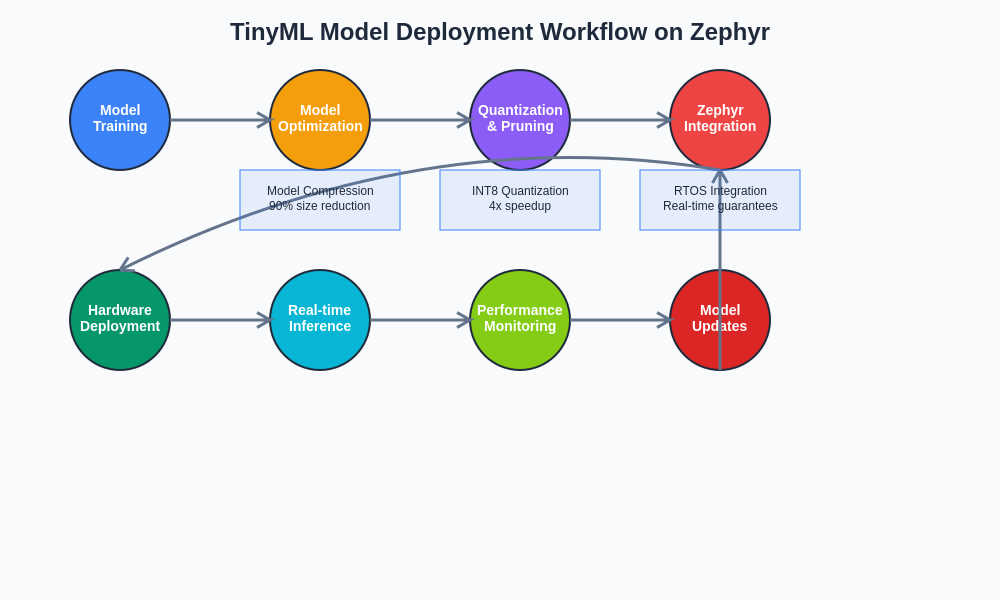
The comprehensive deployment workflow for TinyML on Zephyr RTOS encompasses every stage from initial model training through production deployment and ongoing maintenance. This systematic approach ensures optimal performance and reliability while enabling continuous improvement through feedback loops and model updates.
Conclusion and Strategic Implications
The integration of machine learning capabilities with Zephyr RTOS represents a transformative development in embedded systems that enables unprecedented levels of intelligence and autonomy in connected devices. This convergence of real-time operating systems and artificial intelligence creates new opportunities for developing sophisticated edge AI applications while maintaining the reliability, predictability, and efficiency requirements essential for embedded systems.
The strategic implications of Zephyr RTOS AI extend beyond technical capabilities to encompass broader trends toward distributed intelligence, edge computing, and autonomous systems that could fundamentally reshape how we interact with technology. The ability to deploy sophisticated AI capabilities on resource-constrained devices enables new paradigms of human-computer interaction and opens possibilities for ambient intelligence that seamlessly integrates with our daily lives.
The continued evolution of Zephyr RTOS AI capabilities will likely play a crucial role in addressing some of the most pressing challenges facing connected device ecosystems, including privacy protection, energy efficiency, and system reliability. The development of robust, efficient, and secure AI-powered embedded systems will be essential for realizing the full potential of IoT technologies while addressing the concerns and requirements of users, regulators, and industry stakeholders.
Disclaimer
This article is for informational purposes only and does not constitute professional advice. The views expressed are based on current understanding of Zephyr RTOS and embedded machine learning technologies. Readers should conduct their own research and consider their specific requirements when implementing AI capabilities on embedded platforms. The effectiveness and suitability of AI implementations may vary depending on specific hardware platforms, application requirements, and regulatory constraints.